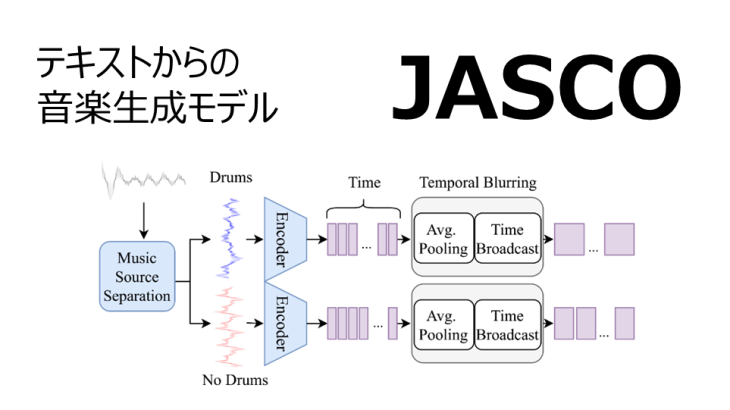
こちらの記事では6月18日にMetaが公開したJASCO
(Joint Audio and Symbolic COnditioning for Temporally Controlled Text-to-Music Generation)
というモデルについて紹介します。
リサーチペーパーURL: https://arxiv.org/pdf/2406.10970
デモページURL: https://pages.cs.huji.ac.il/adiyoss-lab/JASCO/
1.イントロダクション
1-1.概要
JASCOは時間的に制御されたテキストから音楽生成をするモデルです。このモデルでは、音楽的な記号とオーディオベースの条件づけが使用されています。
コード進行やメロディーといった記号的な条件や、楽器の編成などのテキストでの条件に対応して音楽を生成することができます。
テンポやシーンの変化などの時間的な進行を条件づけるテキスト
例: 「穏やかなピアノのエンディング」、「90年代アップテンポなテクノサウンド」
や、サンプルとなる音楽トラックから特定の部分を抽出したものから音楽生成を行います。
モデルは、時間的ブラーリングと情報ボトルネックレイヤーを組み合わせた制御を行っています。公開された論文では、JASCOの構造、訓練方法、実験結果についてが記され、既存の音楽生成モデルと比較してその優位性を示しています。
時間的ブラーリングのプロセス図
1-2.先行研究
Metaは一年前にMusicGenというモデルを発表しています。テキストでの条件づけ
例:「1990年代の曲」、「明るいディスコサウンド」、「バイオリンの音」
と、サンプル音源から音楽生成をするモデルです。
MusicGen URL: https://huggingface.co/spaces/facebook/MusicGen
音楽生成モデルはこの近年特に研究されている分野で、AIを使った音楽生成はアーティストや様々なコンテンツクリエイターにとって利用価値のあるツールとなってきているのは確かなものの、音声の潜在表現からの生成にばかり焦点が向けられてきました。具体的にはMousai、 Rifffusion、 MusicLM、 Noise2Music などが挙げられます。
現在、音楽構造(Aメロ、Bメロ等)やビート、コード進行の条件を追加した生成について、複数の研究者が調査しています。
このような背景から、音楽クリエイターがより利用しやすい条件での音楽生成AIであるJASCOが開発されました。
2.バックグラウンド
2-1.オーディオ表現について
近年のオーディオ生成モデルでは、RVQ(Residual Vector Quantization)という手法でデータが圧縮されてます。具体的な動作プロセスは以下の通りです。
①元となるオーディオ信号を低次元の連続潜在テンソルzに変換する。
EnCodecという畳み込み自動エンコーダを使い、オーディオ信号をフレームレートでエンコードし、128次元のzに変換します。
②RVQでzを量子化し、ストリームを構成する。
連続データzを離散的なトークンqに変換し、データサイズを小さくします。
RVQはデータを複数回量子化する手法です。前段階の量子化誤差である残差を新たに量子化する動作を繰り返し、より正確な量子化を行います。
③トークンを使ってオーディオ信号を再生成する
量子化されたトークンqをデコーダネットワークで処理し、元のオーディオ信号を再構成します。
JASCOでは、連続テンソルzをオーディオの潜在表現として、離散表現qをオーディオの調整に利用しています。
2-2.フローマッチングについて
音声生成や画像生成において非常に優れていると近年評されている Flow Matching Modeling Paradigm は、基本的な事前分布から目的のデータ分布への変換を連続的にモデル化する手法です。JASCOでは、フローマッチングの一種であるCFM(Conditional Flow Matching) を使用しています。CFMは、標準正規分布からデータを生成するために、データサンプルがどのように変換されていくのかを時間的に追跡します。
JASCOの研究ではOT(Optimal Transport) Path という、データのある分布から別の分布へ効率的に移動するための経路を見つける手法が重視されています。OT Pathは、特定の条件と時間パラメータに基づいて、連続テンソルzのベクトル場を予測するモデルをトレーニングします。
3.手法
3-1.条件設定
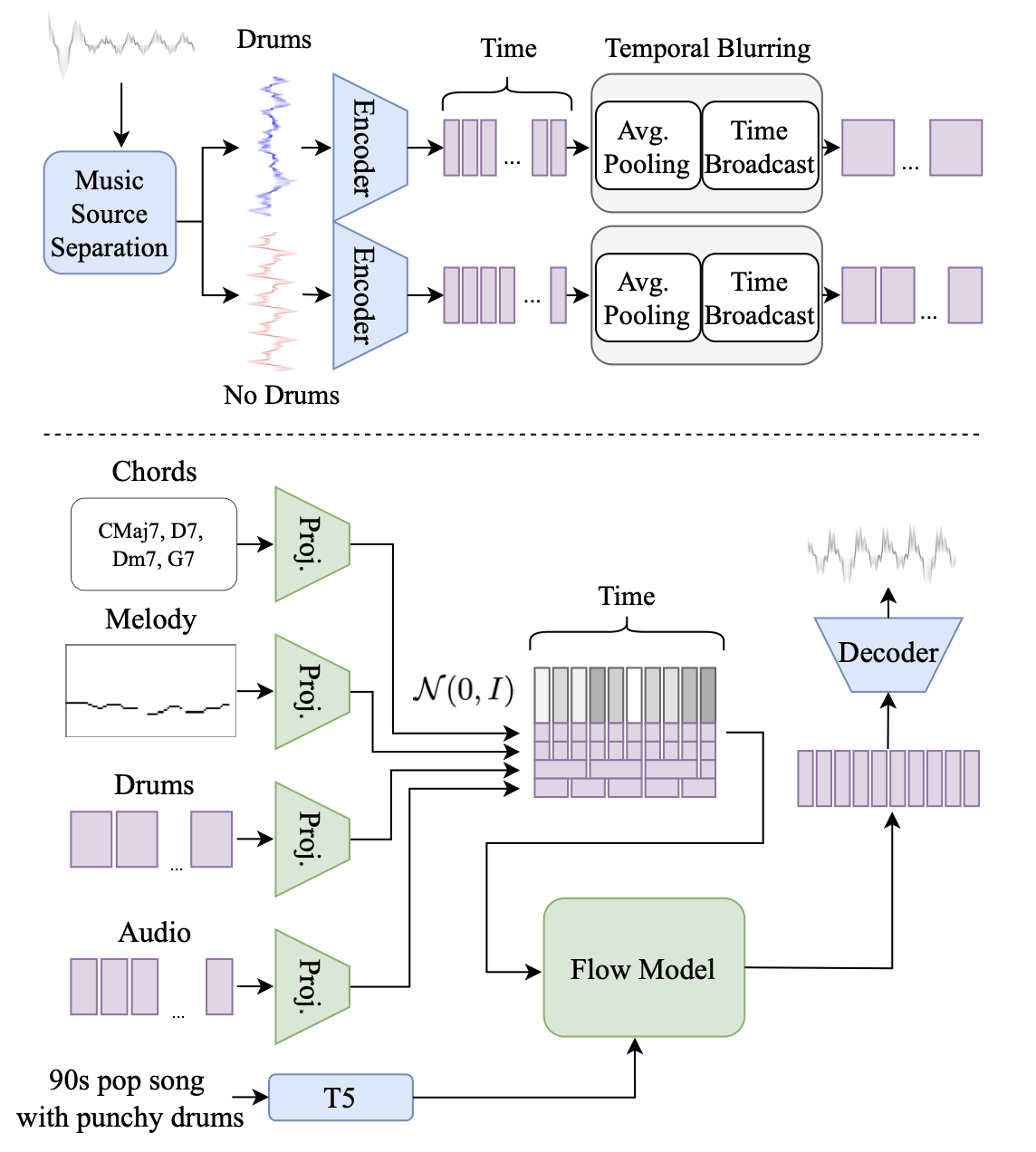
JASCOで使用される音楽生成のための条件づけは音声プロンプトと記号プロンプトの大きく分けて二つです。
音声プロンプトでは、サンプルとなる音楽トラックからの特定のリズムやドラムのパターンが条件として使用されます。ドラム部分については、まず事前トレーニングされた音源分離モデルを使って抽出し、その波形を2.1で説明した方法で処理します。その後、平均プーリングと再拡張という方法で生成される音楽の時間的なブレを滑らかにし、出力次元の設定を行います。
記号条件では、 楽曲のコード進行認識モデル Chordinoを使用して抽出したコード進行や、事前トレーニングされたマルチF0分類器を使用して抽出したメロディーラインが使用されます。
Chrodino GitHub: https://github.com/ohollo/chord-extractor
以上に加え、音声波形内の欠損部分を補完するインペインティングと、波形の端部に続く部分の生成をするアウトペインティングをランダムに行います。
3-2.モデルと最適化プロセス
JASCOのCFMはTransformer というモデルを基盤とし、U-Net のようなスキップ接続を採用しています。畳み込み位置エンコーディングや双方向のSelf-Attentionバイアスを使用して、音楽生成の制度を向上させています。
Transformer DeepSquare内説明: https://deepsquare.jp/2020/07/transformer/
3-3. 推論
JASCO の推論の手順は以下の通りです。
① 3-1に記した方法でコード進行やメロディーなどの条件の入力を準備する。
② 音楽生成の開始点(初期トークン)を設定する。
③ ①と② を元に、新しい音楽のシーケンスを生成する。
生成されたトークンが次のトークンの生成に自己回帰的に使用されます。
④生成されたシーケンスを後処理し最終的な音楽データに変換する。
4.実験詳細
4-1.実験の設定
以下に実験の設定、準備されたデータ、モデルのトレーニング方法、評価基準について記します。
トレーニングデータセット:
二万時間分のインストゥルメンタル音楽(ロイヤリティーフリー)と、独自の1万曲の高品質トラック。全て説明テキストと組み合わされている。サンプリングレートは32kHz。
評価:
MusicCaps (ベンチマークデータセット)
5500曲の10秒間のサンプルと、528トラックのテストセットで構成される。
エンコーディング方法:
EnCodecモデルで2048サイズの4つのコードブック、フレームレート50Hz。
テキスト表現:
T5(Text-To-Text Transfer Transformer)
Googleが開発した、自然言語処理用に事前訓練されたモデル。音楽とテキストの対応関係を学習するために使用される。
T5 URL: https://huggingface.co/docs/transformers/model_doc/t5
使用したモデル:
・メロディー抽出…マルチF0検出器
・コード抽出…Chordino
・ドラムトラック抽出…Hybrid Demucs(Deep Extractor for Music Sources)
モデルのトレーニング方法:
・単一条件の訓練…40%のドロップアウト
・複数条件の訓練..全ての条件に対して20%のドロップアウト。残り80%では、各条件に対して個別に50%のドロップアウト。
・CFG(Classifer-Free Guidance)係数をテキスト、ローカルコンデイション、テキストとローカルコンディションの組み合わせ、の3パターンの条件に対して{0.0, 0.5} × {0.0, −0.5} × {1.5, 2.0}で適用。
・ステップ数500、オーディオセグメント10秒、バッチサイズ336
モデルの最適化:
Adam(Adaptive Moment Estimation)を使用。最初の5000ステップ間で学習率が最大値で10^(-4)に達し、その後減衰。ノルム0.2で勾配クリッピング。
4-2.実験の評価
論文では和音のマッチング、リズムの整合性、メロディーの規則性の遵守の観点からJASCOを評価しています。また、音声の品質とテキストへの従順度についても測定しています。
客観的評価と、人間による評価を取っています。
・客観的評価
FAD(Fréchet Audio Distance)、KL(Kullback-Leiber Divergence)、CLAPスコアなどの音声評価に広く使用されている指標を使用しています。
FADの値が低い場合、生成された音楽がより高い品質だと言えます。
KLの値が低い場合、生成された音楽が元となる音源と同様のコンセプトを持つと言えます。
CLAPスコアが高い場合、テキストでの条件づけ(説明)と生成された音楽の整合性があると言えます。
CLAP GitHub: https://github.com/LAION-AI/CLAP
また、ビートについてはmir evalという、音楽情報検索分野で広く使用されるライブラリを使用して、音が始まる瞬間をどれだけ正確に検出できたかを示す指標である onset F1 スコアを評価しています。
mir eval GitHub: https://github.com/craffel/mir_evaluators
コード進行については、リファレンス信号とモデルから生成された信号のIOU(intersection over union)スコアを計算して評価しています。
mir eval とIOUはどちらも数値が高い方が評価が高いと言えます。
・人間による評価
Amazon Mechanical Turk プラットフォームを使用して募集した評価者に、0~100のスケールで、以下の三つの観点から評価してもらった。
1. 全体的な品質
2. テキスト説明との類似性
3.元となるサンプル音源のメロディーまたはリズムパターンに準拠しているか
5. 結果
5-1. メロディーの規則性
JASCOを、MusicGen とMusicControlNetと比較します。
MusicControlNetは2023年に発表されたテキストプロンプトを使った音楽生成モデルです。
結果は以下の表の通りです。
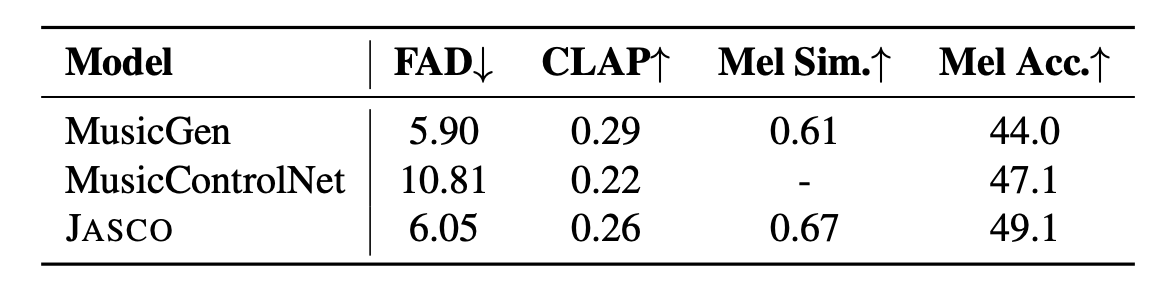
メロディーの精度(Mel. Acc.)を考慮するとJASCOがメロディーの規則性の遵守において評価が高いことが確認できます。
また、論文内ではMusicGenやMusicControlNetが採用している手法である加算バイアスによる条件づけが、JASCOの連結アプローチに比べて劣る可能性がある仮説が立てられています。
5-2.ローカルコントロール
JASCOで提案されたコード、メロディー、オーディオ、ドラムの各時間的制御についての評価が行われました。これにあたり、各条件づけの個別のモデルと、複数の条件づけのモデルがトレーニングされました。
メロディー、Onset F1、コードのIOU の評価には、元となる音源を条件として使用します。
FAD、KL、CLAPスコアの計算には、テストセットからランダムに選択されたオーディオを条件として使用しています。
これらを、テキストのみを条件としたモデルと比較します。
結果は以下の表の通りです。
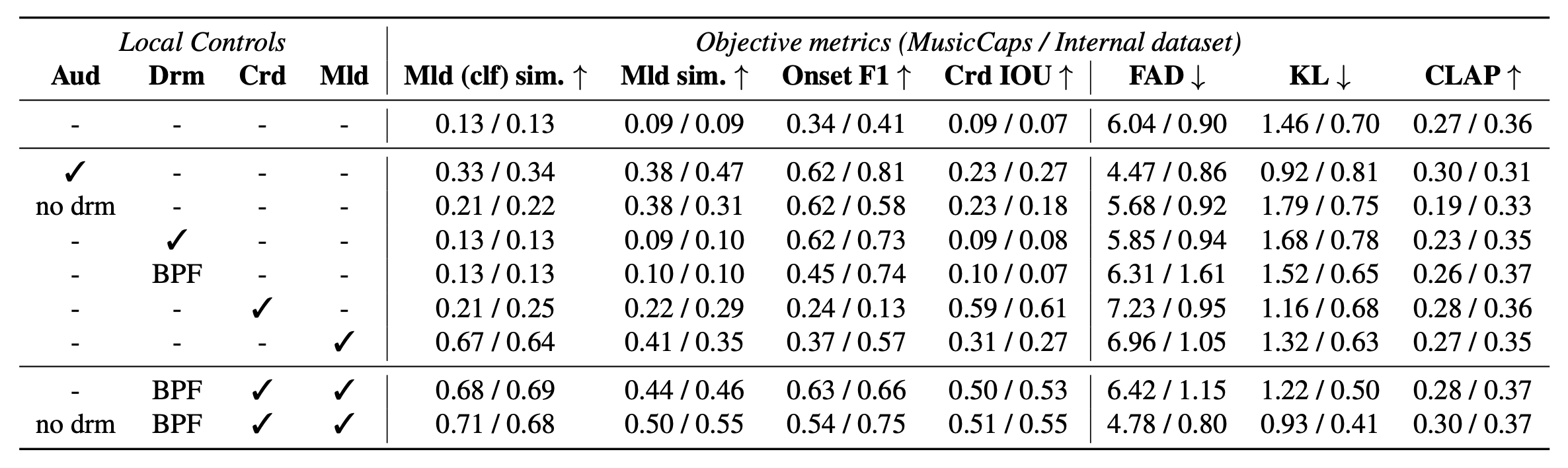
表の見方
各行は、特定の条件下で訓練されたモデルのパフォーマンスを示しています。
表の左側の列のチェックについて、例えばAudの列にチェックがある場合、音声に基づくコントロールが適用されています。また、BPFと記されているDrm列は、バンドパスフィルタを適用したドラムトラックが使用されています。
表の一行目の数値(0.13/0.13 0.09/0.09 ……)が、テキストのみを条件としたモデルの評価結果です。各ローカルコントロールがどれほど有効か評価するための基準となっています。
表の下二行は、複数の条件づけをした場合の数値です。
斜線/で分けられている数値の左側がMusicCapsのデータセット、右側が独自のデータセットでの数値です。
コードの条件づけでは、IOUの数値が0.09/0.07 から0.59/0.61に向上しています。
また、ランダムに選択されたオーディオ条件での評価でありながら、FAD、KL、CLAPスコアは基準と比較してほぼ同等です。JASCOモデルが各条件に対して良好な結果を示しつつ、テキストに基づく条件ずけや音質評価においてもほぼ同じレベルを維持しており、バランスの取れた性能を発揮していると言えます。
複数の条件づけでも、単一の条件づけと同様の傾向が見られ、FAD、KL、CLAPスコアも基準と比較とほぼ同等です。ここから、複数の条件づけでもJASCOの性能は落ちないことが分かります。
また、人間による評価で、JASCOとMusicGenの比較も行われました。
テキストのみの場合とテキストとメロディー両方の場合の条件で評価されています。
テキストとドラムを条件とした場合の結果も出されています。
結果は以下の表の通りです。
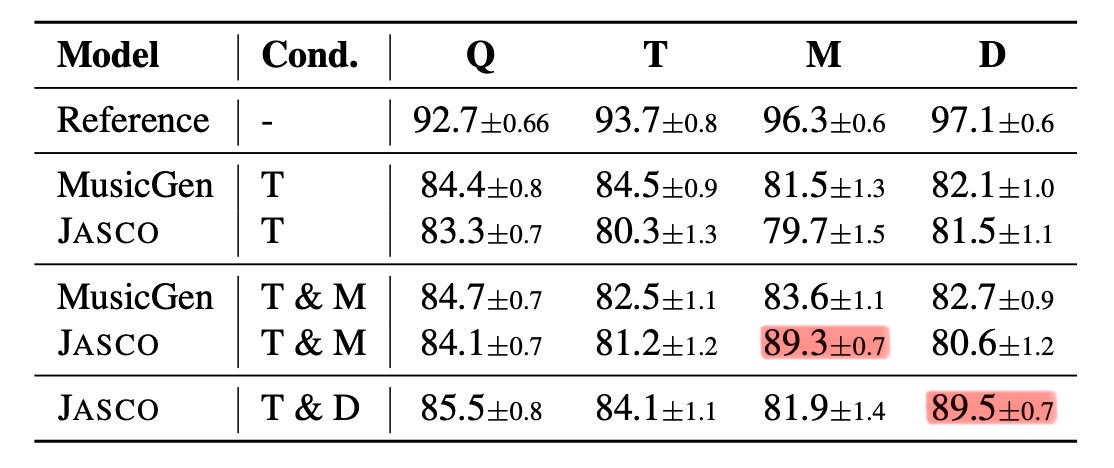
Q:音楽の全体的な品質、T:テキスト遵守度、M:メロディー整合度、D:ドラム整合度
MusicGenとおおよそ同等の生成品質をJASCOが達成していることが分かります。テキスト遵守度はMusicGenの方が優れた結果を示していますが、メロディーの条件づけを考慮するとJASCOは優れたスコアを出していると言えます。
生成する音楽の品質やテキスト遵守度を落とさずにそれぞれの条件づけでの制御を行っていることが示されています。また、メロディーやドラムの条件づけの際、期待どおりに関連する評価項目(赤マークアップ部)での数値が向上しつつも、全体の音楽の品質やテキスト整合性は、無条件モデル(表のReference部)の数値と比較して大差ありません。
6.分析
5-1で記した、条件づけの方法の違いによる音楽生成の精度を比較するため、JASCOの手法(Concat)を、MusicGenで使用されるCross Attentionモデルと、MusicControlNetで使用されるZero Convolutionと比較した結果が下の表に記されています。

全ての数値において、JASCOの手法が最も優れていることが確認できます。
また、JASCOで使用されたフローマッチングと、多くの音楽生成で使用されている拡散モデルとの比較結果が下のグラフに記されています。
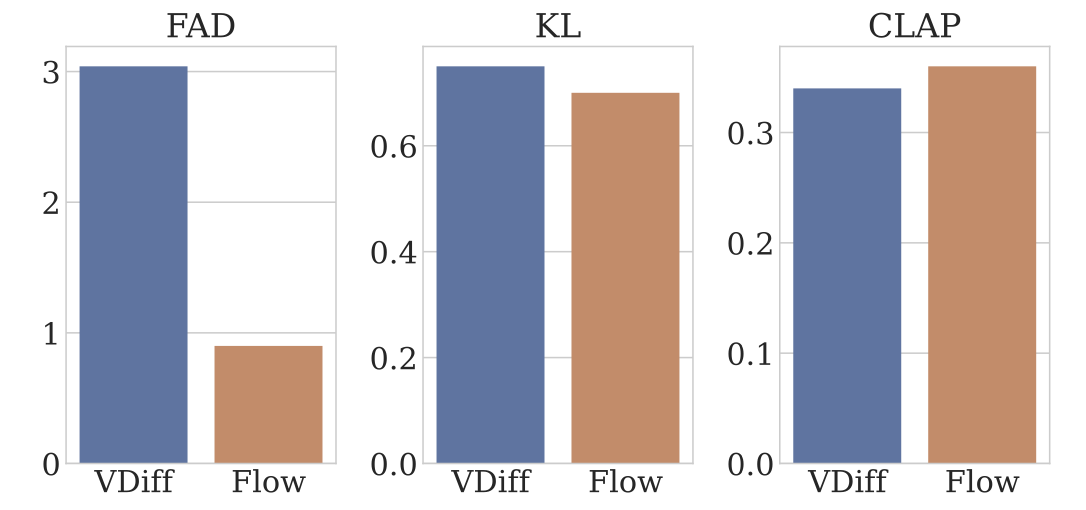
全ての項目でフローマッチングが優れており、特にFADにおいて大きな差が見られます。
また論文内では、最初に示されたJASCOの損失関数と修正された損失関数をFAD、KL、CLAPスコアを使って比較し、新しい損失関数の有効性も確認しています。
7.関連研究
音声生成においてフローマッチングを使った研究では、テキストに基づいた多言語音声生成モデルVoiceBoxや機能が拡張されたAudioBoxなどが発表されています。AudioBoxはEnCodecで動作している点でJASCOと類似しています。
しかし、音楽生成においてはフローマッチングを適用した研究がこれまであまり行われていません。
他にも、時間的に制御された音楽生成モデルにはMusicLM、MusicGen、MusicControlNet、DITTOといったものが挙げられます。
8.まとめ
時間的に制御可能な、テキストからの音楽生成を行うJASCOは、フローマッチングのモデルを使用して、密な音楽の潜在表現上で動作します。全体の音声品質を高い基準で保ちながら、和音、メロディー、リズム、音楽スタイルなどについてのテキスト記述に基づいて音楽生成を行えることが実験の結果から示されました。
一方、JASCOの課題としては、生成される音楽が約10秒程と短い点と、生成時間の長さが挙げられます。
今後の研究としては、音楽構造や、(クレシェンド、デクレシェンドなどの音量の変化など更なる制御機能のサポートが計画されています。
感想:
音楽生成モデルは、複数の似たような曲やBGMを必要としている、音楽制作をしないクリエイターにとって便利なツールだと考えていました。
一方、JASCOはコード進行やリズム、BPMといった条件づけがあり、自ら音楽制作を行うクリエイターにとってこそ利用しがいのあるツールだと感じました。本モデルの更なる発展が楽しみです。