本論文は、Meta の 最新畳み込みモデルである「 ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders 」 に関してまとめています。
基本情報
参照URL:https://arxiv.org/abs/2301.00808
PDF版は以下を参考下さい。
イントロダクション
事前学習された大規模な画像認識モデルは、特徴学習や様々な視覚アプリケーションを実現するための重要なツールとなっています。そして、そのシステムの性能は、ニューラルネットワークアーキテクチャの選択、ネットワークの学習方法、訓練データの3つの主要因に大きく影響されます。
ニューラルネットワークアーキテクチャの選択
ConvNetsは、様々な画像認識タスクに汎用的な特徴学習法を利用できるようになったことで、コンピュータビジョン研究に大きな影響を与えました。Transformer も、モデルやデータセットサイズに対する強力なスケーリング挙動により人気を博しています。さらに最近では、ConvNeXt アーキテクチャが従来の ConvNets を近代化し、畳み込みモデルもスケーラブルなアーキテクチャになり得ることを実証しています。しかし、ニューラルネットワークアーキテクチャの設計空間を探索する最も一般的な方法は、依然としてImageNet上での教師あり学習によるものです。
画像認識の学習の焦点は、教師あり学習から、自己教師あり事前学習へと移行しています。特に、Masked Autoencoders (MAE) は、急速に画像認識学習のための一般的なアプローチになりました。しかし、自己教師あり学習では、教師あり学習用に設計されたアーキテクチャを用い、デサインが固定されています。例えば、MAEはVision Transformerを用いて開発されています。アーキテクチャと自己教師あり学習フレームワークの設計要素を組み合わせることは可能ですが、ConvNeXtとMAEを併用する場合、困難な場合があります。
具体的には、以下の2点が挙げられます。
①MAEがTransformerのシーケンス処理能力に最適化された特定のエンコーダ・デコーダ設計を持っていることで、計算負荷の高いエンコーダが可視パッチに集中できるようになり、事前学習コストが削減されます。この設計は、高密度のスライディングウィンドウを使用する標準的な ConvNets とは相容れません。
②アーキテクチャと学習目的の関係を考慮しないと、最適な性能が得られるかどうかが不明確になります。
そのため、本論文ではConvNeXtモデルに対してマスクベースの自己教師あり学習を有効にし、ネットワークアーキテクチャとMAEを同一のフレームワークで設計することを検討しています。
2. 関連研究
ConvNets
1980年代に初めて導入され、バックプロパゲーションを用いて学習されたConvNetsの設計は、長年にわたり、最適化、精度、効率の面で多くの改善を受けてきました。これらの技術革新は、主にImageNetデータセットに対する教師あり学習を用いて発見されました。
ConvNeXt
ConvNet の設計空間を再検討したものです。Vision Transformer と同等の拡張性を持ちうることを示しました。特に複雑ではないシナリオで優れています。
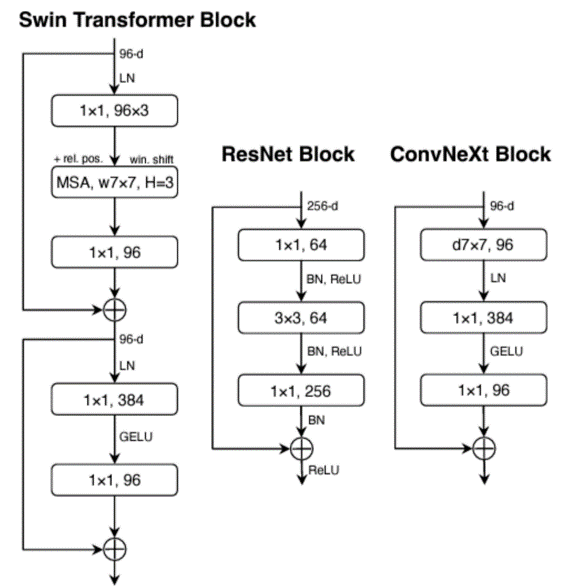
MAE(マスクドオートエンコーダ)
最新の自己教師あり学習の1つです。事前学習フレームワークとして、画像認識において幅広い影響を及ぼしています。しかし、オリジナルのMAEは、その非対称なエンコーダ・デコーダの設計により、ConvNetsに直接適用することができません。MCMAE はいくつかの畳み込みブロックを入力トークン化器として使用します。
エンコーダ
バッチに分割された入力画像の一部にランダムマスク処理を行い、マスクされていないパッチのみ入力します。
デコーダ
エンコードされたパッチトークンとマスクトークンを入力します。このマスクトークンは、学習可能なパラメータであり、全マスクトークンで共有されています。
マスクトークンは画像内の位置に関する情報を持たせるためにデコーダにおいても各トークンに位置埋め込みを行います。
従来のMAEの課題
MAEは、シーケンシャルなデータを処理するTransformer との組み合わせに最適に設計されているので、ConvNets と併用するには計算コストがかかり過ぎます。スライディングウィンドウの仕組みから ConvNets と相性の悪い設計になっている可能性があります。
ConvNeXt V2
そこでこれらの課題を解決し、提案されたのが本論文のConvNeXt V2です。マスクベースの自己教師あり学習を有効にし、Transformer を用いた場合と同様の結果を得ることを目的として、ネットワークアーキテクチャ と マスクドオートエンコーダを同一のフレームワークで設計することを提案しました。
ConvNeXt の様々な訓練構成について、特徴空間分析を行っています。
その結果、マスクされた入力に対して、直接 ConvNeXt を訓練した場合、特徴量の崩壊の可能性があることがわかりました。
⇒ グローバル応答正規化層(Grobal Response Normalization)
チャネル間特徴量の競合関係を強調しています。
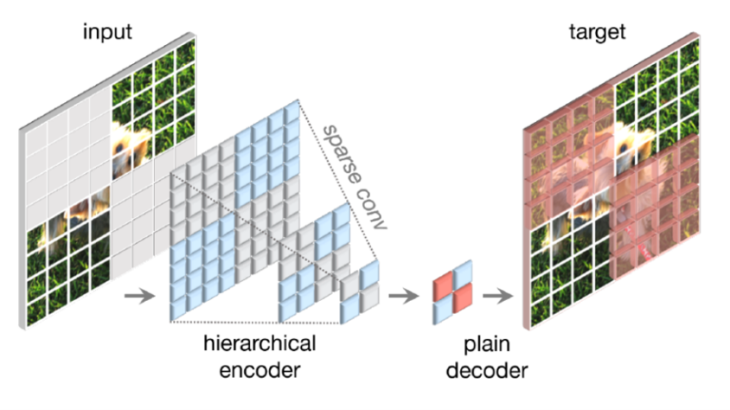
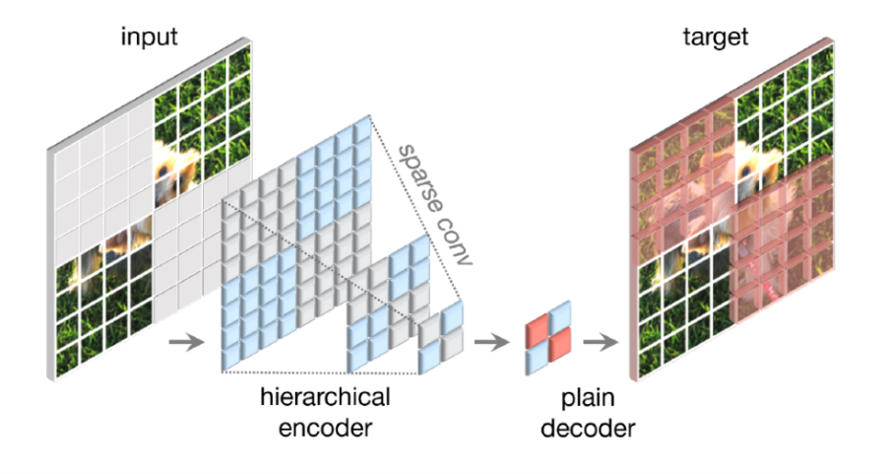
Fully Convolutional Masked Autoencoder(FCMAE)
FCMAEは sparse convolution に基づく ConvNeXt エンコーダと軽量の ConvNeXt ブロックデコーダから構成されます。このオートエンコーダのアーキテクチャは非対称です。エンコーダは可視画素のみを処理し、デコーダは符号化された画素とマスクトークンを用いて画像を再構成します。損失はマスクされた領域に対してのみ計算されます。
マスキング
32×32のパッチのうち、60%をランダムにマスキングします。畳み込みモデルは階層的に設計されています。異なるステージで特徴がダウンサンプリングされ、マスクは最終ステージで生成します。最も細かな解像度まで再帰的にアップサンプリングします。パッチを入力画像から抽出します。データ拡張は、最小限でランダムリサイズクロッピングのみです。
エンコーダの設計
ConvNeXt モデルをエンコーダとして使用します。マスク画像のモデリングの課題は、モデルがマスクされた領域から情報をコピー&ペーストできるようなショートカットを学習しないようにすることです。Transformer ベースのモデルでは、エンコーダへの入力として可視パッチを残すことができるため、比較的容易に実現でききます。しかし、ConvNets では、2次元の画像構造を保持する必要があるため、困難です。入力側に学習可能なマスクトークンを導入する方法は、事前学習の効率を下げ、テスト時にはマスクトークンが存在しないため、学習時とテスト時の矛盾が発生する。これは、特にマスキング率が高い場合に問題となります。
この問題に対して、3Dの sparse point clouds の 「sparse data perspective」における学習からヒントを得ました。マスクされた画像はピクセルの2次元空間における sparse 配列として表現できます。この洞察に基づき、sparse conv layer を取り入れます。実際には、事前学習中に、エンコーダの標準的な畳み込み層を、submanifold sparse convolutionに変換することを提案しています。これにより、モデルは可視データ点のみに対して動作することができます。
デコーダの設計
デコーダには軽量でプレーンな ConvNeXt ブロックを使用します。エンコーダがデコーダより重く、階層を持つため、全体として非対称なアーキテクチャを形成しています。階層型デコーダやTransformerなどのより複雑なデコーダも検討しましたが、より単純な単一 ConvNeXt ブロックデコーダはFine-turningの精度の面で良好で、事前学習時間を大幅に短縮しました。デコーダの次元は512に設定しています。

再構成対象
再構成された画像とターゲット画像の間の平均二乗誤差(MSE)を計算します。MAEと同様に、ターゲットは元の入力のパッチ単位で正規化した画像であり、損失はマスクされたパッチにのみ適用されます。
FCMAE
上記を組み合わせることで、Fully Convolutional Masked Autoencoder(FCMAE)を提案しました。ImageNet-1Kデータセットを用いて、それぞれ800エポックと100エポックの事前学習とFine-turningを行い、単一の224×224センタークロップに対するImageNet-1K検証のトップ1の精度を検証しています。
FCMAEのフレームワークでsparse conv layerを有無のパターンで比較し、 sparse conv layer の効果を実証しています。
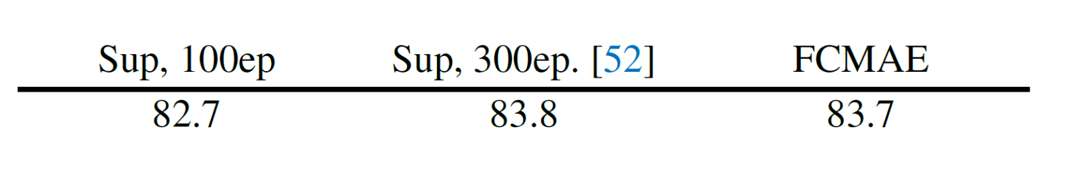
次に、教師あり学習と自己教師あり学習を比較しています。教師あり100エポックベースラインと、ConvNeXt のオリジナル論文で提供された300エポック教師あり学習ベースラインの2つのベースライン実験結果を得ました。その結果、FCMAEの事前学習はランダムなベースラインよりも良い初期化(すなわち、82.7 → 83.7)を提供しますが、オリジナルの教師あり設定で得られた最高の性能には劣ることがわかりました。
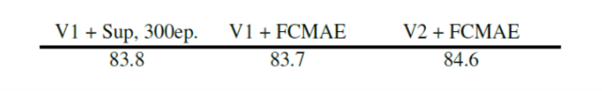
Global Response Normalization
ConvNeXtアーキテクチャと組み合わせてFCMAE事前学習をより効果的に行うための新しい技術 Global Response Normalization(GRN)を提案しています。
特徴崩壊(Feature collapse)
学習挙動をより深く理解するために、特徴空間における定性的な解析を行いました。FCMAEで事前学習したConvNeXt-Baseモデルの活性度を可視化したところ、消失したり、飽和した特徴マップが多く、活性度がチャネル間で冗長になっていました。この挙動は、主にConvNeXtブロックの次元拡張MLP層で観察されました。 暗いpatchは特徴量が消失しており、黄色のpatchは特徴量が飽和していることを示します。ConvNeXtV1-Baseのモデルは、特徴量の多くが消滅もしくは飽和しています。

Feature cosine distance の解析
活性化テンソル 𝑋 ∈ 𝑅^(𝐻 × 𝑊 × 𝐶)が与えられたとき、𝑋_𝑖 ∈ 𝑅^(𝐻×𝑊) は 𝑖 番目のチャネルの特徴マップです。これを 𝐻𝑊 次元ベクトルとして再形成し、チャンネル間の平均対コサイン距離を 以下で計算します。
距離の値が大きいほど、特徴の多様性が高いことを示し、小さいほど特徴の冗長性を示します。ImageNet-1K検証セットを用いて、FCMAE モデル、ConvNeXt 教師ありモデル、MAE事前学習済みViTモデルなどを比較しています。異なるモデルの各層から高次元特徴を抽出します。そして、各画像の層ごとの距離を計算し、全画像の値を平均化します。
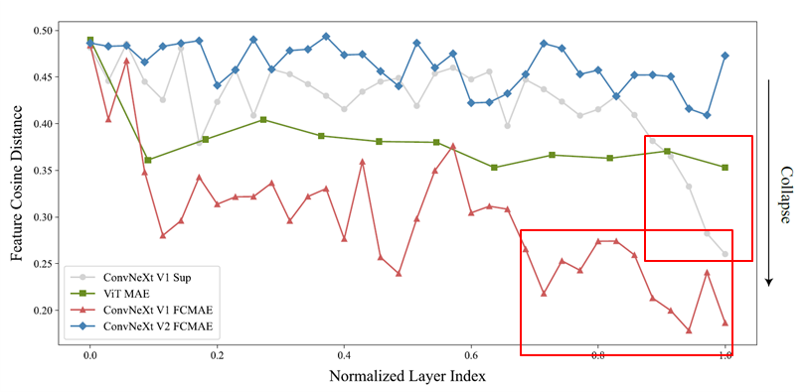
ConvNeXt V1 FCMAEの事前学習済みモデルは、特徴崩壊の挙動を示していることがわかります。教師ありモデルでは、特徴の多様性が減少していますが、最終層のみである。これは、クロスエントロピー損失を用いることで、クラス識別に有効な特徴量に着目し、それ以外の特徴量を抑制しているためと考えられます。
GRNのアプローチ
脳には、ニューロンの多様性を促進するメカニズムが数多く存在します。例えば、横方向の抑制は、活性化したニューロンの反応を鮮明にし、刺激に対する個々のニューロンのコントラストと選択性を高めると同時に、ニューロンの集団全体の反応の多様性を高めるのに役立ちます。
深層学習では、このような横方向の抑制は、Response Normalization によって実装することができます。本研究では、チャネルのコントラストと選択性を高めることを目的としたGlobal Response Normalization(GRN)と呼ばれる新しいレイヤーを導入します。入力特徴量 X ∈ 𝑅^(𝐻×𝑊×𝐶) が与えられると、提案するGRNユニットは3つのステップから構成されます。
1) Global Feature Aggregation
2) Feature Normalization
3) Feature Calibration
1)Global Feature Aggregation
まず、空間特徴マップ𝑋𝑖をグローバル関数 𝐺(・) でベクトル 𝑔𝑥 に集約します。
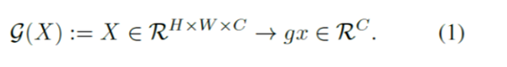
これは単純なプーリング層と見なすことができます。 特徴集約に広く用いられているGlobal average poolingは、うまく機能しませんでした。代わりに、ノルムベースの特徴集約、 具体的にはL2ノルムを用いると、 より良い性能になる ことが分かりました。

これにより、集約された値の集合 G(X) = gx が得られます。 G(X) = ||X|| は i番目のチャネルの統計量を集約したスカラーです。
G(X) = gx = {||X1||||X2||,…, ||Xcll}∈RC
2) Feature Normalization
次に、集計した値に対して、 response normalization 関数N() を適用します。
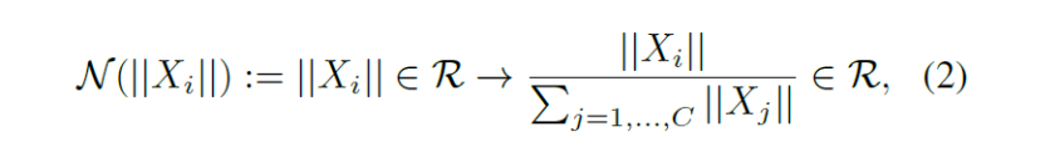
||X|は、番目のチャネルのL2ノルムです。他の正規化関数と比較し、単純な divisive normalization が最も効果的であることがわかりましたが、 標準化 (||X|-μ)/ を適用しても同様の結果が得られることが確認されました。
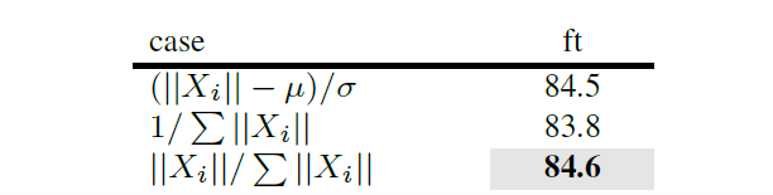
3) Feature Calibration
最後に、1)、2) で計算された特徴正規化スコアを用いて、元の入力応答をキャリブレーションします。
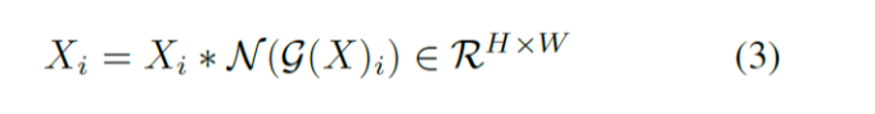
GRNユニットのコアは、たった3行のコードで実装でき、 学習可能なパラメータを持たないため、非常に簡単です。最適化を容易にするために、 2つの学習可能なパラメータ、および β を追加し、それらをゼロに初期化します。また、GRN 層の入力と出力の間に残差接続を追加します。 (残差ありの方が精度が高い。)
最終的なGRNブロックは Xi = Xi * N(G(X)i) + β + Xi となります。


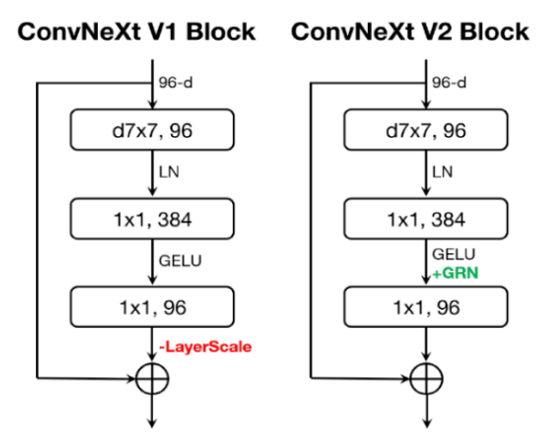
ConvNeXt V2 Block
ConvNeXtのオリジナルブロックにGRN層を組み込みます。GRNを適用すると LayerScale が不要になり、削除します。この新しいブロック設計を用いて、 ConvNeXt V2 モデルファミリーを作成します。軽量(例:Atto) から計算量の多いもの (例: Huge) まで多岐にわたっています。
GRNの効果
FCMAEフレームワークを用いてConvNeXt V2を事前学習させ、GRNの効果を評価しました。可視化とFeature cosine distanceから、コサイン距離の値は一貫して高く、層を超えて特徴の多様性が維持されており、ConvNeXt V2は特徴量崩壊の問題を効果的に軽減していることがわかります。
GRN を ローカル応答正規化(LRN)、バッチ正規化(BN)、レイヤー正規化(LN)と比較。
GRNのみが教師ありベースラインを上回ることができました。LRNは近傍のチャンネルを対比させるだけなので、グローバルなコンテキストを欠いています。BNはバッチ軸に沿って空間的に正規化しますが、これはマスクされた入力には適しません。LNはグローバルな平均と分散の標準化を通じて暗黙のうちに特徴の競合を促しますが、GRNほどには機能しません。
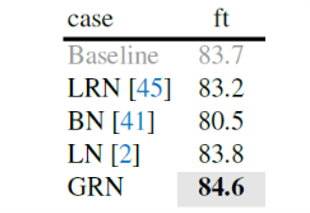
Fine-turning性能の評価
GRNを搭載したFCMAE事前学習モデルは、300エポックの教師ありモデルを超えることができます。
ImageNet 実験
ImageNet-1Kデータセット、ImageNet-22Kデータセットを用いて検証しました。
共同設計の重要性
自己教師あり学習フレームワーク(FCMAE)とモデルアーキテクチャの改良(GRN層)の両者の学習動作を検証しました。モデルアーキテクチャを変更せずにFCMAEフレームワークを用いても、性能への影響は限定的でした。同様に、新しいGRN層は教師ありの設定において、性能への影響がかなり小さいです。しかし、この2つを組み合わせることで、Fine-turningの性能が大幅に向上しました。
⇒特に自己教師あり学習に関しては、モデルと学習フレームワークの両方を一緒に考えるべき。と主張されています。
ConvNeXtでは、アーキテクチャと学習フレームワークを共同設計することで、マスク画像の事前学習が効果的に行われます。800エポックFCMAE事前学習したモデルのファインチューニング性能が右表です。モデルサイズが大きくなるほど、相対的な改善度は大きくなります。
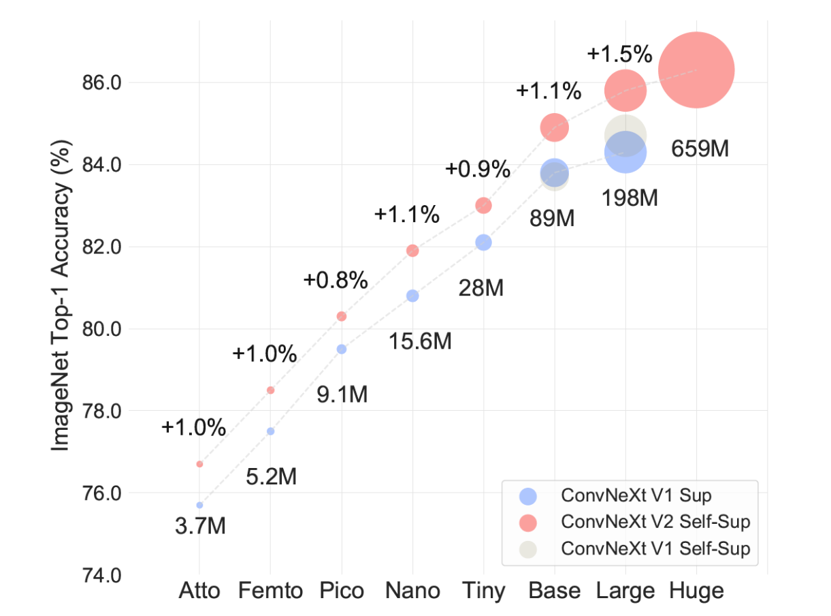
モデルのスケーリング
低容量の3.7M Attoモデルから高容量の650M Hugeモデルまで、サイズの異なる 8 種類のモデルを評価しました。これらのモデルに対して、FCMAEフレームワークを用いて事前学習を行い、教師ありのモデルと比較して、Fine-turningの結果を比較しました。その結果、すべてのモデルサイズにおいて、教師ありベースラインよりも一貫して性能が向上し、強力なモデルスケーリング動作が実証されました。
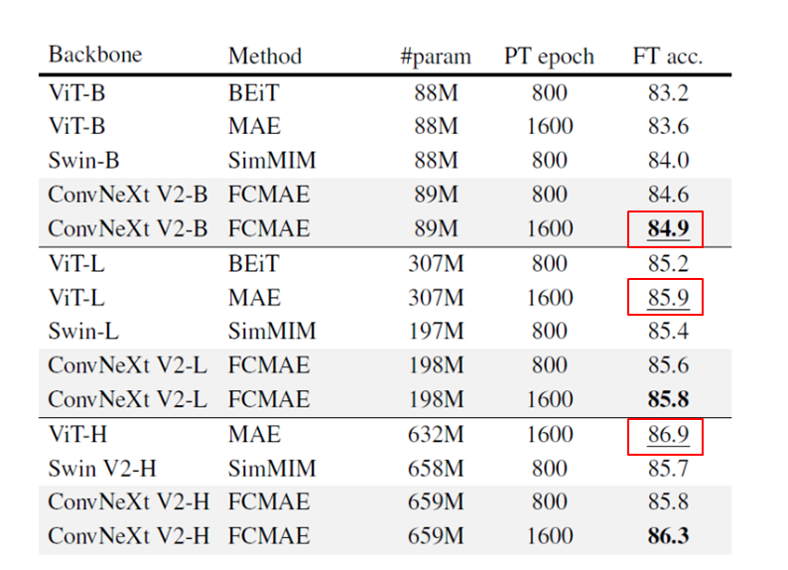
既存モデルとの比較
既存モデル(すべてTransformerベースモデル)と比較しました。事前学習データはImageNet-1K学習セットである。すべての自己教師あり手法は、画像サイズ224でのエンドツーエンドのFine turning性能によってベンチマークされています。SimMIMで事前学習したSwin Transformerを、全てのモデルサイズにおいて上回りました。MAEで事前学習したViTと比較すると、より少ないパラメータ(198M対307M)にも関わらず、Large model領域まで同様の性能を発揮することができます。しかし、巨大なモデル領域では、わずかに劣りました。これは、巨大なViTモデルが自己教師あり事前学習からより多くの益を得ることができるためと思われます。
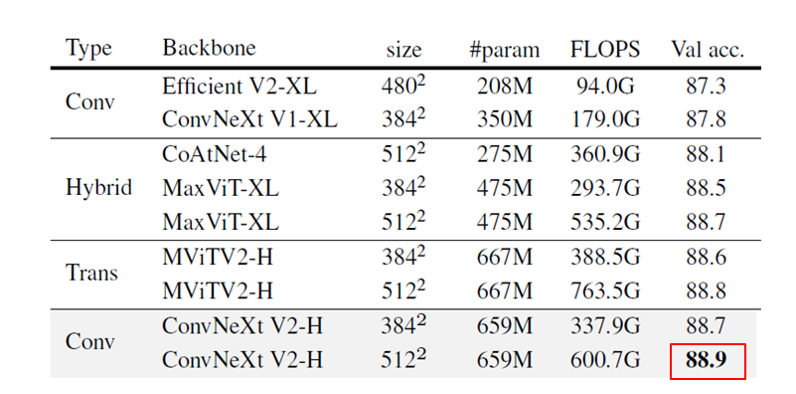
ImageNet-22K intermediate fine-tuning
以下の学習を実施。
1) FCMAEによるpre-training
2) ImageNet-22Kによるfine-tuning
3) ImageNet-1Kによるfine-tuning
Pre-trainingとfine-tuningには、3842枚の解像度画像を用います。この結果を、畳み込みベース、トランスフォーマベース、ハイブリッドデザインなど、最先端のアーキテクチャ設計と比較。これらの結果は全てImageNet22Kの教師ありラベルで学習させたものです。FCMAE事前学習を搭載したConvNeXt V2 Hugeモデルは、他のアーキテクチャを凌駕し、公開データのみを用いた手法の中で88.9%という最新の精度を達成しました。
COCO物体検出とインスタンスセグメンテーションの結果
ConNeXt V2 + FCMAEの転移学習の性能を検証しました。SwinTransformer-Baseのモデルと比べて性能が向上していることがわかります。COCOの fine-tuning 実験は全て ImageNet-1K の事前学習済みモデルに依存します。
UPerNetを用いたADE20Kのセマンティックセグメンテーションの結果
ADE20K datasetにおけるSemantic segmentationの実行結果です。SwinTransformerの結果と比較しました。Object Detection taskと同様、精度が向上しました。
まとめ
ConvNeXtの改良モデルConvNeXt V2を提案。ConvNeXt V2は、自己教師あり学習に適したモデルとして設計されており、そのアーキテクチャは最小限の変更に留まっています。ConvNeXtとMAEはアーキテクチャが大きく異なるため、feature collapseが発生してしまう。その解決としてGlobal Response Normalization(GRN)layerを加え、チャネル間の競合関係を強調することを提案しました。ImageNet classification、 COCO detection、 ADE20K segmentationなどのベンチマークを更新しました。