「OpenAGI:When LLM Meets Domain Experts」はラトガーズ大学のYingqiang Ge ら6名が2023年4月にarXivに発表した論文です。特定のタスクを解くことができるモデルを、大規模言語モデル( LLM : Large Language Model )を使って選択・合成・実行することで複雑なタスクを解くOpenAGIというプラットフォームを提案しています。なお、この記事の画像は全て下記論文から引用しました。
論文:「OpenAGI:When LLM Meets Domain Experts」
URL:https://arxiv.org/abs/2304.04370
Github: https://github.com/agiresearch/OpenAGI
イントロダクション
既存課題と今回の研究
近年、LLM の性能が向上し、LLM に様々なドメイン専門モデルを選択・合成・実行して、複雑なタスクに対処するための学習・推論能力が示されるようになりました。多様なタスクを解決するために、異なるドメインのモデルを合成することをオープンドメイン型モデル統合( Open-domain Model Synthesis:OMS )といいます。OMSは異なるドメインの知識やスキルを統合することで、多様な問題やタスクを解決できる汎用人工知能(AGI)の開発につながる可能性があります。
OMS の既存の研究では、以下の3つの課題があります。
既存課題について
拡張性がない
WebGPT や ToolFormer などの既存の研究では固定数のモデルを採用しており、機能を拡張するのが難しくなっています。
非線形なタスク計画に対応していない
既存の研究の多くは線形計画によるタスク解決に限定されており、次のサブタスクを開始する前に、前のサブタスクを完了させる必要があります。これではマルチモーダルな入力に対応することができません。
定量的な評価ができない
HuggingGPT のように、多くの既存研究は定性的な評価を下すことしかできず、LLMが採用した方法が最適かどうか判断することが困難となっています。
今回の研究(OpenAGI)について
この3つの課題を解決するために、 OpenAGI が開発されました。 OpenAGI は、Hugging Face のtransformersライブラリやdiffusersライブラリ、GIthubリポジトリから主に選ばれた多様なドメイン専門モデル、複雑な複数ステップのタスク、対応するデータセットからなるプラットフォームです。他者の手によって長期的に評価・改善することができるように、全てのコードとデータセットがオープンソース化されているため、「OpenAGI」と名付けられました。
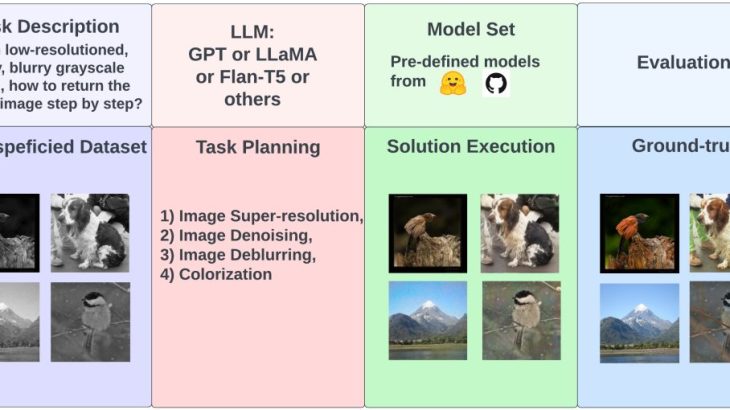
具体的には、以下のようなパイプラインとなっています。
1. タスクに対応したデータセットと共に自然言語で記述されたタスクを選択する。
2. タスク記述を LLM に入力し、ソリューションを生成する。
3. モデルを選択・合成し、実行する。
4. 出力と正解ラベルを比較し、LLMのタスク解決能力を評価する。
OpenAGIの開発にあたり、以下の3つの課題に対して対応しました。
分布外( Out-of-Distribution:OOD )問題
ドメイン専門モデルは、性能が学習データの分布に強く影響するため、汎化能力に限界がある場合があります。例えば、学習データの分布にない画像を処理する場合、下図のように一部の色は正確に復元されるものの、多くの色は不正確になったり、画像がぼやけてしまったりします。

タスク設計の最適化
異なるモデルを組み合わせてタスクを解く方法が多数存在し、最適なアプローチを求めることが困難な場合があります。また、与えられたタスクに対する複数のソリューションの質が大きく異なる可能性もあります。以下は、4つのモデルを異なる順序で実行したとき、生成された画像の質に差があった例です。下の画像は写真全体がぼやけてしまっています。

非線形なタスク構造
あるモデルが複数の入力を必要とする場合があります。例えば、視覚的質問応答( Visual Question Answering : VQA)では画像とテキストの入力を必要とします。タスクを組み合わせる際は前のモデルの出力が次のモデルの入力になるようにするため、非線形なタスク計画では対応できません。
1つ目、2つ目の課題の解決のため、LLM+RLTFアプローチが提案されています。これはタスクフィードバックからの強化学習( Reinforcement Learning from Task Feedback : RLTF )を LLM と組み合わせたアプローチです。LLM がソリューションを生成し、それを強化学習アルゴリズムが評価して LLM にフィードバックを渡します。その後、 LLM はフィードバックをもとに改善されたソリューションを生成します。これを繰り返すことで、 LLM がより良いタスク設計を行うことができるようになります。3つめの課題は非線形なタスク設計によって解決します。ビームサーチで複数の解を出力し、そこから1つを選ぶのではなく、並列なタスクとして選ぶことで並列なタスク設計を実現しています。
本研究の貢献
本研究の貢献は、以下になります。
関連研究
大規模言語モデル(LLM)
今日、多くの訓練データを使い多数のパラメータを持つ LLM が、言語処理タスクにおいて優れた性能を発揮しています。 LLM はスケーリング則に従うという特徴があります。スケーリング則とは、モデルの性能はパラメータの数、学習データの数、計算リソースを変数としたべき乗則に従うという法則のことです。スケーリング則を活かし、最大110億のパラメータを持つ T5 や1750億ものパラメータを持つ GPT-3 が開発されました。現在もこれらのモデルを改良したモデルが次々と発表されています。
拡張言語モデル(ALM)
LLMはドメイン知識を必要とするタスクを解く際に不正確な出力をすることがあります。拡張言語モデル( Augmented Language Model : ALM )は、複雑な課題をより小さなサブタスクに分解できるよう拡張された推論能力と、外部のツールを利用する能力を備えることで、 LLM の弱点を克服することを試みたモデルです。例えば、 ToolFormer は、テキストシーケンス内に外部APIタグを導入することで、 LLM が外部ツールにアクセスできるようにしています。 ALM は、拡張機能を個別に使用することができるだけでなく、機能を結合することもできるため、優れた汎化性能を持ちます。
OpenAGI
問題定義
以下のように記号を定義します。
T : 自然言語で記述されたタスク
t : Tの中の特定のタスク
D : データセットD
Dt : 特定のタスクtに対応するデータセット
M : D上の機能モデルの集合
N : Mに対応する名前
LLMは特定のタスク記述tを入力として、多段階のソリューションを生成するために使われます。T、D、M、Nさえあれば、どのような学習スキーマに基づく LLM でも、 LLM のタスク計画能力を評価することができます。
モデルセット
OpenAGI で選択できるドメインタスクは以下の通りです。各タスクに使用されたモデルは下表の通りです。
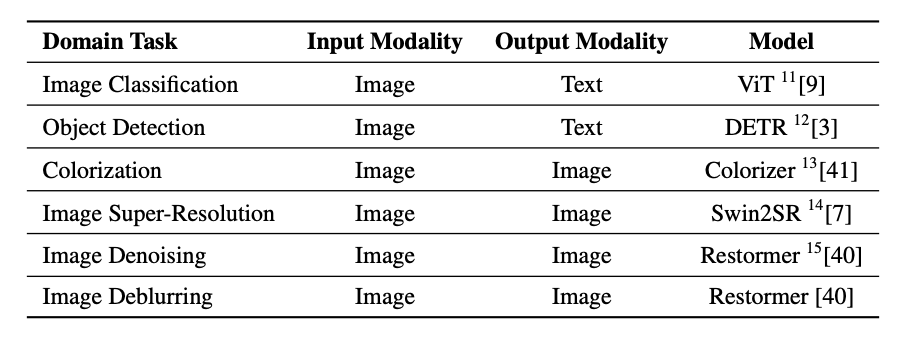
言語関連タスクのモデル
・感情分析
・テキスト要約
・機械翻訳
・フィルマスク
・質問回答
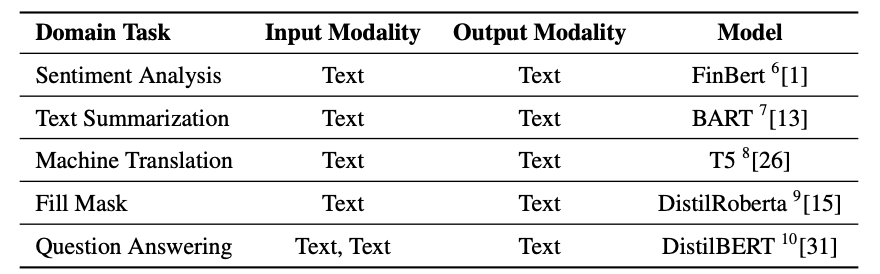
画像関連タスクのモデル
・画像分類
・オブジェクト検出
・画像のカラー化
・画像の超解像
・画像のノイズ除去
・画像のぼかし
画像言語タスクのモデル
・視覚的質問応答(VQA)
・画像キャプション
・文書からの画像生成

タスクとデータセット
データセット
ローデータのセットは以下の通りです。モデルに合わせて選択します。
Image-Net-1K
ImageNet データベースから派生した大規模な画像データセットで、約100万枚の画像を含んでいます。またこれらの画像は1000のクラスに分類することが可能です。
Common Object in Context(COCO)
オブジェクト検出やセグメンテーション、キャプションのために作られた、大規模で豊富な注釈を持つ画像データセットです。80の物体のカテゴリ、150万のアノテーションを含めた20万枚以上のラベル付き画像が含まれています。
CNN/Daily Mail
テキスト要約のためのデータセットです。CNN と Daily Mail のニュース記事から作成された要約です。DeepMind Q&A dataset とも呼ばれています。
Stanford Sentiment Treebank(SST2)
感情分析のためのデータセットで、Stanford Parserで構文木解析したラベル付きの分類木になっています。
TextVQA
VQAとは、ある画像とその画像に対する質問が提示された時に、正しい答えを導き出すためのデータセットです。TextVQAはさらに画像中のテキストの認識も必要とします。
Stanford Question Answering Dataset(SQuAD)
質問応答のためのデータセットで、Wikipediaの記事から作られた質問と答えとペアを集めています。
データ拡張
使用するローデータが決まったら、データ拡張を行い、データを目的の形に変えて使用します。例えば、 ImageNet-1K の画像にノイズを入れたり、画像の解像度を下げたりすることで、画像のノイズ除去や超解像で利用できるようになります。
ガウシアンぼかし
画像をガウシアンカーネルで畳み込む一般的な画像処理技術です。これによってぼかした画像を出力することができます。
ガウシアンノイズ
ガウス分布に基づいたノイズを加えます。
グレースケール化
色のついた画像をグレースケールに変換します。
低解像度化
画像の画素密度を下げます。
翻訳
テキストの言語を別の言語に変換します。OpenAGIでは英語からドイツ語の変換のみを使用しています。
Word Mask
文中の単語の1つを [MASK]トークンに変換します。
複数ステップのタスク
モデルセットの章で示したモデルは、入力と出力のモダリティ別に以下のように分類できます。
・画像入力、画像出力、
・画像入力、テキスト出力、
・テキスト入力、画像出力、
・テキスト入力、テキスト出力、
・画像-テキストペア入力、テキスト出力、
・テキスト-テキストペア入力、テキスト出力

タスクに対応するデータセットやデータ拡張を行うと、185種類もの複数ステップのタスクを生成することができます。そのうち117種類が線形のタスク構造を、68種類が非線形のタスク構造をしています。
評価指標
以下の3つの評価指標をタスクによって使い分けます。文章から画像の変換を行うタスクには CLIP Score を、文章を出力するタスクには BERT Score を、画像を出力するタスクには Vit Score を使用します。また、BERT Score と CLIP Score に関しては正規化をしています。
CLIP Score
OpenAI が発表したモデル CLIP を用いたスコアです。生成された画像と実際の画像の相関を評価します。
BERT Score
事前訓練されたBERTから得られるベクトル表現を利用し、テキスト間のコサイン類似度を計算します。 BERT Score は正解率や再現率、F1スコアを計算します。OpenAGIではF1スコアを採用しています。
Vit Score
2つの画像の視覚的な類似性を評価するための指標です。
タスクフィードバックからの強化学習(RLTF)
入力されたテキストのみからの学習は、現実のタスクを解くのには不十分な場合があります。そこでタスクフィードバックからの強化学習を採用し、データが少ないタスクにも対応できるようにしました。環境は提案されたOpenAGIプラットフォームであり、エージェントはΦでパラメータ化されたLLM (L)です。LLMが生成する解sは、入力として与えられたタスクtを解くためのプロンプトの集合とみなすことができ、対応する拡張データセットDtに対して実行することができます。そのデータセットでの性能を報酬Rとして、Rを最大化するように強化学習でLLMを微調整します。
![]()
Rは微分できないため、方策勾配法を用いてΦを繰り返し更新していきます。この研究ではREINFORCEアルゴリズムを以下のように用います。
![]()
式(2)の近似値は以下のようになります。
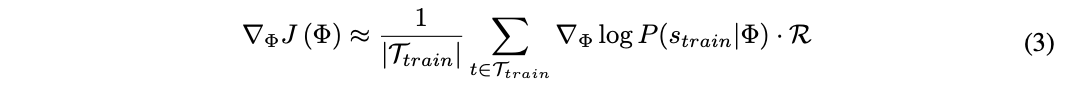
ベースラインとして報酬の移動平均bを用いて推定値の分散を小さくします。
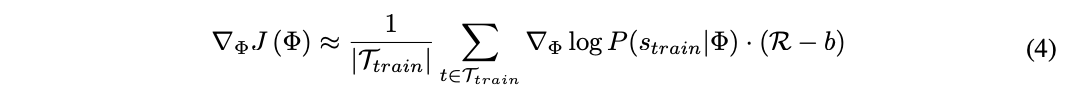
非線形タスク設計
自然言語で記述されたタスクに対してLLMが正しい解を生成するために、LLMは次の3つの条件を満たす必要があります。いずれもビームサーチを用いて条件を満たすようにしています。
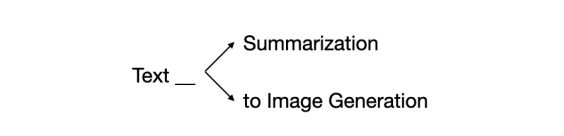
条件1:モデル名のみを生成すること
利用可能なモデル名をLLMに学習させるのではなく、デコードステップごとにMからのみトークンを生成させる制限付きビームサーチを採用しています。例えば、”Text” というトークンがすでに生成されている場合、次に続く単語が”Summarization”(“Text Summarization”:文章要約)または”Generation”(“Text Generation”:文章生成)となるように制限します。
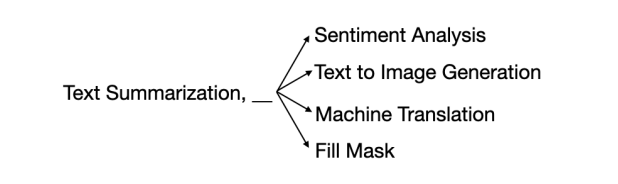
条件2:有効なモデルを生成すること
連続するモデルにおいて、前のモデルの出力と次のモデルの入力のモダリティが一致している必要があります。あるモデルの出力が文章であれば、それに続くモデルの入力も文章でなければなりません。例えば、下図のように前のモデルがテキスト要約であれば、次のモデルはセンチメント分析、テキスト生成などである必要があります。この条件についても、制限付きビームサーチで解決しています。しかし、この方法では VQA などの複数の入力を必要とするモデルに対応できません。この問題に対応するために3つ目の条件が必要になります。
条件3:必要に応じて並列にモデルを生成すること
ビームサーチは本来、複数の選択肢を生成して絞り込みを行い、最終的に1つの選択肢に絞り込みを行う探索アルゴリズムです。しかし OpenAGI では、絞り込みを行わず、生成した選択肢を並列に並べる手段としてビームサーチを採用しています。これによって並列的な結果を入力に必要とするタスクに対応することができます。
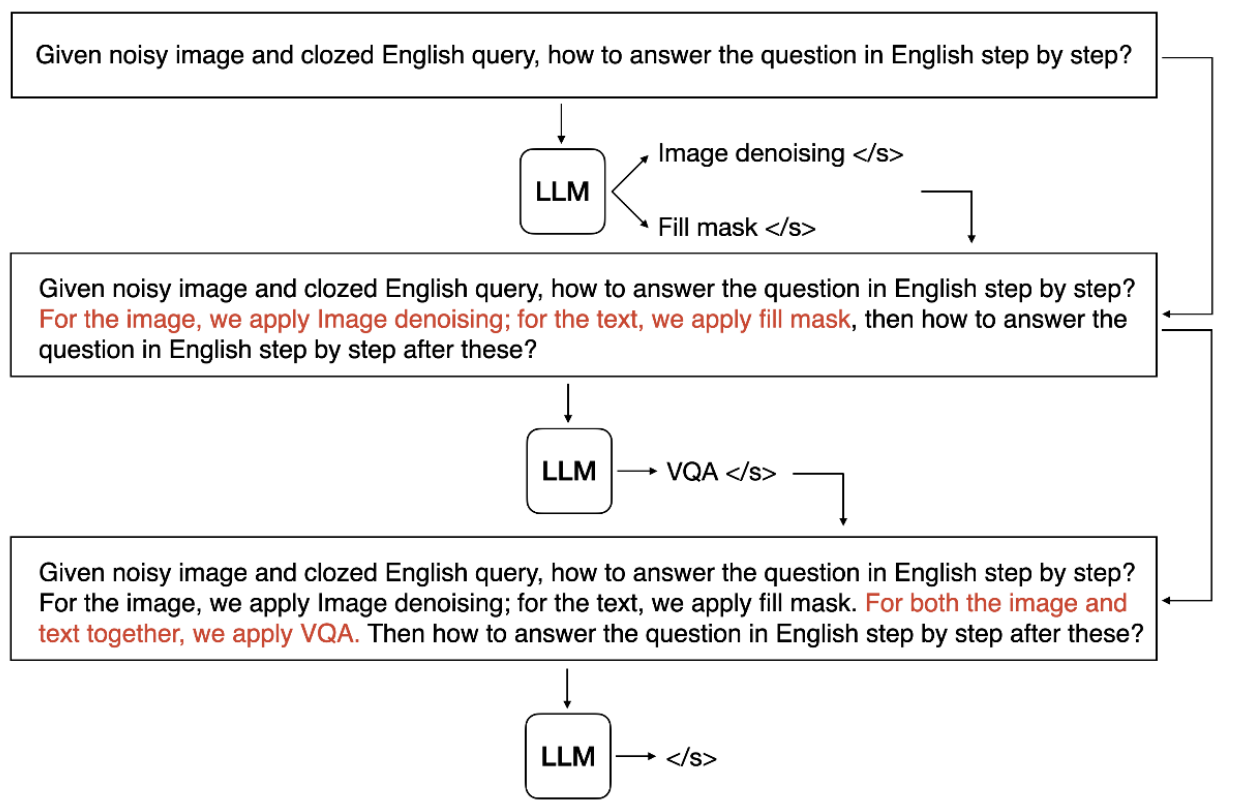
実験
使用した LLM
実験に使用された LLM は以下の3つです。
ChatGPT-turbo(ChatGPT)
OpenAIが開発したGPT-3の微調整版で、1750億以上のパラメータを持ちます。
LLaMA-7b
Metaによって開発されたオープンソースの言語モデルです。軽量で1つのGPUで実行可能です。複数あるモデルのうち、パラメータが70億のものを採用しています。
Flan-T5-Large
Googleが開発した言語モデルで、7億7千万のパラメータを持ちます。
LLM の学習スキーマ
実験には以下の学習スキーマが用いられました。
・Zero-shot 学習
・Few-shot 学習
・ファインチューニング
・RLTF
データセット
タスクはトレーニングセットとテストセットに分割されています。タスクに対応したデータセットの10%がランダムに選択され、トレーニングに使用されました。異なる入力と出力のモダリティを持つタスクの数が不均衡だと結果に影響が出る可能性があるため、さらに10%のデータセットを追加しました。ランダム性の影響を打ち消すために、テストセットはランダムに複数回サンプリングされ、平均性能が計算されています。
結果・分析
実験結果は下表の通りです。総合スコア(Overrall)は CLIP Score 、 BERT Score 、 ViT Score の加重平均として算出されています。
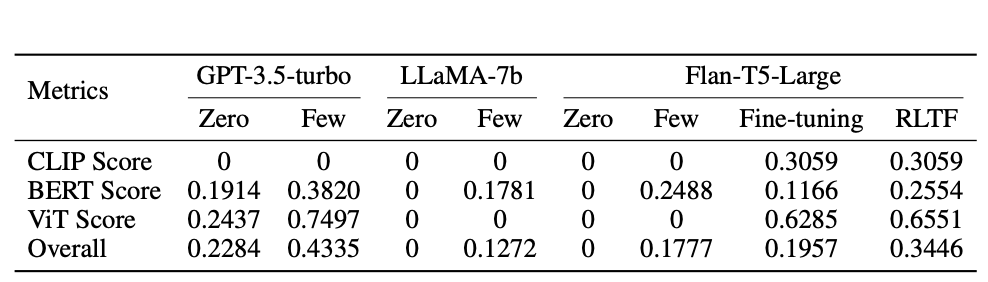
GPT-3.5-turbo は LLaMA-7b や Flan-T5-Large と比べて、Zero-shot学習とFew-shot学習の両方で高いスコアを出しています。 LLaMA-7b はZero-shot学習の性能に比べ、Few-shot学習のスコアの方が高くなっています。しかし、GPT-3.5-turbo よりはるかに低い性能であることがわかります。 Flan-T5-Large はファインチューニングや RLTF を使用した場合、Zero-shot学習やFew-shot学習に比べ、はるかに性能が向上していることがわかります。
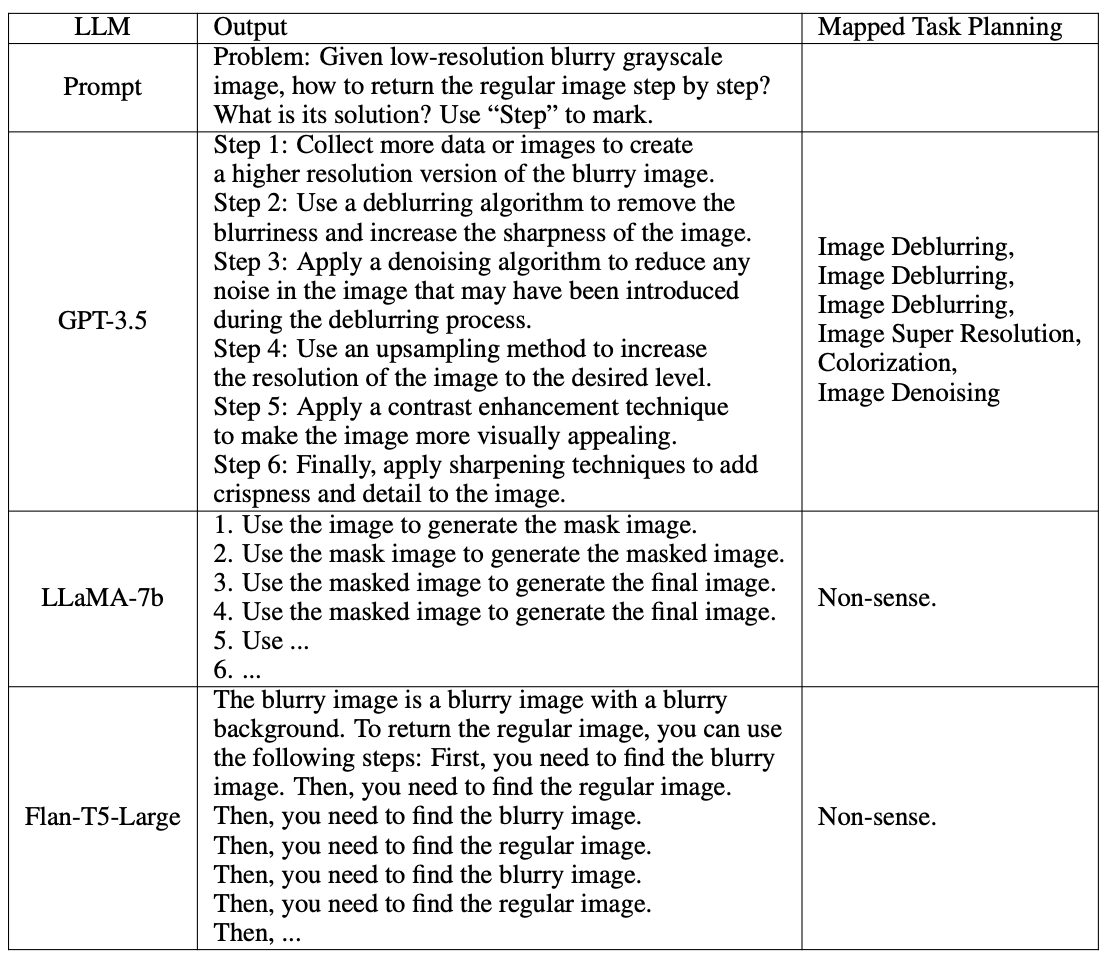
結果を包括的に分析すると、Zero-shot学習では、ほとんどのLLMが最適なソリューションを生成することはおろか、有効なタスク計画さえ生成できていません。Few-shot学習では3つのLLM全てで、 Zero-shot学習よりも性能が向上しています。
以下の図はそれぞれ Zero-shot学習、 Few-shot学習の例です。

結論
まとめ
本研究では、 様々なドメイン専門モデルをLLM を用いて操作することで、複雑なタスクを解決するためのプラットフォームである OpenAGIが紹介されています。また、タスクに対する最適なソリューションを生み出すために、LLM+RLTFアプローチが提案されています。 実験の結果として、小規模なLLMは、RLTFなどの適切な学習方法を用いることで、大規模なモデルよりも優れた性能を得る可能性があると示されました。
今後の展望
1つのタスクに複数のモデルを組み込むことにより分布外問題に対処するためのLLMの選択肢を広げることを目指してます。また、動画や音声などのモダリティのデータセットを OpenAGI に組み込む予定です。これによってより高度なタスク開発が可能になり、より正確な性能の評価に繋がります。評価メカニズムを強化してより正確で包括的な性能評価をすることも目指しています。人間のフィードバックをループに組み込むことも有望な方向性として検討しています。
感想
「AGI」が名前に含まれる OpenAGIですが、既存のタスクを組み合わせるアプローチは、汎用人工知能とはまだ距離があると感じました。オープンソースになっているため、色々な人が改良して、どのように進化していくのかがとても気になります。