WaveNet及び周辺知識についてまとめました。
音声認識と音声合成の概要
音声認識とは、人の声の波形を機械で処理し、どんな内容(文)であったかを推定する技術である。また音声合成とは、与えられた内容(文)と人間が認識できる音声を収集した人の声から機械によって合成する技術のことである。この二つに音声認識で推定した内容(文)に対して適切な応答文を出力する「対話制御」という技術が加わることで、「人の話を聞いた機会が適切な応答を音声で返す」という一連の動作を実現することができる。
音声合成の最初期の研究はベル研究所ではじまったものが確認できる。音声認識・合成ともに、コンピュータを利用した研究のはじまりは1950年ごろからとされている。一般的になったのはコンピュータインフラが確立されるようになる1990年代後半からである。代表例として、音声認識では「Dragon naturally Speaking」(ドラゴンスピーチ、1997年)という音声書き起こしソフトや、「ピカチュウげんきでチュウ」(1998年)や「シーマン」(1999年)などのゲームがあがる。音声合成ではコールセンターの機械応答などが導入されるようになり、ボーカロイドとして有名になった「初音ミク」、ニコニコ動画の「ゆっくり実況」などで使用された「SofTalk」などがあげられる。
音声合成技術の歴史・問題点
音声合成とは『声の高さの成分』と『共振特性』(音色)という2つの特徴を推定することにある。従来は、推定のために発声メカニズムの数理モデルが用いられていた。しかし自然な発声時には同じことを二度行っても微妙な音声の違い(波形の違い)=「ゆらぎ成分」が生じるが、数理モデルではこの「ゆらぎ成分」の再現が困難であった。数理モデルによる音声合成では、「ゆらぎ」に対応するために確率的なアプローチがよく用いられるが、不確実な「ゆらぎ」のみを記述する確率モデルを構築することが難しいとされたためである。そのため、WaveNet以前はいかに精度良く「ゆらぎ」を付与するかが中心の問題となっていた。なお文章から自然な音声に変換しようとすることを、一般的にtext-to-speech (TTS)という。
従来、TTSには波形接続TTSとパラメトリックTTSが構想されていた。
・波形接続TTS
波形接続TTSとは1人の話者による短い音節のセットから必要なものを結合して合成する技術のこと。実応用の場面では、一般的に波形接続TTSが主流であった。しかし元々用意していた話者から声を変えたり、抑揚や感情を加えることが難しいという欠点があった。
・パラメトリックTTS
パラメトリックTTSとは話す内容や特徴(声、抑揚など)を入力によって操作できる技術のこと。コンピュータで生成された音声をガイドするために、文法や口の動きに関する一連のルールやパラメータを使用するもので、音を連結する必要性をなくす。この方法は安価で迅速だが、生成される音声の品質が波形接続TTSに劣るとされていた。
音声認識技術の歴史・問題点
音声認識技術の主流は、得られた音声波形から「スペクトログラム」(波形を短時間で切った周波数成分(音色))を時系列に並べたものを作成し、それを適切な数理モデルを使用することで文を推定していくものとなっている。
よく利用されていたのが『隠れマルコフモデル』(HMM)という統計学の確率モデルであった。このモデルではどこからどこまでが1つの音に対応するかを決める必要がなかったためである。ディープニューラルネットワーク(DNN)を利用する研究は昔からあったが、米Microsoftが2010年ごろに発表したHMMとDNNをハイブリッドで使うモデルが注目を浴び、それから多くの音声認識研究者がDNNを利用するようになった。
近年はHMMを用いないモデルも出てきており、ブラックボックス化が顕著とされる。また最近では、『再帰型ニューラルネットワーク』(RNN)を用いたモデルも利用されている。
WaveNet概要
囲碁で世界トップの実力を持つプロ棋士に勝利したAI「AlphaGo」を作った、Google傘下のDeepMindが開発した。波形接続TTSではなくパラメトリックTTSを利用している。2016年にモデルが発表され、2017年に実用化段階にいたった。最初のリリース時点(2016年)ではWaveNetは非常に計算コストが高く、0.02秒の音声を生成するのに1秒を要していた。(たった1秒の音声を生成するのにほぼ1分近い時間がかかっていたことを意味する。)そのため、実用には適していなかった。その後、新しく改良されたWaveNet(2017年)は、実時間に比べて20倍の速さで音声を生成するようになった。(2秒の音声を0.1秒で生成することを意味する。)さらに8ビットではなく16ビットで、1秒あたり2万4000回という高いレートでサンプリングを行なうことも可能になった。
コンピュータによる音声合成・音声認識に対して大きな衝撃を与えた技術といわれる。

引用 https://deepmind.com/blog/article/wavenet-generative-model-raw-audio
WaveNetの革新性
WaveNetは従来型よりも自然な発音に大きく近づいた。これは単純化や近似といった、大きな劣化を生むプロセスがないためで、WaveNetの特筆すべき点とされる。反対にボーカロイドなどがいわゆる「機械っぽい」音声から抜け出せないのは、従来の数理モデルを利用しているためである。数理モデルは実際の現象をかなり単純化しているので、そこで大きな劣化が生まれているのが1つの要因だとされる。
WaveNetの誕生が可能になった土台には、インフラ的な側面とアルゴリズム的な側面があるとされる。インフラ的な側面としては「データ量と計算能力」の圧倒的な向上があり、アルゴリズム的な側面として「音声を『点』の時系列として捉え、ディープラーニングに入力すること」が発展したことにある。
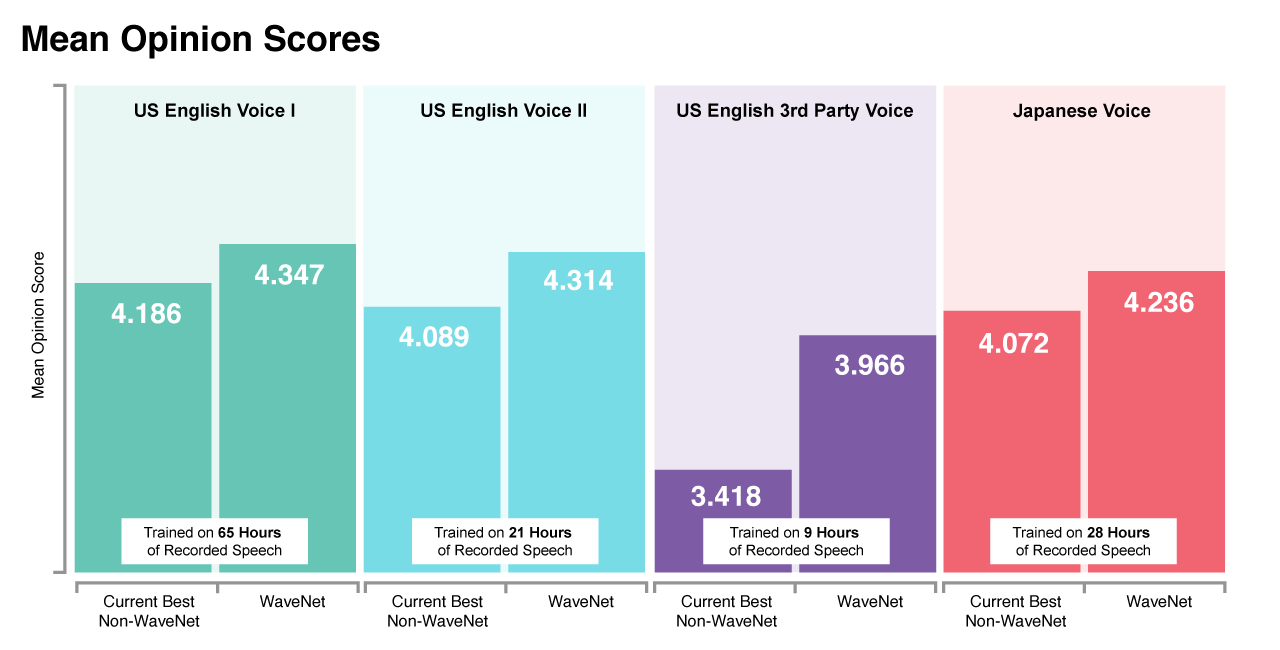
MOSは人間の聴者によるテスト。WaveNetは従来型のものよりも大幅に改善され、人間に近づいた。
引用 https://deepmind.com/blog/article/wavenet-generative-model-ra
WaveNetは「音声を点として考える」方式を取っている。音声は本来アナログ信号だが、コンピュータで扱う際には「サンプリング」および「量子化」(=波形を分割して点にすること)という作業をする。WaveNetとは、量子化された個々の波形を一度に1サンプルずつ、毎秒16,000サンプルで作成し、個々のサウンド間のシームレスな遷移を可能にするディープ・ジェネレーティブ・モデルである。
※量子化について
例えばCD音質の「44.1kHz/16bit」などのこと。これはある音声波形から1秒間に4万4100回、波形の「一瞬」を切り取り(標本化)、その波形の値を2の16乗の種類、すなわち、6万5536種類の値に置き換え(量子化)、1秒間の空気振動を4万4100個の6万5536種類からなる点というデジタルデータで表している。音声を取り扱う際には、16kHzのサンプリング周波数が比較的よく利用されている。音声の特徴をうまく活用すれば、8bitの量子化でも比較的高い音質を維持できる。
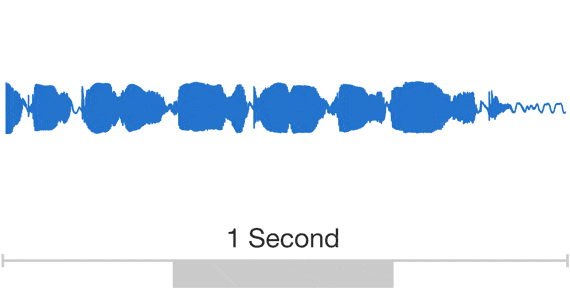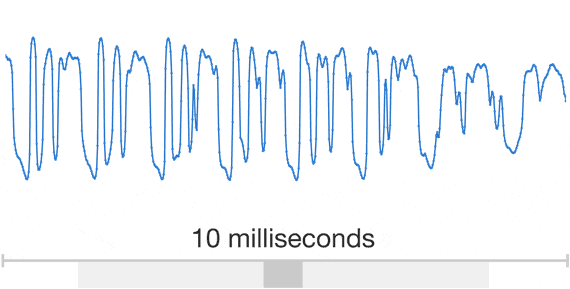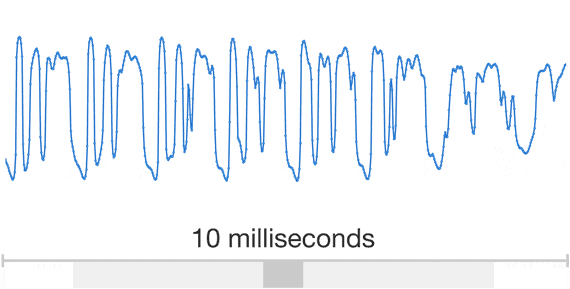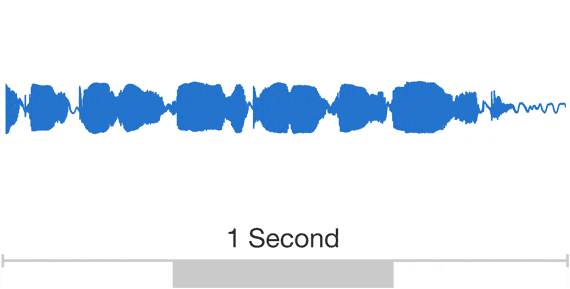
引用https://deepmind.com/blog/article/wavenet-generative-model-raw-audio
WaveNetでは、この「点」を畳み込みニューラルネットワーク(CNN)で処理している。ただし、音声信号特有の難しさとして、時系列の依存関係が非常に長い点がある。この長い依存関係を自己回帰モデルで扱うのは困難な課題であった。WaveNetはdilated convolutionという仕組みを使って受容野が指数関数的に広くなるようにCNNを構築し、この問題を解決した。音声を、1秒間だけでも1万6000個の点になる巨大な系列データとして捉え、音声合成の際にはこの点を直接CNNから生成することで音声波形を形作っている。これにより、従来の数理モデルで必要だった過程や近似などの研究者による調整作業がなくなった。
※dilated convolutionのきっかけになったのが、DeepMind社が同時期に発表したPixelRNNとPixelCNNモデルである。同モデルは複雑な自然画像を一度に1ピクセルずつではなく、一度に1色チャンネル(one colour-channel)ずつ生成することが可能であることを示した。これに触発されて、2次元のPixelNetを1次元のWaveNetに適応させたことが問題解決へと導いた。
WaveNetの技術的詳細
以下、技術的な詳細となる。
〇WaveNetとは
PixelCNN3をベースとした音声波形を生成するためのDNNのひとつ。パラメトリックTTSモデルを採用している。
既存のパラメトリックモデルは通常、ボコーダとして知られる信号処理アルゴリズムに出力を渡すことで音声信号を生成する。しかし、WaveNetは、オーディオ信号の生波形を一度に1サンプルずつ直接モデル化することで、このパラダイムを変更している。生波形を使用することで、より自然な音声が得られるだけでなく、WaveNetは音楽を含むあらゆる種類のオーディオをモデル化することができるとされる。
〇モデル概要
残差ブロックとスキップコネクションをネットワーク全体に採用することで、「より深い学習」と「多様な特徴抽出」を可能にしている。活性化関数は、PixelCNNで使用されたGTU(gated tanh unit)を採用している。(GTUは、活性関数としてよく使われるReLUよりも、音声信号に対しては良く機能するとされている。)
また、通常の音声信号は16bitの整数値(0-65535)で保存されている。(この整数値から直接予測をすることも可能であるが、)計算負荷を減らすためにWaveNetでは256クラスのカテゴリ変数に変換し(その際にsoftmax層を利用している)、生成する音声がどのクラスに属するかという分類問題として生成音声の予測を行うアプローチを採用している。
WaveNetの確率分布は、過去の時系列データに加えて、付加情報hも条件として持っている。hにはテキスト(内容)や話者の情報(声)を含めることができ、これによってWaveNetは”付加情報 : h” の情報を指定した”出力波形 : x”の確率分布を計算することができている。
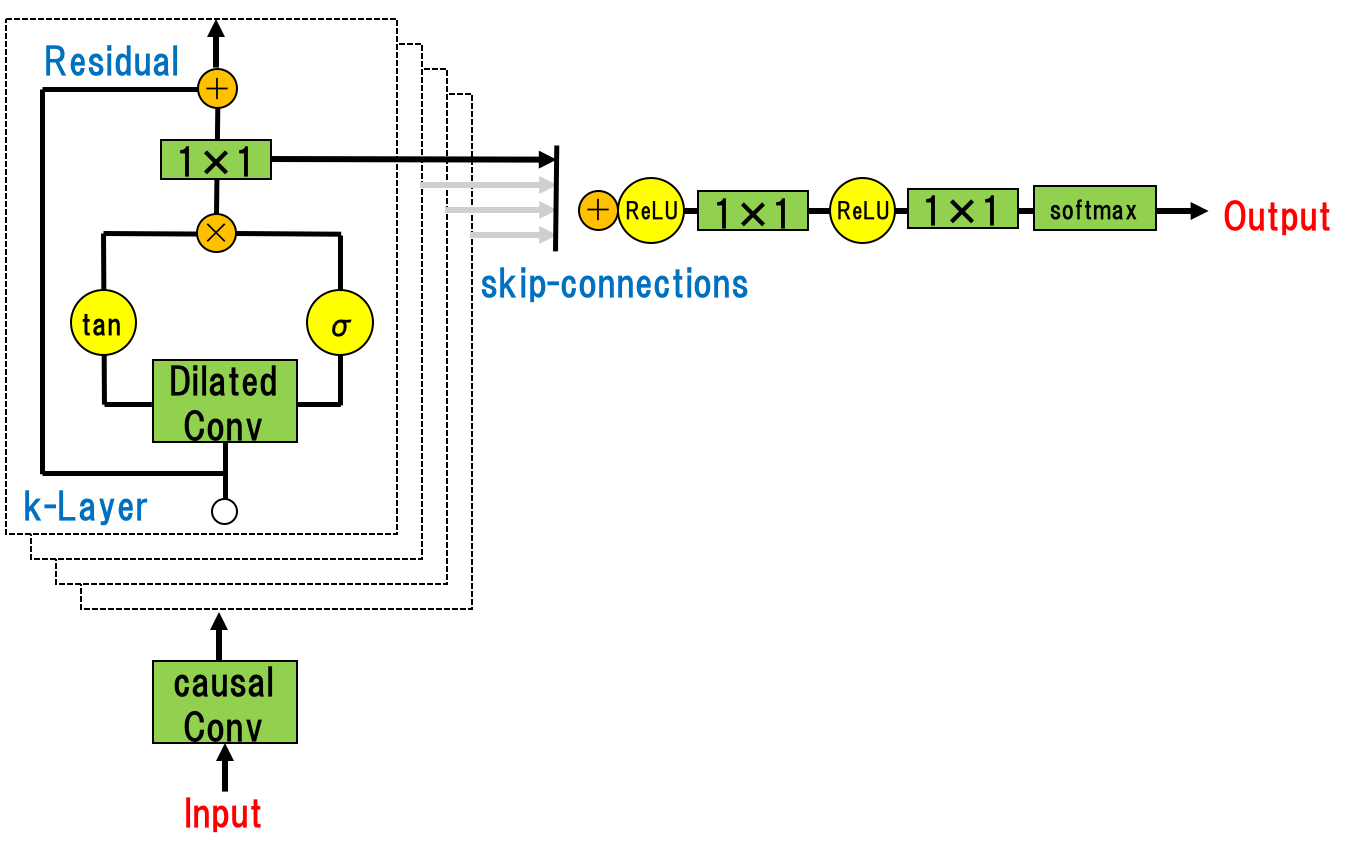
引用 https://arxiv.org/pdf/1609.03499.pdf
〇音声波形の生成モデル
WaveNetでは、生の音声波形に直接作用する新しい生成モデルを導入している。波形 x = {x1, … , xT } は、以下のように条件付き確率の積として因数分解される。
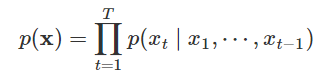
引用 https://arxiv.org/pdf/1609.03499.pdf
したがって、各オーディオサンプルxtは、すべての前のタイムステップでのサンプルを条件としている。
※PixelCNN(van den Oordら、2016a;b)と同様に、条件付き確率分布は畳み込み層のスタックによってモデル化される。ネットワークにはプーリング層はなく、モデルの出力は入力と同じ時間次元を持つ。モデルは、次の値xtに対するカテゴリー分布をsoftmax層で出力し、パラメータに関連したデータの対数尤度が最大になるように最適化される。対数尤度は扱いやすいため、検証セットでハイパーパラメータを調整し、モデルがオーバーフィットもしくはアンダーフィットしているかを簡単に測定できる。
〇Dilated Causal Convolutions
WaveNetのCNNとしての特徴は、時系列データセットに対し、 Convolutionを組み込んでいる点にある。
・Causal CNN
予測分布p(xt+1|x1,⋯,xt)は将来の時間ステップxt+1,xt+2,⋯,xTには依存しない(=Masking)。RNNに見られるような回帰的な接続が無いので、 RNNより学習が速い。
・Dilated Causal Convolution
Causal CNNとは異なり、 層が深くなるにつれて畳み込むユニットをスキップ(離す(=Dilation))仕組みとなっている。ユニットの間を「0」にしてスキップすることは、受容野(時系列過去データをどの程度参考にするか)を最大限広げた状態で畳み込みをする演算を意味する。下画像の例では、入力層から順にそれぞれ0、1、3、7個ずつスキップしながら畳み込みを計算している。また、オンラインでの使用を考慮して、未来のデータを畳み込まないように時系列をシフトさせる。

引用 https://deepmind.com/blog/article/wavenet-generative-model-raw-audio
音声認識・合成技術の代表的なアルゴリズムである「WaveNet」についてまとめた。
音声案内や、音声聞き取りサービスはまだまだ十分な普及がされておらず、
今後の進展が期待できる分野である。