
教師なし学習
概要
学習で用いるデータに教師ラベルがなく、入力データそのものが持つ構造・特徴が対象となる手法。
データそのものが持つ構造・特徴を見つけることを目的に学習を行う。
ex.)1⃣ECサイトの売上データから、どういった顧客層があるのかを認識する。
ex.)2⃣入力データの各項目間にある関係性を把握する。
教師あり学習のように、数多くの代表的な手法が存在する。
教師あり学習との違い
教師あり学習は入力と出力がセットとなったデータを扱うのに対し、教師なし学習では学習に用いるデータに出力が存在しない。(「正解ラベル」の有無)
k-means法
元のデータからk個のグループに分け、それぞれをまとめてグループ構造を見つけ出すこと。
グループのことを正確にはクラスタと言い、k-means法を用いた分析のことをクラスタ分析と言う。
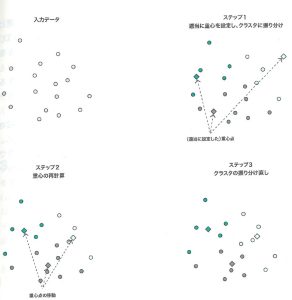
アプローチ
1.適当に各データをk個のクラスタに振り分ける。
2.各クラスタの重心を求める。
3.求まったk個の重心と各データとの距離を求め、各データを最も距離が近い重心に対応するクラスタに振り分け直す。
4.重心の位置が(ほぼ)変化しなくなるまで2、3を繰り返す。
これにより、最終的にk個のクラスタに分類される。
ウォード法
k-means法ではデータを別々のクラスタに並列に分類することが目的であったが、そこから更にクラスタの階層構造を求めるまで行う手法。
クラスター間の距離を定義する距離関数のひとつ。
最も距離が近い2つのデータ(クラスタ)を選択し、1つのデータにまとめる処理を繰り返す。

右図のような樹形図のことをデンドログラムと言う。デンドログラムをどの深さまで見るかによって、階層構造を分析するクラスタは変化することになる。
主成分分析
データの特徴量間の関係性、すなわち相関を分析することでデータの構造をつかむ手法。
特に特徴量の数が多い場合に用いられ、相関をもつ多数の特徴量から、相関のない少数の特徴量(主成分)へと次元削減することが主たる目的。
次元削減をすることで、学習にかかる時間を減らしたり、データを可視化することができる。
協調フィルタリング
多くのユーザの嗜好情報を定義、蓄積し、あるユーザと嗜好の類似した他のユーザの情報を用いて自動的に推論を行い、商品を推薦することができる。
レコメンデーションに用いられる手法の1つ。
コールドスタート問題
ただし、「他のユーザーの情報を参照する」ことからも、協調フィルタリングは事前にある程度の参考にできるデータがない限り、推薦を行うことはできない。
コンテンツベースフィルタリング
ユーザーではなく商品側に何かしらの特徴量を付与し、特徴が似ている商品を推薦する。
対象ユーザーのデータさえあれば推薦を行えるため、コールドスタート問題は回避できるが、他のユーザー情報を参照することができないため、協調フィルタリングより優れている、というわけではない。
トピックモデル
クラスタリングを行うモデルであり、複数のクラスタにデータを分類する。
文書データを対象とした際、各文書は「複数の潜在的なトピックから確率的に生成される」と仮定したモデルであり、各文書データ間の類似度も求められるため、レコメンドシステムに用いることができる。
ex.) ニュース記事を政治・経済・芸能・スポーツに分けようとした際に、どのトピックに分類されるかを記事内に出てくる単語からそれぞれ確率で求める。