はじめに
今回は、ECCV’20でGoogleから新たに発表された画像検索用モデルDELG(DEep Local and Global features)について解説します。これまで画像検索では精度に貢献する局所特徴(Local features)と再現率に貢献する大域特徴(Global features)をどのように利用するかということがひとつのテーマでした。DELGはモデル名にある通り局所特徴(Local features)と大域特徴(Global features)の両方を一つのモデルに統合し効率的な特徴抽出と正確な検索を可能にした革新的なモデルです。以下では、モデルについて論文をもとに解説します。
「Unifying Deep Local and Global Features for Image Search」
https://arxiv.org/abs/2001.05027
GoogleAI blog
「Advancing Instance-Level Recognition Research」
https://ai.googleblog.com/2020/09/advancing-instance-level-recognition.html
GitHub
https://github.com/tensorflow/models/tree/master/research/delf
概要
前提知識
画像検索とは、検索画像に類似する項目を画像データベースから検索する問題です。画像検索の精度をあげるために、画像内のインスタンスを効果的に認識する必要があります。(インスタンスレベルに関しては、下記引用図を参照してください。)画像のなかにあるインスタンスを認識するために、通常、局所特徴(Local features)と大域特徴(Global features)の二種類の画像表現を利用します。


両方を利用する場合、現在ほとんどのシステムでは異なるモデルを個別に利用しており、そのことで計算が冗長になり、全体的な効率が低下しています。
DELGのモデル構造
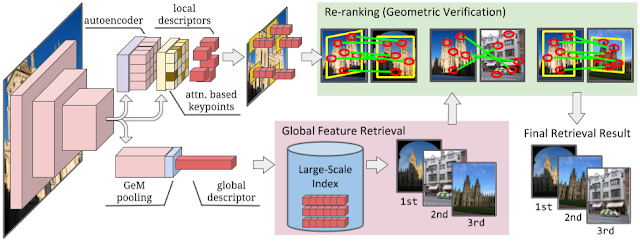
DELGモデルは、二つの異なるヘッドもつ完全畳み込みニューラルネットワーク(fully- convolutional neural network)です。(もちろん二つのヘッドは、以下の図でも示されているようにひとつは大域特徴のためのものであり、もうひとつは局所特徴のためのものです。)
局所特徴は、中間特徴マップを活用して取得されます。このとき、Attentionモジュールを利用することで画像ごとの関連する局所特徴を示す記述子を生成します。
大域特徴は、ネットワークでプーリングされた特徴マップを使用して取得されます。これは、入力画像の顕著な特徴を事実上要約していることを意味しており、入力画像ごとの微妙な変化に対してモデルをよりロバストなものにします。
モデル全体としては、大域特徴を検索ベースのシステムの最初の段階で使用して、最も類似した画像を効率的に選択できます。次に、局所特徴を使用して上位の結果(top、right)を再ランク付けし、システムの精度を高めます。
DELGの実験結果
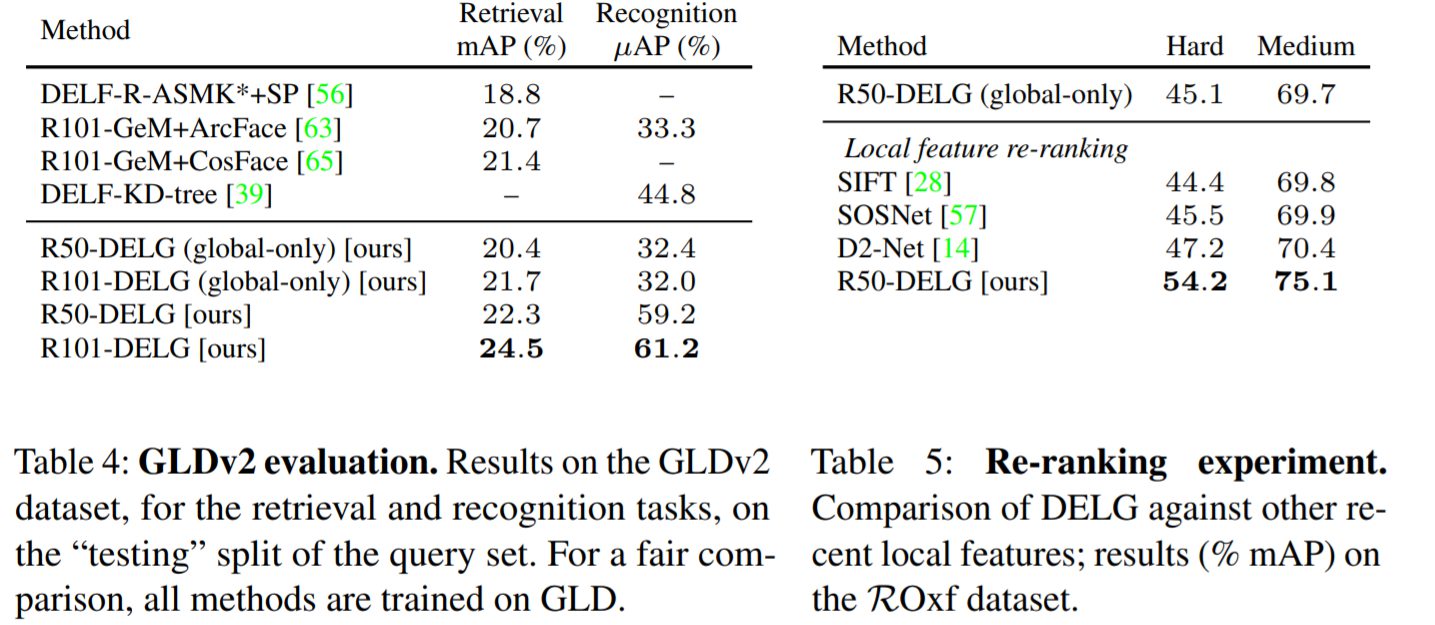
DELGは統合型モデルとしてEnd-to-Endでトレーニングされたものとしては、インスタンスレベルの認識タスクに対してSoATの結果を初めて実証しました。DELGはGLDv2の認識タスクで61.2%の平均精度を達成しました。これは、2019チャレンジの2つの方法を除くすべてを上回っています。そのうえ、上位モデルは複雑なアンサンブル手法を使用していますが、DELGはシンプルな単一モデルのみを使用しています。(なお大域的な特徴を利用した機能を比較した場合、他のアプローチよりも平均精度が最大7.5%向上し、局所的な特徴を用いた再ランク付け段階では、最大7%向上したことが示されています。)
※GLDv2について
GLDv2は、 Google Landmarks Dataset v2の略です。Googleが提供を始めたインスタンスレベルの認識に利用できる最大のデータセットで、200,000のカテゴリにまたがる500万の画像が用意されています。このデータセットでランドマーク検索モデルをトレーニングすることにより、以前のデータセットでトレーニングされたモデルと比較して、平均平均精度が最大6%向上することが実証されています。また、GLDv2データセットを視覚的に探索するための新しいブラウザインターフェイスがリリースされました。
詳細解説
前提知識
画像検索は、検索画像に類似する項目を画像データベースから検索する問題です。この問題を解決するために、これまで大域特徴と局所特徴の2種類の画像表現を利用するモデルが研究されてきました。論文では最近の特徴学習の研究から、大域特徴に対してはgeneralized mean pooling層を、局所特徴に対してはAttention層を組み合わせることが効果的であることがわかっていることが示されています。(DELGでは、それらを組み合わせEnd-to-Endモデルを構築しました。)
DELGの設計思想
最適なパフォーマンスを実現するためには、画像検索には、ユーザーが興味を持っているであろうオブジェクトの種類を意味的に理解し、モデルが関連オブジェクトと背景を区別できるようにする必要があります。そのため、局所特徴と大域特徴の両方とも、画像内の最も識別力の高い情報にのみ焦点を当てる必要があります。
しかし、これら2つの特徴モダリティに求められる動作には大きな違いがあり、それらを共同で学習することはかなりの課題となっています。大域特徴は、関心のある対象が同じ画像であれば似ていて、そうでない場合は似ていなければなりません。そのためには、視点変化や測光変化に対して変わらない高レベルの抽象表現が必要となります。
一方、局所特徴は、特定の画像領域に基づいた表現を符号化する必要があります。特に、キーポイント検出器は視点に対して等しくなければならず、キーポイント記述子は局所的な視覚情報を符号化する必要があります。これは、画像検索システムで広く利用されているクエリ画像とデータベース画像との間の幾何学的整合性チェックを可能にするために非常に重要となります。
さらにDELGの目標は追加の学習段階を必要とせずに、局所特徴と大域特徴を持つEnd-to-Endで学習できるモデルを設計することにあります。これにより、学習パイプラインが簡素化され、より高速な反復学習が可能となり、より広い応用が可能となると考えています。
DELGの特徴・貢献
大域特徴と局所特徴を単一のディープモデルに統合し、より効率的な特徴抽出と正確な検索ができるようになりました。またDELGでは、画像レベルのラベルのみを必要としており、大域特徴と局所特徴の2つのヘッド間の勾配の流れを慎重にバランスさせることで、ネットワーク全体をエンドツーエンドで学習することを可能にしています。また、局所特徴のためのオートエンコーダーベースの次元削減技術を導入し、モデルに統合することで、学習効率とマッチング性能を向上させています。
論文が主張している貢献ポイント
(1) CNNを用いた局所特徴と大域特徴の両方を表現するための統一的なモデルであること
統合したことにより1つのモデル内で画像の大域特徴、検出されたキーポイント、局所特徴を抽出し、効率的な推論を行うことができるようになっています。(CNNに見られるような階層的な画像表現を利用しており、大域特徴に対してgeneralized mean pooling層と局所特徴に対してAttention層を組み合わせることで実現しています。)
(2)低次元の学習に成功した畳み込みオートエンコーダーモジュールを採用していること
統一モデルに容易に組み込むことができるうえ、一般的に使用されているPCAなどの後処理学習ステップを必要としないというメリットがあります。
(3) 画像レベルのスーパービジョンのみを用いて、提案モデルのエンドツーエンド学習を可能にする手順を設計したこと
そのために、誤差逆伝播の際に大域ネットワークヘッドと局所ネットワークヘッドの間の勾配の流れを注意深く制御し、目的の表現を崩さないようにする必要があります。
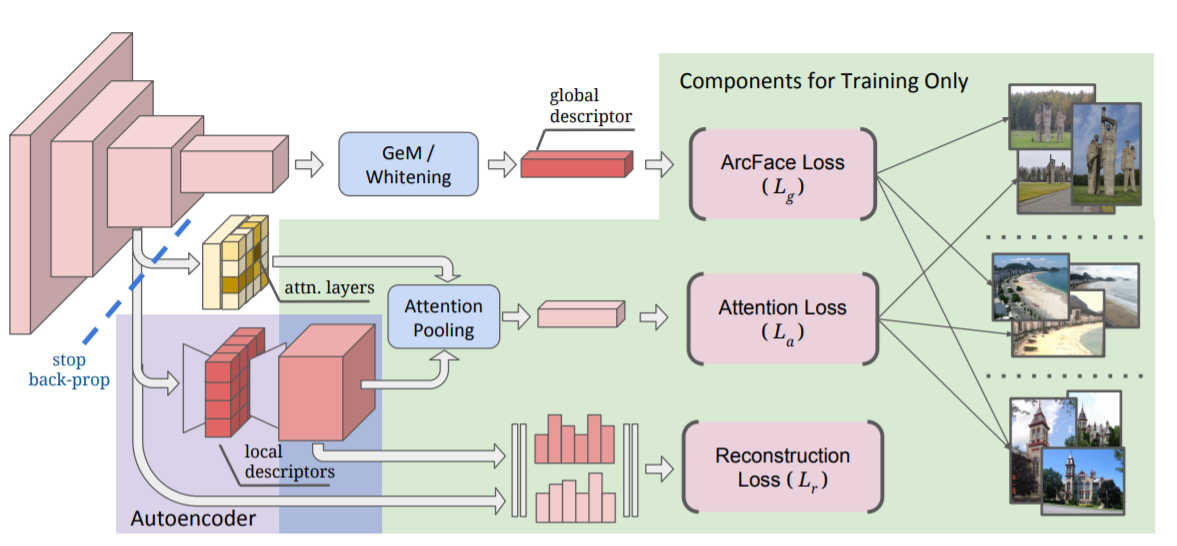
学習について
学習は以下のようになっています。分類ロスが2つあります。大域特徴学習のためのArcFace(Lg)とAttention学習のためのsoftmax(La)です。どちらの場合も、分類の目的は異なるランドマークを区別することになります(インスタンスレベルの認識問題)。自動エンコーダー(紫の部分)は、再構成損失(Lr)を加えてさらに学習されます。モデル全体はエンドツーエンドで学習され、LaとLrからCNNバックボーンへの勾配バックプロパゲーションを止めることで、大きな利益を得ることができます。これは、両者の候がディープモデルを学習する際に通常得られる階層的な特徴表現を大きく乱すからです。特に、両方とも浅い特徴をより局在性の低い特徴に誘導する傾向があり、結果的により粗い特徴になってしまうことがあります。そのため、LrとLaからの逆伝播を停止することによってこの問題を回避することができます。これは、ネットワークがLgのみに基づいて最適化され、望んている階層的特徴表現を生成する傾向があることを意味しています。
実験結果
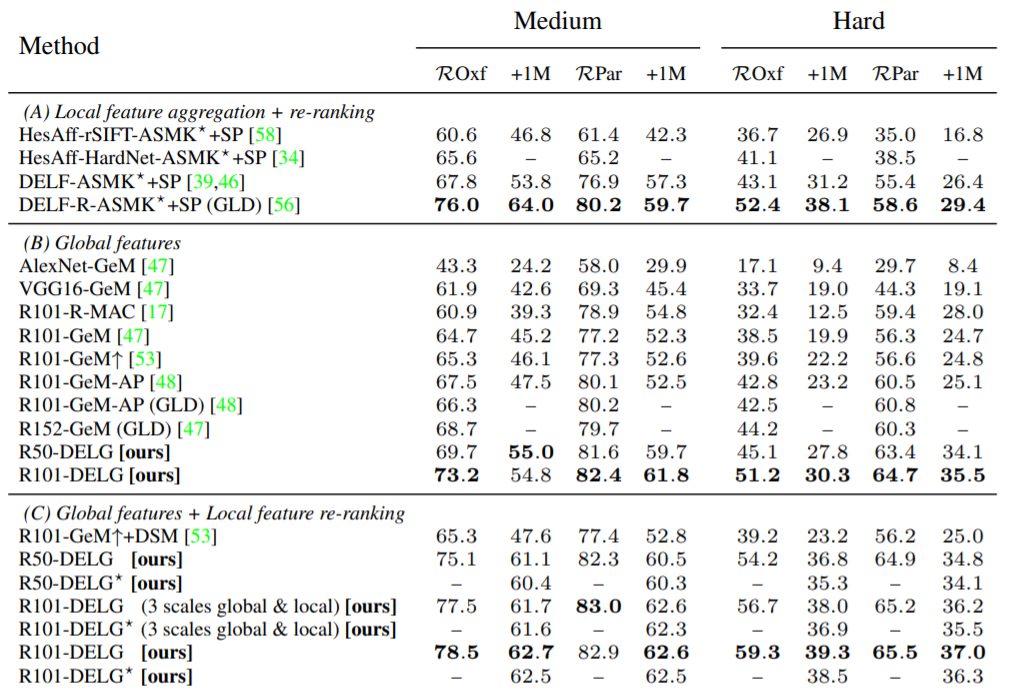
Revisited Oxford(ROxf)とRevisited Paris(RPar)のデータセットを利用した他モデルとの比較
(A)局所特徴の集約と再ランキング
(B)大域特徴の類似性探索
(C)大域特徴探索と局所特徴のマッチングと空間検証(SP)による再ランキング
DELGは8つのケースのうち7つの設定(A)のメソッドよりも優れていることを示しました。
GLDv2データセットと再ランキング実験の結果
どちらもDELGがもっともよい結果を出しています。
まとめ
今回は、画像検索の最新モデルであるDELGについて解説しました。NLP分野で発達し、最近ではDETRなどで用いられたAttention層を利用するなど、領域横断的な工夫がみられます。今後も広く解説していきたいとおもいます。