
はじめに
物体検出の世界でリアルタイム処理を可能にし、現在でも主力として活躍するYOLOシリーズについて解説したいとおもいます。
YOLOは2015年6月に Joseph Redmon氏によって“You Only Look Once: Unified, Real-Time Object Detection”という論文で発表され、その革新的な性能とシンプルなモデル構成から瞬く間に普及しました。(TEDでJoseph Redmon氏が物体検出について講演されていますので、興味がある方はご確認ください。「How computers learn to recognize objects instantly」なお、この「YOLO:You Only Look Once」というタイトルは「YOLO:You Only live Once」という俗語(スラング)からきているそうです。)物体検出のタスクに取り組んだことのある方であれば、一度は試したことがあるモデルといっても過言ではありません。今回は、YOLOの仕組みやその革新性についてシリーズごとに解説したいと思います。
ここで注意として、YOLOはその後次々に新たなヴァージョンが発表され(2020年9月現在v5まで確認)、ヴァージョン毎にモデル構造が異なります。そのうえ、オリジナルの制作者であるRedmon氏はv3までは制作に関与していますが、v4以降は全くの別人が引継ぎ、制作・発表しています。(Redmon氏は、自身の研究が軍事利用に転用されること、またプライバシーの侵害につながっていることなどから途中で研究を中止しています。)
v4に関しては Joseph Redmon氏の知り合いでYOLOのベースとなっているDarknetというアーキテクチャの管理などにかかわっていたAlexey Bochkovskiyという人物が開発者です。こちらは論文が発表されており、モデルの発表元としての信頼性が担保されているといえます。
v5はUltralytics LLC(https://www.ultralytics.com/)というスペインの企業が発表したものですが、論文や詳細情報がなく、Redmon氏とのかかわりも不透明でその正当性に関して問題視する意見がウェブ上で存在しています。また性能に関してもv4の方がよいという比較結果を載せているウェブサイトもみられ、v5はその立ち位置などを含め取扱い方が難しいといえます。モデルはウェブ上にオープンにされているので、実際に自身でご利用して判断されるのが一番かとおもいます。
上記の理由により、今回はRedmon氏がかかわっているv3まで解説したいと思います。
| モデル名 | origin | v2 | v3 | v4 | v5 |
|---|---|---|---|---|---|
| 発表年 | 2015/06 | 2016/12 | 2018/04 | 2020/04 | 2020/05 |
| 制作者 | Joseph Redmon | Joseph Redmon | Joseph Redmon | Alexey Bochkovskiy | Ultralytics LLC |
| 論文名 | You Only Look Once: Unified, Real-Time Object Detection | YOLO9000: Better, Faster, Stronger | YOLOv3: An Incremental Improvement | YOLOv4: Optimal Speed and Accuracy of Object Detection | |
| 論文URL | https://arxiv.org/abs/1506.02640 | https://arxiv.org/abs/1612.08242 | https://arxiv.org/abs/1804.02767 | https://arxiv.org/abs/2004.10934 | |
| 実装用URL | https://pjreddie.com/darknet/yolov1/ | https://pjreddie.com/darknet/yolov2/ | https://pjreddie.com/darknet/yolo/ | https://github.com/Tianxiaomo/pytorch-YOLOv4 | https://github.com/ultralytics/yolov5 |
YOLO(v1)
YOLOは2015年に、「You Only Look Once: Unified, Real-Time Object Detection」という論文で発表されたモデルです。ほぼ同時期に発表されたFast R-CNNと同様に、物体検出の世界に大きな影響を与えました。両者が発表されて以降、End-to-Endモデルとリアルタイム検出が物体検出のスタンダードになったといえます。
YOLO(v1)の特徴
YOLOの特徴についてみていきます。
・それまで二段階(検出と識別)で行われていた物体検出を一度の作業(全体を検出)にすることで高速化に成功した。
・End-to-Endモデルの最初期モデル。
・検出速度がリアルタイムで実用可能な45fpsになった。(精度は下がるが、検出速度がよりはやいFastYOLOでは155fpsに達した。)
なお同時期に出されたFast R-CNNと比べると、
+より高速に検出できる
+背景と物体を区別する精度が高い
+汎用性能が高い(芸術作品など自然なものでなくてもFast R-CNNよりも精度を維持できる)
+よりシンプルなモデル構造
-精度が低い
-小さな物体の検出が苦手(グリッドセルを用いているため)
となっています。
モデル構造
とくに、YOLOはそれまでの境界設定と物体検出という二段階で行われていた作業を一度に行うという点に革新性があります。(そのことでEnd-to-End型かつ高速化に成功しました。)それゆえにYou Look Only Onceというタイトルになっています。
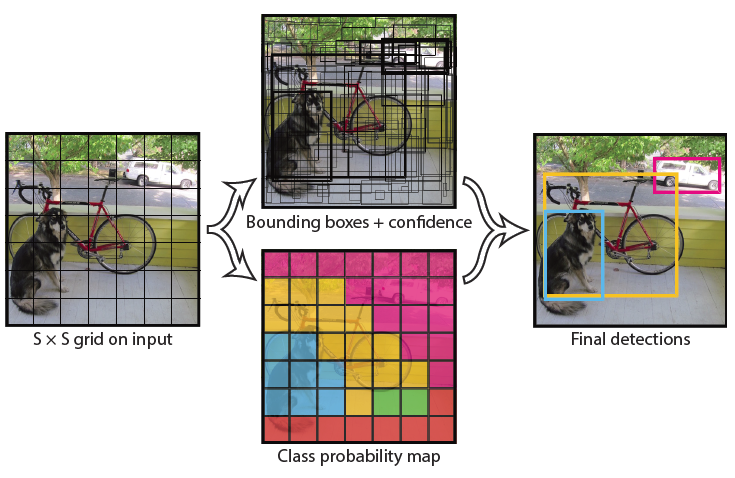
①S*Sのグリッドセル(grid cell)に分割
YOLOはR-CNNのように候補領域検出を行わない代わりに、入力画像をS*Sのグリッドセルに分割します。(なお、論文ではS=7に設定されています。)物体の中心がグリッドセルにある場合、そのグリッドセルがその物体を検出するように学習していきます。
②バウンディングボックスの推定
各グリッドセルは、B個のバウンディングボックス(あらかじめ設定されるもので、論文ではB=2に設定されています)を持ち、それらのボックスの信頼スコアを予測します。信頼スコアは、ボックスに(背景ではなく)物体(Objects)が含まれているかの確率を示すものです。1に近づくほど物体がある可能性が高いことを意味します。
各バウンディングボックスは、座標値(x、y、w、h)と、信頼(confidence)スコアの5つの予測で構成されています。
・x、y座標は、グリッドセルの境界を基準にしたボックスの中心を表します。
・幅wと高さhは、画像全体に対する相対値を表します。
・信頼スコアは、予測されたボックスと正解ボックスの差を意味しています。
③物体の予測
各グリッドセルはC個のクラスに対する条件付きクラス確率P(Class | 物体)を予測します。(論文ではC= 20です。)ここで計算された「条件付きクラス確率」とひとつ前の「個々のバウンディングボックスの信頼スコア」を掛け合わせることで、バウンディングボックス毎のクラスに対する信頼スコアを得ることができます。この信頼スコアに基づいて、どのバウンディングボックスが正解の物体を検出しているかを判断します。
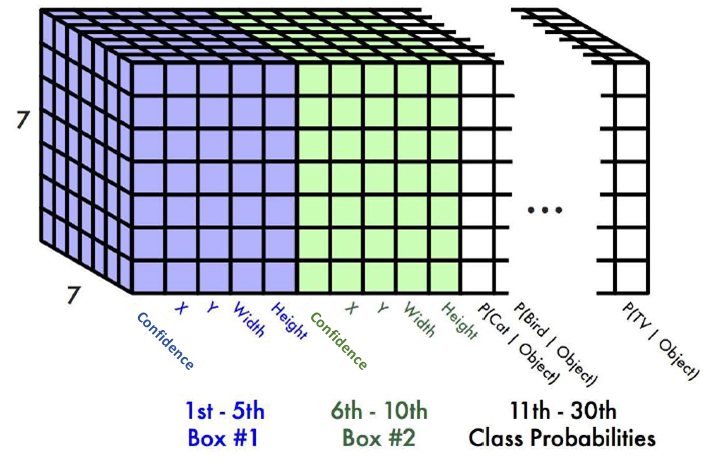
④選別する
信頼度の高いBounding Boxを基準にNMS(Non-Maximum Suppression)という手法で選別しています。NMSは、IoU値が大きい(重なり度合いの高い)領域をしきい値で抑制します。
モデルアーキテクチャ-Darknet
モデルアーキテクチャはDarknetと呼ばれており、24層のCNNと4層のPooling層から特徴量を抽出し、2つの全結合層で物体のバウンディングボックスと種類を予測しています。CNNの最終出力サイズがS*S*Cになり、グリッドセルとクラスと同じ数になるように設定されています。なお、Fast YOLOでは層の数を24から9に減らすことで高速化しています。
また、最終層を除いて活性化層はLeaky ReLUを利用しています。

損失関数

引用:https://towardsdatascience.com/yolov1-you-only-look-once-object-detection-e1f3ffec8a89
1.x、y:バウンディングボックスのx座標とy座標は、0ー1の区間で表記されています。また、二乗誤差の合計(SSE)は、物体がある場合にのみ推定されます。
2.w、h:バウンディングボックスの幅と高さは、画像の幅と高さによって正規化され、0と1の間に収まります。こちらもSSEは、物体がある場合にのみ推定されます。また大きなボックスと小さなボックスでは差の重要度が異なるため、wとhには平方根が利用されています。
※なお、どちらもバウンディングボックス座標予測からの損失を増やすためにλcoord= 5に設定しています。理由は下記信頼スコアと同じ。
3.信頼スコア(つまり、予測ボックスと正解ラベル間のIOU):あらゆる画像におけるほとんどのグリッドセルには物体が含まれていません。そのため、ほとんどのグリッドセルの信頼スコアがゼロに近づき、わずかに物体が含まれているグリッドセルからの勾配が圧倒されてしまい、モデルが不安定になるという問題があります。そのため、物体を含まないボックスの信頼スコア予測による損失を減少させ、λnoobj = 0.5としています。
4.クラス確率:物体が存在する場合のクラス確率のSSEとなります。
実験
学習について
最初のCNNはImageNetによって事前トレーニングされ、1週間で上位5つのモデル精度が88%になったとしています。次に、ネットワークは、PASCAL VOC 2007および2012のデータセットで約135エポックにわたって学習されています。(なお2012でテストする場合、トレーニング用のVOC 2007テストデータも含まれます。)
各種設定:S = 7 / B =2 / C=20 / バッチサイズ = 64
各モデルの実験結果(Titan X GPUを使用)
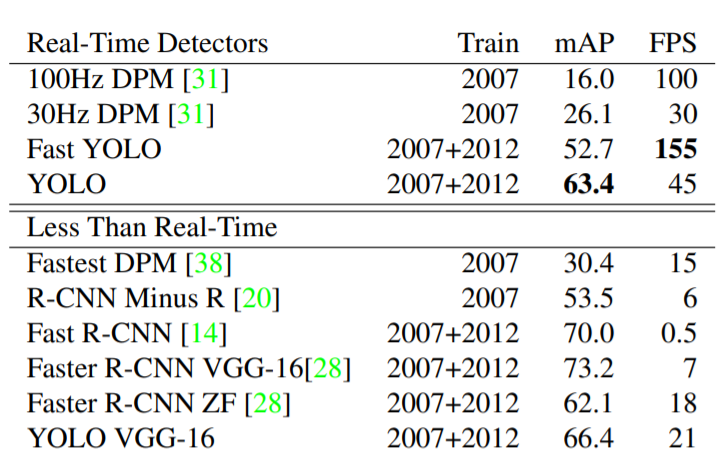
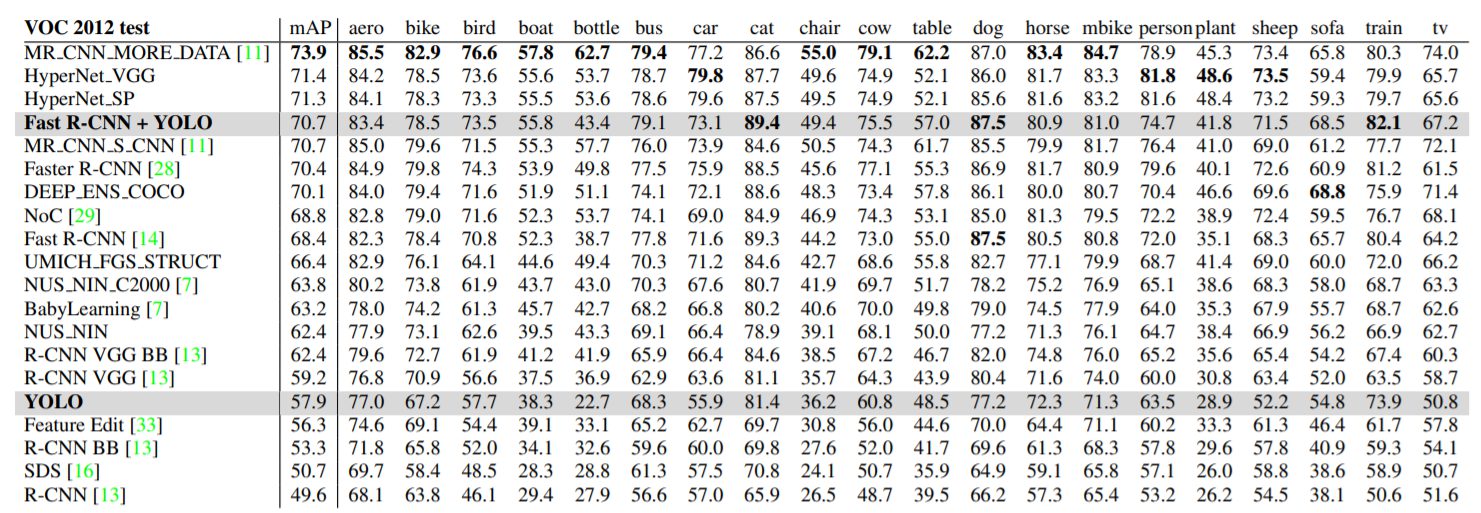
YOLO:63.4 mAP・45 FPS。
⇒DPM、R-CNN、Fast R-CNNおよびFaster R-CNNと比較して、YOLOは同様のmAPでリアルタイムのパフォーマンス(45FPS)を得ることができています。
Fast YOLO:52.7mAP・155 FPS。
⇒高いFPS値でありながら、100Hz DPMと比較して、mAPが非常に高いといえます。
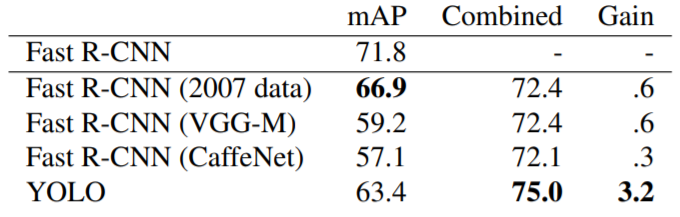
YOLOとFast R-CNNの組み合わせ
なお、論文ではYOLOとFast R-CNNにはそれぞれの長所と短所が異なり、組み合わせてより高い精度を得ることができることが示されています。(Fast R-CNNはクラス予想の精度が高く、対してYOLOは背景と物体の識別の精度が高いという特徴があります。)
汎用化について
実験では、R-CNNがVOC 2007で高いAPを持っているのに対して、芸術作品などに適用するとR-CNN の精度が低下することが示されています。それに対してYOLOは精度の低下はそこまでではないことが示されています。
R-CNNの精度が低下するのは、自然な画像に調整されたバウンディングボックスを選択検索に使用しているためだと考えられます。対して、YOLOは芸術作品と自然な画像はピクセルレベルで大きく異なっているものの、物体のサイズと形状の点では似ているため、適切なバウンディングボックスと物体検出の予測ができるとしています。

YOLOv2(YOLO9000)
YOLOv2は、2016年に発表された「YOLO9000: Better, Faster, Stronger」という論文で紹介されています。この論文では、YOLOv2とYOLO9000の二つがモデルとして提案されています。YOLOv2はYOLOの改良モデルで、YOLO9000はYOLOv2を下敷きにより多種類を分類できる(その名の通り、9000分類です)ようにしたモデルです。基本的な発想やアーキテクチャはオリジナルのYOLOとほとんど変わっておらず、細かい改良を加えることで精度と処理速度を向上させています。
モチベーション
YOLOv2を開発しようとした理由に、当時の最先端モデルであるFast R-CNNなどと比べて、従来のYOLOは再現率(recall)と領域分離(localization)の精度が低いことを指摘しています。そのため、クラス分類の精度を維持したままで、両者を上げることが中心的な目標であるとしています。
工夫
YOLO(v1)に加えられた工夫についてみていきます。
バッチノーマライゼーション(Batch Normalization)
各CNNにノーマライゼーションを追加しました。
・mAPが2%向上した。
・モデルの過学習の抑制にも効果あり。
・学習の収束が早くなる。
高解像度の分類器(High Resolution Classifier)
448*448の解像度の画像で分類器を事前学習させました。
・mAPが4%向上した。
アンカーボックスの導入(Convolutional With Anchor Boxes.)
アンカーボックスを用いてバウンディングボックスを推定しました。
・mAP精度は下がったものの再現率は上昇した。
・そのため、まだ改善の余地があることがわかった。
⇒精度が下がったため、結局採用されず次の下の二つの工夫が行われました。
領域分類(Dimension Clusters)
アンカーボックスが人間の手で作られているということに問題があると考え、代わりに、K-means分類で学習用のバウンディングボックスをつくりました。
・K=5くらいがモデルの複雑性と再現性のバランスがもっとも取れていた。
・なお、K=9にするとより高いIOUを獲得することができ、よりよい表現性を獲得している可能性がある。
直接位置予測(Direct Location Prediction)
モデルが不安定になる(特に初期の学習)という問題があり、ほとんどの不安定性はx、y座標の位置予測の問題からくるため、YOLO型のグリッドセルを用いた予測を利用することにしました。
・領域分類と組み合わせると、5%ほど中心座標の予測が改善された。
細かい特徴量(Fine-Grained Features)
連結層を追加しました。
⇒基本的には13*13の特徴量マップで十分だが小さい物体を見つけるために26*26の解像度が必要となるときに、連結層(passthrough layer)を追加するだけで高解像度の特徴量と低解像度の特徴量を連結することができます。(26*26*512を13*13*2048に変換します)
・1%の性能向上を実現した。
マルチスケールトレーニング(Multi-Scale Training)
320~608までの様々なスケールをランダムに学習させました
・サイズ変更にロバストなモデルとなった。
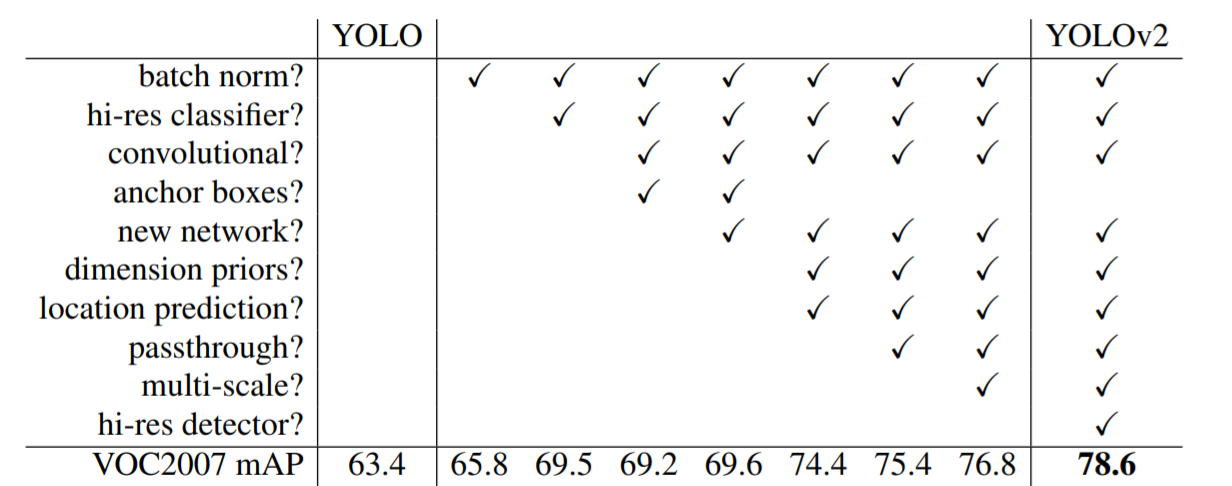
下記図は最終的に採用した工夫とその結果を示す図です。
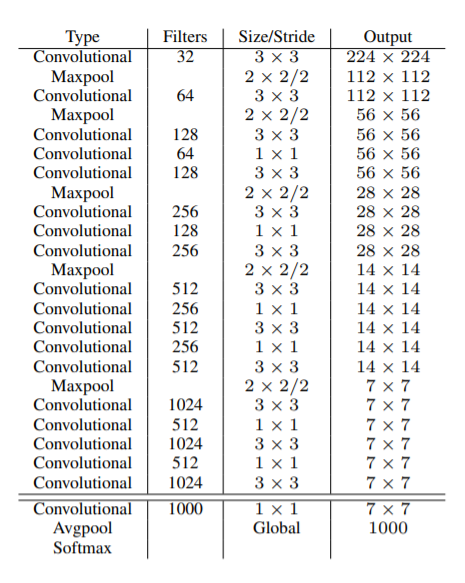
モデルアーキテクチャ—Darknet-19
基本的に利用している層などはYOLO(v1)と同じです。組み方などが多少変わりました。今回のアーキテクチャは19のCNNと5のプーリング層が利用されています。(そのため、名称はDarknet-19としています。)より高速化しました。
なお、ハイパーパラメータは(learning rate = 0.1 / polynomial rate = 4 / weight decay = 0.0005 / momentum = 0.9 )と設定されています。
YOLO9000のために
大規模な分類を行うとき、ひとつの問題としてデータセットのラベルの重なりなどから単純にsoftmaxを全項目に使うと、相互排他的ではない項目が相互排他状態になってしまうという問題があります。(例えば、犬とシベリアンハスキーは相互排他的ではなく包括関係にあります。)
YOLO9000では、Wordnetを利用することで、相互排他的な分類になることを回避し階層的な分類になるように変更しました。一度に全て判別するのではなく、段階的に判別していきます。
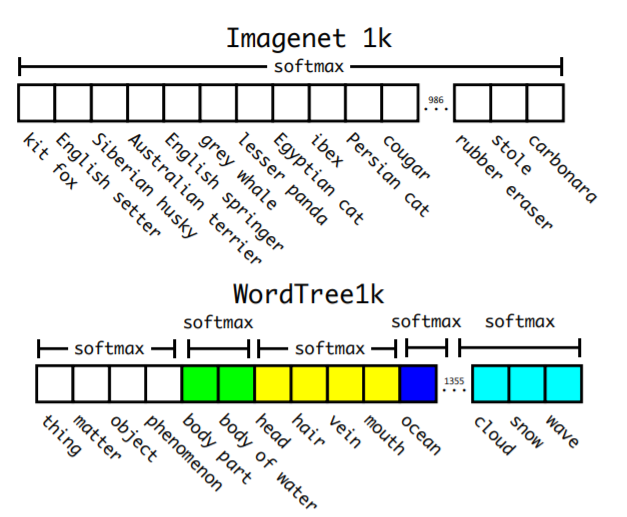
なおWordNetは複雑な言語ネットワークを表現するためのものであるため有向グラフ型であって、ツリー型ではありません。しかし、問題を簡略化するために、ImageNetに付与するときは簡単なツリー型(⇒WordTree)にするという工夫をしています。そのうえ、WordTree型にすれば、いろいろなデータセットを組み合わせて使うことができるようになります。
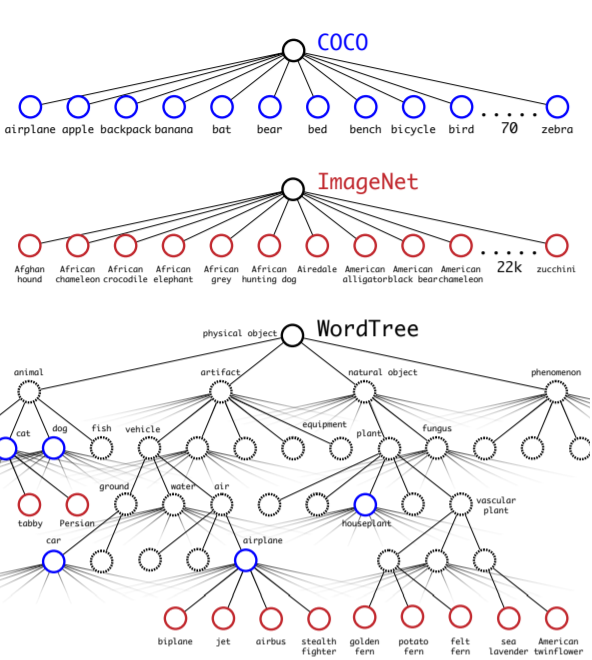
YOLO9000の実験
なお、このWordTreeを利用することでデータセットをくみあわせることができるようになり、物体検出用のデータセットであるCOCOデータセットと分類用のImageNetを同時に学習させることができるようになりました。論文では二つを組み合わせてYOLO9000学習させたうえで、検出タスクで評価しています。
この二つを同時に訓練させたモデルYOLO9000に対して、ImageNetの検出タスクで評価しました。ImageNetの検出タスクはCOCOと44種類のオブジェクトカテゴリを共有していますが、YOLO9000は検出データではなく、テスト画像の大部分の分類データしか見ていないという前提のもと、YOLO9000は全体で19.7 mAP、ラベル付けされた検出データを見たことがない156のオブジェクトクラスについては16.0 mAPという値を出しました。このmAPはDPMで達成された結果よりも高くなっていますが、それだけでなくYOLO9000は部分的な教師ありのみで異なるデータセットで訓練されているというハンデがありました。また、9000個の他のオブジェクトカテゴリも同時に検出しており、すべてがリアルタイムで行われているという点も評価できます。
YOLO9000の性能をImageNet上で分析すると、新種の動物をよく学習しますが、衣類や装備品のようなカテゴリの学習には苦戦していることがわかります。(下図参照)特にYOLO9000は様々な動物については汎用力のある形で学習していますが、衣服や装備品のような分野では苦戦しています。動物の方が学習しやすいのは、COCOの動物から客観性の予測がよく一般化しているからであり、逆にCOCOにはどんな種類の服であっても、人の服だけのバウンディングボックスのラベルがないので、YOLO9000は「サングラス」や「スイミング・トランクス」のようなカテゴリのモデル化に苦労していると考えられます。

YOLOv3
YOLOv3は2018年に「YOLOv3: An Incremental Improvement」という論文で発表されました。(なお個人的な印象ですが、もともと硬い論調を好んでいなかった様子はありましたが結果として最後になった本論文ではもはや学術論文ではなく一人のエンジニアの手記といっていいほど軽い感じで書かれていることが印象に残る論文です。)ただし、この論文で作者自身が述べているようにv2からそこまで大きな変化はしておりません。
YOLOv3では、新しい分類器が設定されました。この分類器では80種類を分類できます。YOLOv3には認識精度の高い通常モデルと、認識精度が若干劣る代わりに高速に動作するtinyモデルがあります。通常モデルのYOLOv3–416のmAPは55.3、tinyモデルのmAPは33.1となります。
YOLOv3の工夫
バウンディングボックス予測
YOLOv2に引き続き、k-means法を用いてバウンディングボックスを予測する手法を用いています。座標の学習には、SSEを利用しています。物体があるかどうかは、ロジスティック回帰を利用して物体スコアを予測しています。(1に近づくことが目標)
クラス予測
ソフトマックスを使わずに、ロジスティック回帰を利用しています。損失関数には二値クロスエントロピー損失を利用しています。これらのことで、より複雑な領域をもつデータセットに対応することが可能になりました。
スケール間予測
YOLOv3では、3つの異なるスケールで画像を予測していきます。(そのために、3つの3次元のテンソルを利用しています。)このスケールが異なる構造は画像内の物体のサイズが異なっていても対応できるようにするためのものです。(下記図Feature Pyramid Networks:FPNというモデルを参照して作られています。)このモデルは異なる層で異なる特徴量が取得されていることに注目したものです。SSDなどにも実装されていますが、YOLOv3では、特徴量マップは前の2つの層から取得され、2倍にアップサンプリングされてます。このことでより意味のある情報を取得し、より詳細な情報を取得することができます。また、いくつかのCNN層が追加され、サイズが2倍になっています。これらのスケールでは、バウンディングボックスの座標、物体の有無、クラス予測が予測されています。論文では、COCOデータセットに対して、各スケールに3のボックスが設定されたため、N*N*(3*(4+1+80))という形のテンソルが出力されることになります。
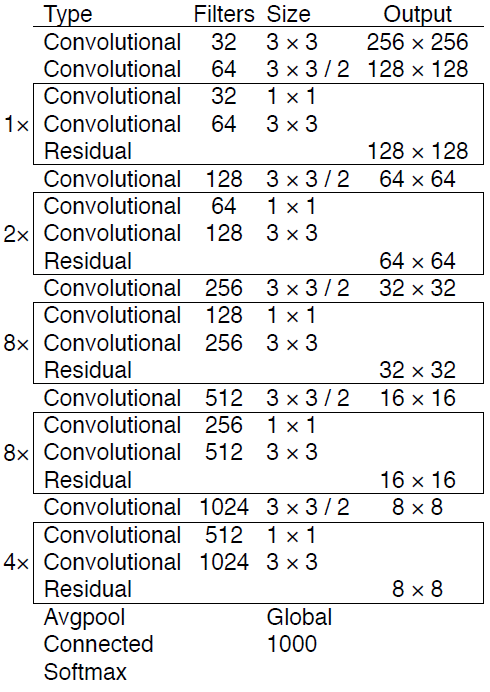
ネットワークアーキテクチャ
主に53層のCNNから構成されています。そのためDarknet-53と呼称しています。またv2と同様にバッチ正規化も利用されています。全結合層を使わないので入力画像のサイズが任意となっています。YOLOv3では、新たにResNetとFPN構造を利用して検出精度を更に向上させています。
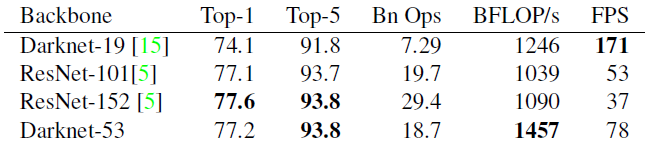
実験
ImageNetを用いた実験結果は以下のようになっています。ResNet-101と比較すると、Darknet-53の方がパフォーマンスが優れているうえで、1.5倍高速です。ResNet-152と比較すると、Darknet- 53のパフォーマンスは同程度で2倍高速であることがわかります。特徴としてはより高速を求めている点にあります。
まとめ
YOLOはその性能やシンプルさから物体検出の世界ではひとつの潮流をつくっています。もともとの開発者が開発をやめてしまうということがありながらも、現在(2020年9月)も新たなv4やv5がつくられるなど、その系譜は力強く残っていきそうです。