本稿ではMeta 社から発表された論文である「Revisiting Feature Prediction for Learning Visual Representations from Video」について紹介します。
基本情報
Revisiting Feature Prediction for Learning Visual Representations from Video
参照URL:
https://ai.meta.com/blog/v-jepa-yann-lecun-ai-model-video-joint-embedding-predictive-architecture/
PDF版は以下を参考下さい。
1.イントロダクション
人間は、視覚情報を用いて物や動きの概念を理解し、組み合わせる優れた能力を持っています。機械学習の分野では、人間の学習過程の基本原理や目的を解明することが大きな目標の一つです。その中で注目されている考え方の一つが「Predictive feature principle」です。これは、時間的に近接した感覚情報が互いに予測し合うべきだという考えです。現在の情報から次に何が起こるかを予測する能力が、人間の学習に重要であることを示唆しています。
本研究では、動画から視覚表現を自動的に学習する新しい手法「V-JEPA」を提案しています。教師なし学習で特徴量の予測に焦点を当て、事前学習済みのエンコーダやネガティブサンプル、教師データなどに依存せずに構築されています。V-JEPAは、動画の一部分に基づいて計算された表現が、別の部分から計算された表現から予測できるべきだという要件を満たすように学習されます。特徴量予測を単独の目的関数とすることで、必要不可欠な視覚表現を効率的に学習できると考えています。
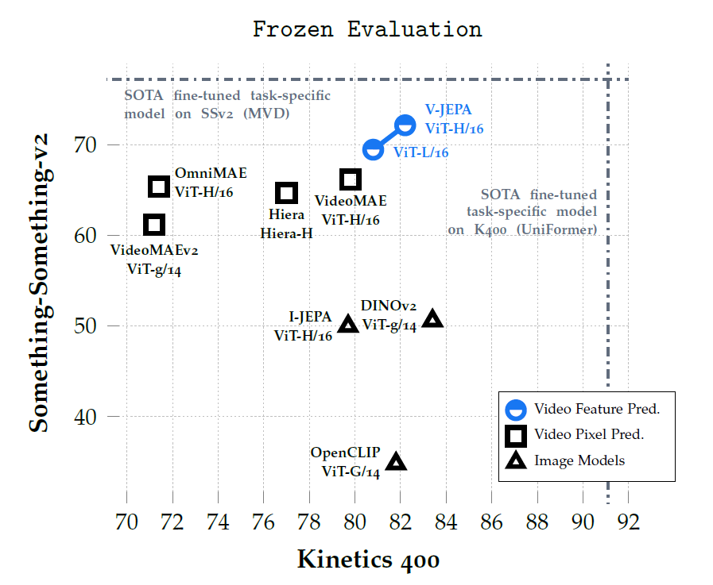
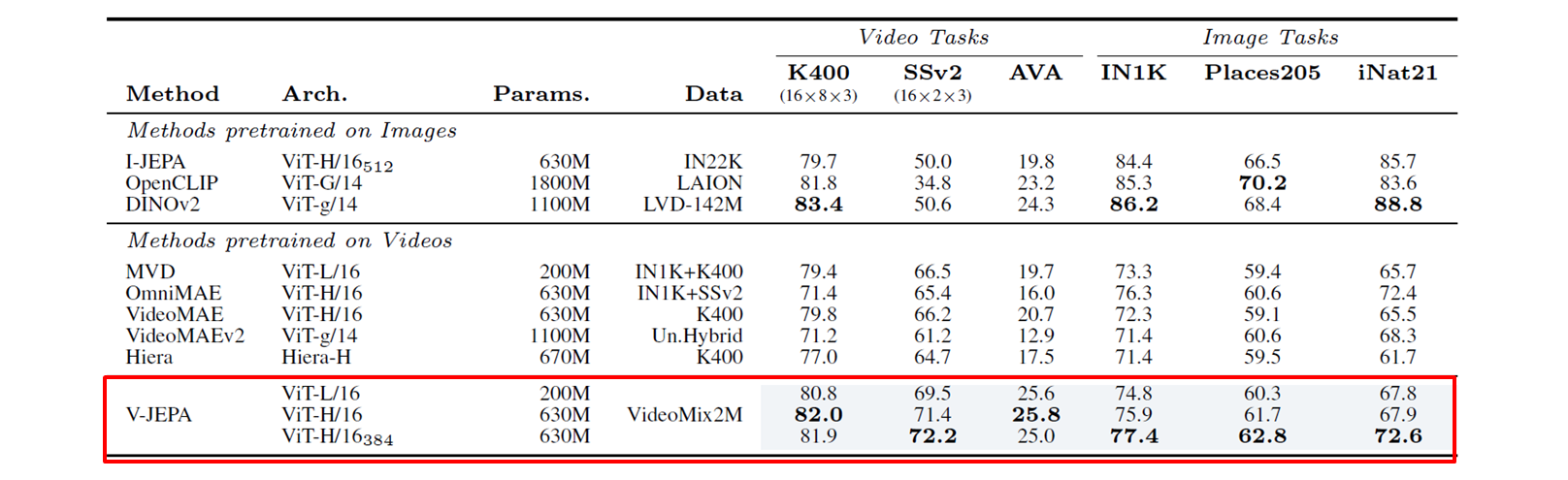
他のモデルとの精度比較
2.関連研究
過去の研究では、時間的に安定した特徴量を得るためのさまざまなアプローチが提案されてきました。スペクトル法を用いて、ビデオフレーム間の変化を緩やかにする「Slow Features」アプローチや、ペア損失やトリプレット損失を通じて時間的な多様性を保持する手法などが研究されてきました。近年では、予測ネットワークを用いて別の時点のフレームの特徴を予測する手法が注目されています。事前に学習された画像やビデオのエンコーダ上に予測ネットワークを学習したり、エンコーダと予測ネットワークを同時に学習したりするアプローチが提案されています。
また、自己教師あり学習の進展により、マスクを利用したピクセル再構成手法の性能が向上しています。ViTを利用したアプローチでは、学習可能なマスクトークンを使うことで、イメージの一部を隠しつつピクセルレベルの特徴を学習できるようになっています。この手法は動画データにも応用され、時空間のマスクを使ったモデリングが行われてきました。さらに最近では、クロスアテンションを用いた新しい学習可能なプーリング機構によって、マスクイメージ自己符号化器の性能がさらに向上しています。
特徴量予測は、ピクセル再構成に比べて、表現の柔軟性と効率的な事前学習が可能という利点があります。表現空間での予測は、low-shot学習や線形プロービングといったタスクでも汎用性の高い表現を生み出すことが知られています。また、ピクセル再構成に比べて事前学習の効率が良いことも確認されています。
本研究では、これらの手法を発展させ、特徴量予測に焦点を当てています。動画から視覚表現を学習するためのV-JEPAモデルの事前学習では、動画の一部を隠してその情報を予測する「マスキングモデリング」と、画像や動画の深い意味を理解するための「JEPA」を組み合わせた方法を取っています。
3.手法
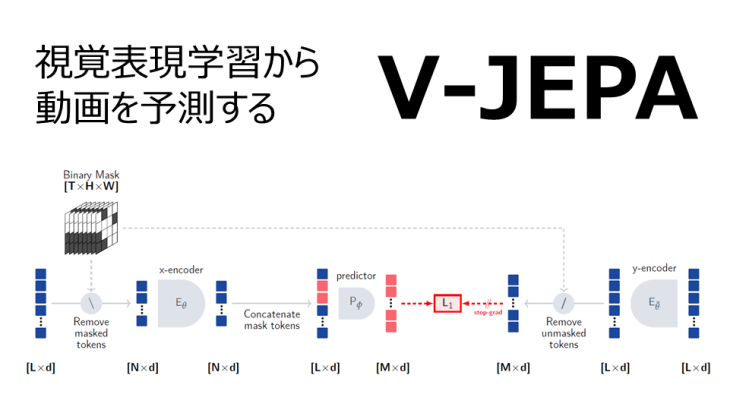
V-JEPA(video joint-embedding predictive architectures)は、動画のトークン列を入力としてマスクされた部分の特徴量を予測する手法です。具体的には、以下のようなプロセスで動作します。
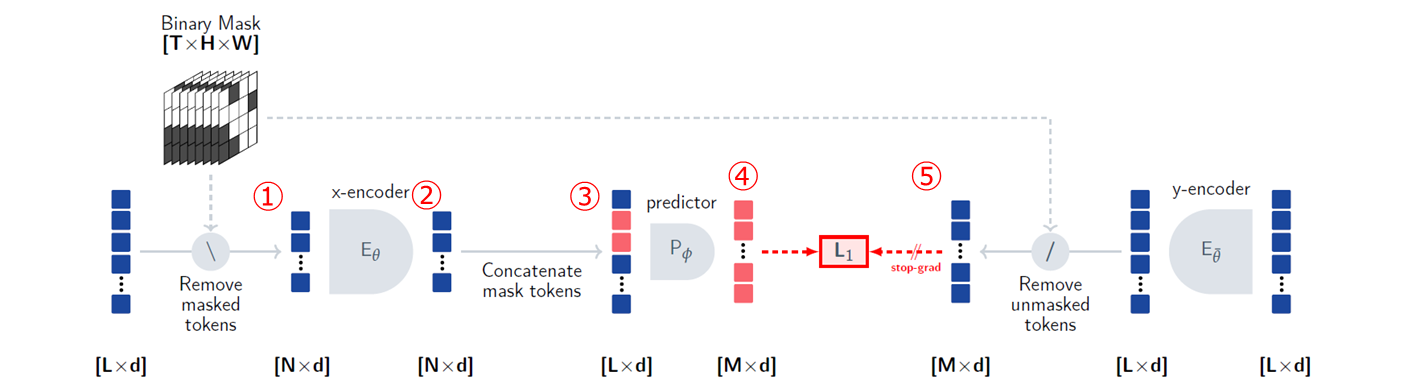
- ① ビデオクリップからトークンを削除して、エンコーダの入力を得る。
- ② エンコーダはマスクされたビデオシーケンスを処理し、各入力トークンに対する埋め込みベクトルを出力する。
- ③ エンコーダの出力をマスクされた時空間パッチの位置埋め込みを含む学習可能なマスクトークンと連結する。
- ④ 予測器ネットワークは、結合されたトークン列から、各マスクトークンの埋め込みベクトルを出力する。
- ⑤ 予測器の出力は、L1損失を用いて予測対象に回帰する。予測対象は、別のエンコーダ(y-エンコーダ)の出力である。
3.1 目的関数
目的関数では、表現の崩壊を防ぐために、回帰の目的関数を修正して使用しています。具体的には、L1損失にストップグラディエント操作と指数移動平均を適用することで、予測器がエンコーダよりも迅速に更新され、最適な状態に近づけられるようにしています。これにより、エンコーダが生成する表現が過度に単純化されることなく、多様性を保ちながら効果的に学習を進めることができます。
予測タスクでは、動画からランダムに領域xとyをマスキングして抽出します。yは空間的に連続するブロックを動画全体にわたって抽出し、xはyで抽出した以外の領域となります。このmulti-blockマスキング戦略により、平均マスキング率は約90%になります。
ネットワークの設計では、ビデオクリップを16×16ピクセルのブロックに分割し、それらを2フレームごとに空間的にも時間的にもまたがる3Dグリッドとして配置したパッチ(トークン)で構成しています。エンコーダはViTを用い、予測器は12ブロック、384次元の埋め込みを持つ狭い(narrow)Transformerで実装されています。
4. 実験結果
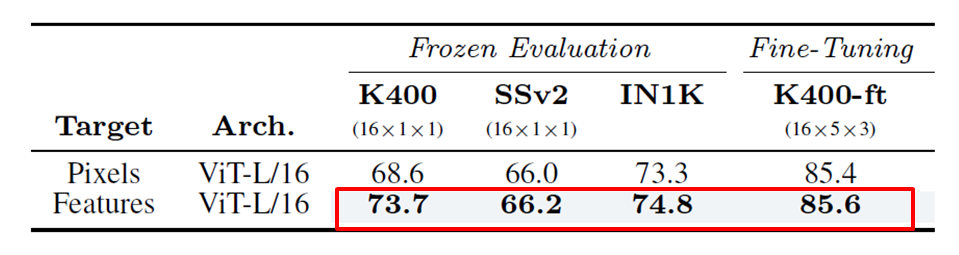
4.1 特徴量予測とピクセル再構成の比較
特徴量予測の方が一貫して良好な結果を示しています。ピクセル再構成では、モデルにビデオの細かいディテールを捉えさせるために多くの計算リソースが必要となるのに対し、特徴量予測は目指すべき表現から不要な情報を除外できる柔軟性を持っているためです。
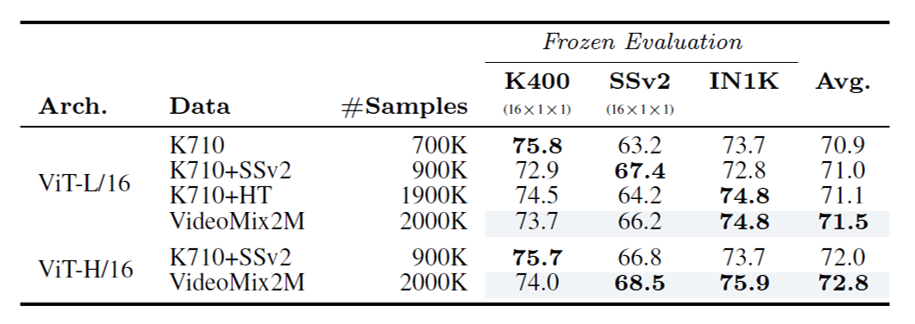
4.2 事前学習データサイズ の比較
事前学習に使用するデータセットが大きいほど、下流タスクの平均性能が向上しています。これは、より豊富な視覚情報を学習できるためと考えられます。
4.3 プーリング手法の比較
クロスアテンションを使ったアダプティブプーリングが、Kinetics-400で+17.3ポイント、Something-Something-v2で+16.1ポイントの性能向上を示しました。これは、空間-時間特徴を適切に統合できることを示唆しています。

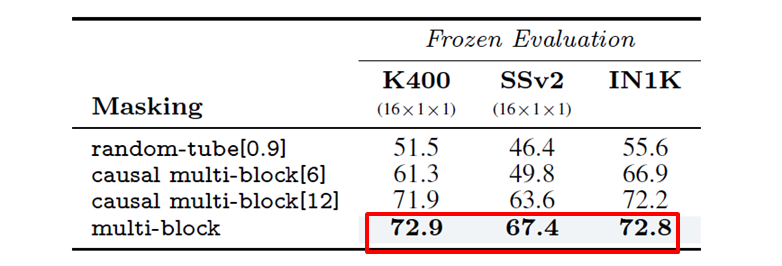
4.4 マスキング手法の比較
ビデオ全体からランダムな空間-時間ブロックをマスクする手法が最も良いパフォーマンスを示しました。これにより、動画の冗長性によるリークを最小限に抑えられているためと考えられます。
5. 先行研究との比較
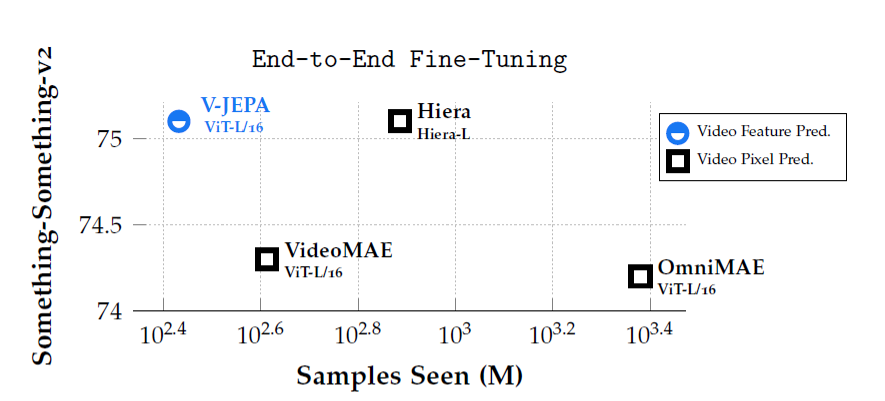
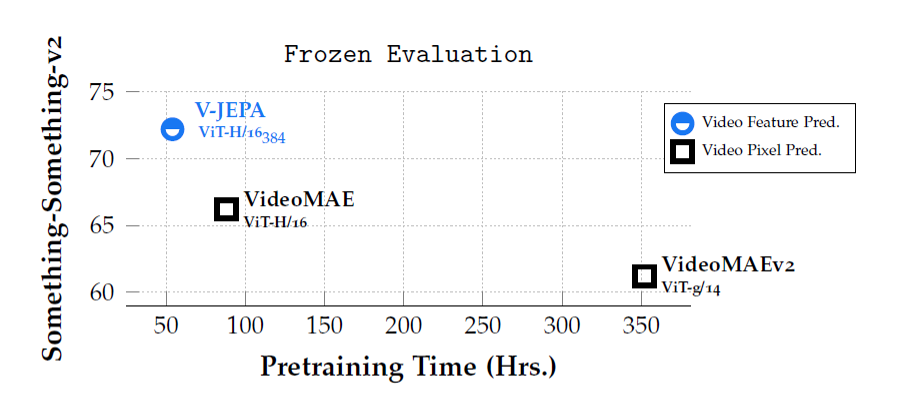
5.1 ピクセル予測との比較
V-JEPAはピクセル再構成手法を上回る性能を示しました。特に、Something-Something-v2の fine-tuning 性能では大幅な改善が見られました。また、事前学習の効率も優れており、ピクセル再構成手法に比べて大幅に短時間で高い性能が得られることが確認されました。
5.2 他手法との比較
V-JEPAは、教師なし事前学習でも他の最先端手法を上回る結果を示しました。特に動作理解を要するSomething-Something-v2タスクで+21ポイントもの大幅な性能向上を達成しています。静的な外観特徴を必要とするタスクでも、ビデオモデルと画像モデルの差を縮小しています。
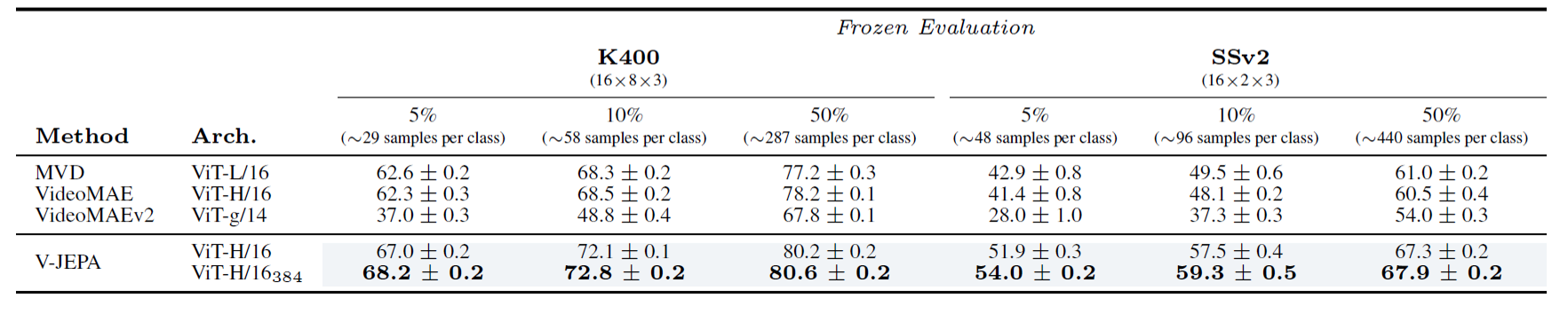
5.3 ラベル効率
V-JEPAはラベル付きデータ数が減少するほど、他のベースラインとの性能差が大きくなる結果を示しました。これは、V-JEPAの表現の汎用性とラベル効率の高さを示唆しています。
6. 予測器の評価
V-JEPAの予測器ネットワークは、ビデオ内の見える領域xから、隠された時空間領域yの内容を予測するように設計されています。この予測結果をピクセルの形に変換する新しいデコーダを学習させた実験から、V-JEPAの予測器が空間的・時間的に整合性のある形で隠された領域の情報を捉えていることが確認できました。サンプル間で共通する特徴は、V-JEPAの予測に含まれる情報を表していると考えられます。
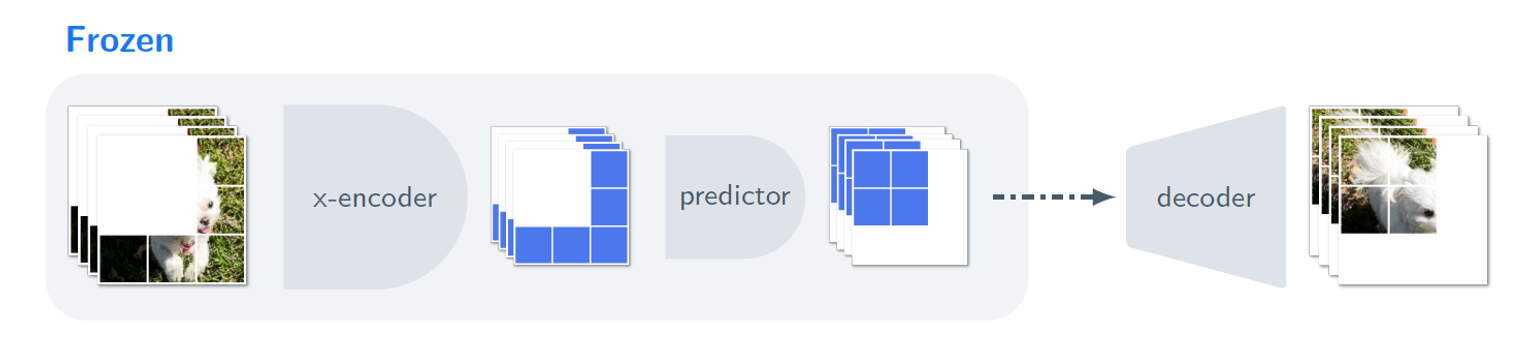

V-JEPAモデルの可視化結果
上段:V-JEPAモデル(ViT-H/16エンコーダと予測ネットワーク)への入力として使われるマスク済みのビデオ。
2~4段:デコーダから生成されたサンプルが元のビデオにオーバーレイされて表示。
※V-JEPAは生成モデルではないため、デコーダはマスクされた領域のコンテキスト情報を持たない。サンプルが入力と完全に一致することは期待されない。
7.まとめ
V-JEPAは、事前学習済みのエンコーダやテキスト、ネガティブサンプル、再構成を使わずに、特徴量予測を単独の目的関数とする手法です。200万本の動画で学習され、パラメータ調整なしで高い汎用性と優れたパフォーマンスを発揮する視覚表現を学習できることが示されました。特に動作理解を要するタスクでの大幅な性能向上や、ラベル効率の高さなど、V-JEPAの有効性が確認できました。本研究は、動画から表現を学習する上で特徴量予測が重要であることを明らかにしています。
所感
当ブログでは、これまでJEPA、I-JEPAと紹介してきました。
JEPAでは少し抽象的な概念が多い内容でしたが、I-JEPAでは具体的な画像の分野への適用が提案され、V-JPEA ではついに動画に適用されました。
この2年間で応用的な手法になっている様子が伺えており、今後の活用が楽しみな技術であると感じています。