
はじめに
DeepMind社(Google傘下のAI開発企業)がGoogle社と合同でGoogleMapの到着予想に利用する新たな交通量予想モデル「Traffic prediction with advanced Graph Neural Networks」を発表(2020年9月)していたのでその内容についてご紹介したいと思います。
https://deepmind.com/blog/article/traffic-prediction-with-advanced-graph-neural-networks
概要
今回、DeepMind社はGoogleの研究チームと合同で、GoogleMapの到着時間をより正確に推測するモデルをGraph Neural Networksで作成したことを発表しました。今回のモデルによって、下記掲載図からもわかるように世界中で予測精度が大幅に改善されたとのことです。以下では、それまでのモデルの問題点、今回のモデルが作られるまでの経緯、技術的な工夫についてご説明します。
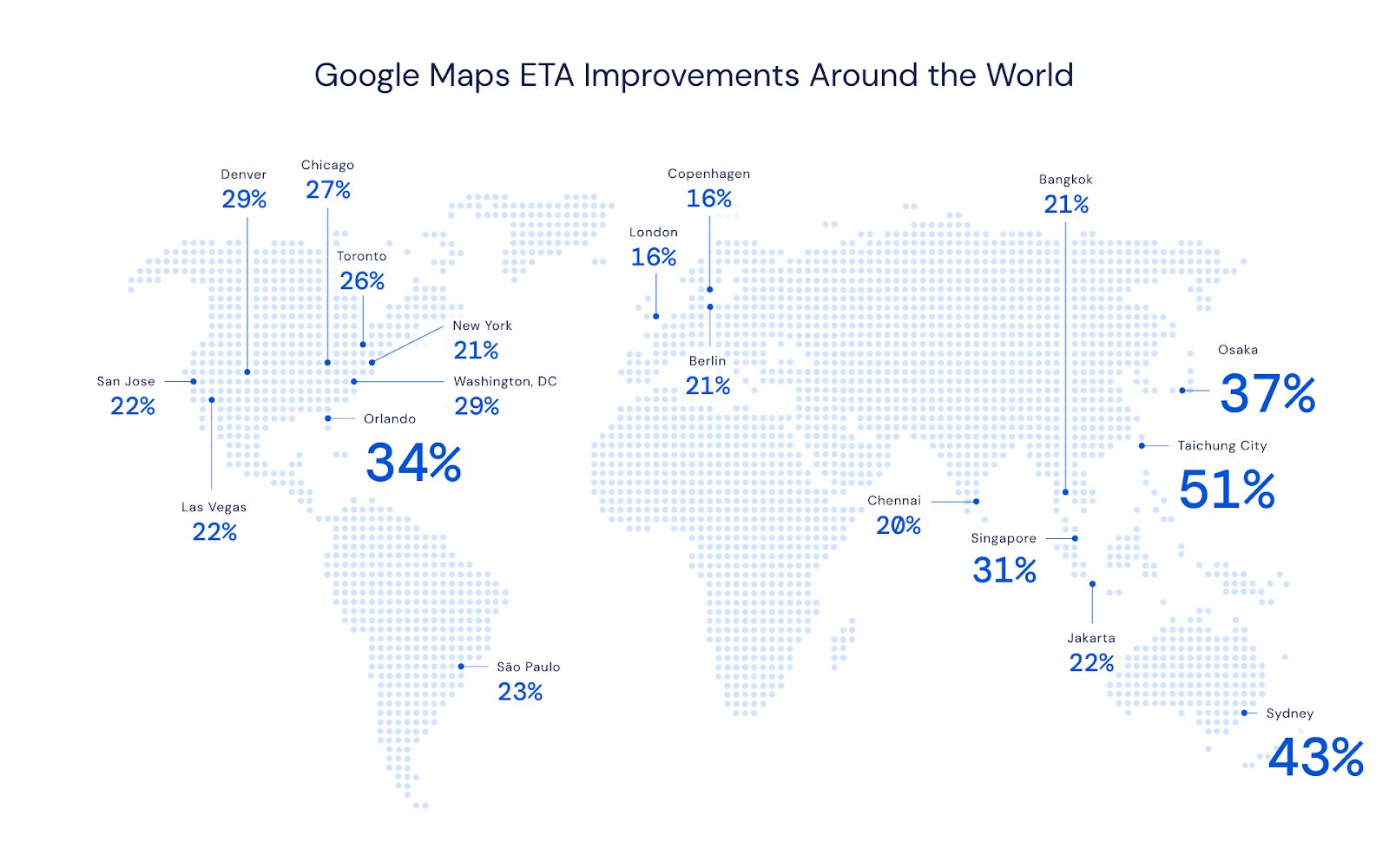
交通量予測の問題点
Googleはこれまでライブの交通量データをもとに予測到着時間を割り出していました。正確な現在の交通量がわかるため97%のドライブでは正確な到着時間を提示することができていたそうですが、ある地域などでは50%以上のドライブに不正確な到着時間を運転者に伝えてしまっていたようです。その原因は、主に事象の複雑性を増す多くの要因にありますが、例えば①ある道路が朝のラッシュなどで混雑することがわかっていてもどれくらい混雑するかは日々大きく異なり、加えて②道路状況、速度制限、事故、閉鎖などが日々変化することで複雑性が増すため、だと説明しています。
そのためDeepMind社では今回汎用性の高いグラフニューラルネットワーク(Graph Neural Networks)を利用しています。このモデルを利用することで、現実の道路ネットワークの接続構造をモデル化するための関係学習バイアスをくみことができ、結果として時空間推論を可能にすることができたそうです。
モデルについて
モデル概要
現在利用しているモデルでは、道路網を交通量の多い道路の隣接する複数のセグメントからなる「スーパーセグメント」に分けています。そして、現在の予想は(1)テラバイトの交通情報を処理してスーパーセグメントを構築するルートを分析し、(2)複数の目的で最適化された新しいグラフニューラルネットワークモデルで各スーパーセグメントの移動時間を予測する、という流れで構成されています。
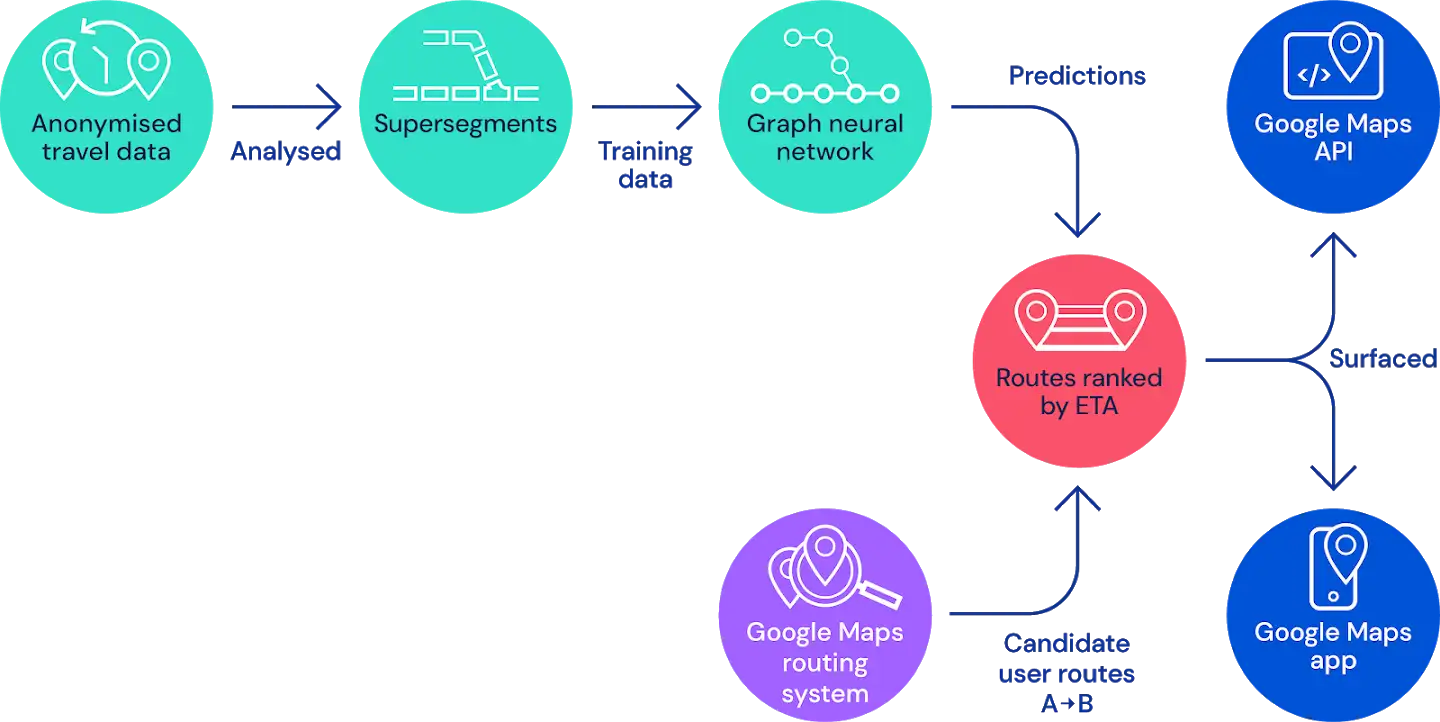
モデルの経緯
スーパーセグメントを用いて移動時間を推定する機械学習システムを作成する際に解決すべき最大の課題は、アーキテクチャ的に関するものだったとしています。
DeepMind社のチームは以下のステップを踏み、現在のグラフニューラルネットワークモデルを利用する形にたどり着いたそうです。
①既存の交通システム(既存の道路網のセグメンテーションとそれに関連するリアルタイムデータパイプライン)を可能な限り利用するというシンプルなアプローチ
はじめにシンプルにリアルタイムの情報を利用して予測するニューラルネットワークモデルを想定しました。このとき、スーパーセグメントは道路セグメントのセットをカバーしていることを意味し、各セグメントは特定の長さと対応する速度の特徴量を持っています。このアプローチでは、各スーパーセグメントに対して単一の完全に接続されたニューラルネットワークモデルを訓練します。結果は有望なものであり、ニューラルネットワークを使用して移動時間を予測できる可能性があることを示していたそうです。
しかし、スーパーセグメントのダイナミックなサイズを考えると、各スーパーセグメントに対して個別に訓練されたニューラルネットワークモデルが必要ということは大きな問題として浮上しました。この問題は世界全体を覆うような大規模に展開するには、モデルを何百万も訓練しなければならず、インフラストラクチャーに大きな課題があることが明らかになりました。
②リカレントニューラルネットワーク(RNN)のような可変長のシーケンスを扱えるモデルによるアプローチ
そこでRNNのような回帰モデルを取り入れることを検討したようです。しかし、道路ネットワークをさらに回帰構造で構成することは難しかったようです。
③グラフニューラルネットワークによるアプローチ
最終的に交通量をモデル化するために、車が道路のネットワークをどのように流れるかということを表せればいいのですが、グラフニューラルネットワークを利用することでネットワークダイナミクスと情報伝播をモデル化することができました。
モデル詳細解説

局所的な道路ネットワークをグラフ、各ルートセグメントをノードとして、同じ道路上で連続しているセグメント間や交差点を介して接続されているセグメント間にエッジが存在するような形でモデルが構成されています。グラフニューラルネットワークでは、メッセージパッシングアルゴリズムが実行され、そのメッセージとエッジやノードの状態への影響がニューラルネットワークによって学習されます。この観点から考えると、スーパーセグメントとは「交通密度に比例してランダムにサンプリングされた道路のサブグラフ」として捉えることができると研究チームは指摘しています。そのため、これらのサブグラフを用いることで単一のモデルとして学習することができ、大規模な展開が可能となったといいます。
グラフニューラルネットワークは、「近接(proximity)」の概念を一般化することで、CNNやRNNによって課せられた学習バイアスを拡張し、前方や後方の交通だけでなく、隣接した道路や交差する道路に沿って任意に複雑な接続を持つことを可能にします。(グラフニューラルネットワークでは、隣接するノードがお互いにメッセージを受け渡します。)この構造を維持することで、ノードが隣接ノードに依存しやすくなるような局所性バイアスを課すことができ、メッセージを渡すステップが1回で済むようになります。これらのメカニズムにより、グラフニューラルネットワークは道路網の接続構造をより効果的に利用することができるようになっています。
DeepMind社の実験では、主要道路の一部ではない隣接道路を含むように拡張することで予測力が向上することが実証されています。(例えば、脇道で渋滞が発生するということは、より大きな道路の交通量が増えることを意味しており、情報の拡充は精度の向上に寄与します。)複数の交差点にまたがることで、モデルは、曲がり角での遅延、合流による遅延、ストップアンドゴー交通での全体的な横断時間をネイティブに予測する能力を獲得することができます。このように組み合わせた空間全体の情報を一般化して利用することができることがグラフニューラルネットワークの性能を支えているといえます。(単純な2セグメントのルートから何百ものノードを含む長いルートまで、長さも複雑さも異なる各スーパーセグメントは同じグラフニューラルネットワークモデルによって処理されます。)
商用利用するための工夫
今回のモデルは、Google Mapという世界でも最大規模の商用サービスに利用するモデルということで学術研究では見過ごされがちな点にも注意が払われています。
注視されたのは、同じモデルを複数のトレーニングランでまわしたときに生じるばらつきについてです。一般的に学術研究の現場では初期設定の問題として見過ごされがちですが、Google Mapのような巨大なモデルで多くの利用者がいる場合、その差は大きな問題を生むことが予想されます。DeepMind社の今回の研究ではそうしたばらつきに対してよりロバストなものにするために、多くの取り組みがなされたということです。
研究チームによってばらつきをうむ主な原因は、「トレーニング中に使用されるグラフ構造に大きなばらつきがあること」が指摘されています。そして、この問題を強化学習技術を教師あり学習として利用するというアプローチで研究チームは解決しました。
機械学習システムを訓練する際、学習率はシステムがどれだけ「可塑的」であるか、あるいは新しい情報に対して変化しやすいかを規定しています。研究者は、新しいことを学ぶことと、すでに学んだ重要な特徴を忘れてしまうこととの間にはトレードオフがあるため、モデルの学習率を時間の経過とともに下げていくことがよくあります。(これは機械学習の世界で一般的な言い方をすると、学習率を大きくすると学習の収束は早まりますが、一方で最適解にたどり着けず低い予測精度のモデルになる可能性があることを言っています。そのため、多くの場合、途中で学習率をさげていくことで学習の収束=最適解にたどり着くようにしています。)DeepMindの研究チームもはじめは事前に定義された学習期間の後にパラメータを安定させるために、指数関数的に減衰する学習率スケジュールを使用し、またトレーニング実行間のモデルの分散を減らすことができるかどうかを確認するために、以前の研究で効果的であることが証明されているモデル・アンサンブル技術を探索し、分析していたとのことです。しかし、このアプローチそのものを改良することが問題の解決につながりました。
いろいろな取り組みをした結果、最終的にこの問題に対する最も成功したアプローチは、メタ勾配(MetaGradients)を使用してトレーニング中に学習率を動的に適応させることであったと研究チームは報告しています。メタ勾配を利用することで効果的にシステムに最適な学習率スケジュールを学習させることができます。学習中に学習率を自動的に適応させることで、モデルは以前よりも高い品質を達成しただけでなく、学習率を自動的に減少させることも学習しました。これにより、より安定した結果が得られ、本番での利用が可能になったと報告しています。
損失関数によるモデルの汎化能力の向上
研究チームは今回モデルを構築する上で、(適切に重み付けされた)複数の損失関数を線形に組み合わせて使用することで、モデルの汎化能力が大幅に向上することがわかったと報告しています。
具体的には、
①モデルの重みの正則化係数
②グローバルなトラバーサルタイムのL2損失とL1損失
③グラフ内の各ノードの個々のHuber損失とNLL損失
を使用して、複数の損失目的を定式化したとのことです。
これらの損失を組み合わせることで、モデルが過学習することが抑えらたとのことです。なお、研究チームはドライブ時間の推定誤差の減少を指針指標として、メタ勾配技術を使用することで、学習中に多成分損失関数の構成を変化させることができるかどうかを現在検討しているようです。この研究は、強化学習で成功を収めたMetaGradientの取り組みに触発されており、初期の実験では有望な結果が得られたとしています。
まとめ
日々何気なく利用していることが多いGoogleのサービスですが、その裏では日々多くの改良が加えられています。どのような改良がくわえられたのかを知ることは次のサービスをイメージする助けにもなるのではないでしょうか。また今回の発表では、様々な分野の研究結果が横断的に利用されており特定の分野だけではなく広くアンテナ張る必要性があることを改めて感じられました。今後も、最新モデルについて紹介していきたいと思います。