はじめに
Google、ケンブリッジ大学、DeepMind社、アラン・チューリング研究所で構成された研究チームが、Transformerの効率的演算モデル「Performers」を2020年9月30日に「Rethinking Attention with Performers」という論文で発表しました。Transformerの効率的演算モデルとしては、Open AIが提案したSparse Transformer(「Generative Modeling with Sparse Transformers」)が主流ですが、一方で表現力に対して厳密な理論的保証がないなど問題点も指摘されていました。今回発表されたPerformersはスパース性を利用しないことで、Sparse Transformersがかかえている問題を克服することを目指しています。
Rethinking Attention with Performers
https://arxiv.org/abs/2009.14794
【Google Blog】
Rethinking Attention with Performers
https://ai.googleblog.com/2020/10/rethinking-attention-with-performers.html
【Github】
Performer’s Fast Self Attention Module.
https://github.com/google-research/google-research/tree/master/performer/fast_self_attention
背景
Transformerは自然言語処理分野で誕生しましたが、現在では画像処理や音楽処理など幅広い分野で使われています。しかし、分野が異なっても基本的に使われているTransformerアーキテクチャのコアブロックはAttentionモジュールです。Attentionモジュールでは、入力シーケンス間のすべての類似度スコアを計算します。しかし、入力シーケンスの長さに応じたスケーリングが不十分であるため、①すべての類似度スコアを生成するために二次的計算時間がかかることと、②これらのスコアを格納する行列を構築するために二次的メモリサイズが必要、という問題が生じています。ここでいう二次的とは、入力データの総要素数をNとすると、自身も含むN個同士の関係性をすべて計算するため、N×Nの計算コストとメモリサイズが必要であるということを意味しています。
従来の対応――Sparse Attentionの採用――
メモリーキャッシュテクニックによるいくつかの高速でよりスペース効率の良いプロキシ(Transformer-XLなど)も提案されていますが、基本的にはSparse Attentionが主流となっています。Sparse Attentionを利用したモデルには、「Sparse Transformers」「 Longformers」「 Routing Transformers」「Reformers」「Big Bird」などがあります。
Sparse Attentionは、入力データ間のすべての可能なペアではなく、類似度スコアの中から選択的に計算することにより、計算時間とメモリ要件を削減します。そのため、完全な行列ではなく疎(Sparse)な行列になります。スパースな行列はグラフやエッジで表すこともできるため、スパース化の方法もグラフニューラルネットワークの文献によって動機付けられています。Attentionとの特定の関係は特にGraph Attention Networksで概説されています。このようなスパース性ベースのアーキテクチャでは、通常、完全なAttentionメカニズムを暗黙的に生成するために追加のレイヤーが必要とされます。
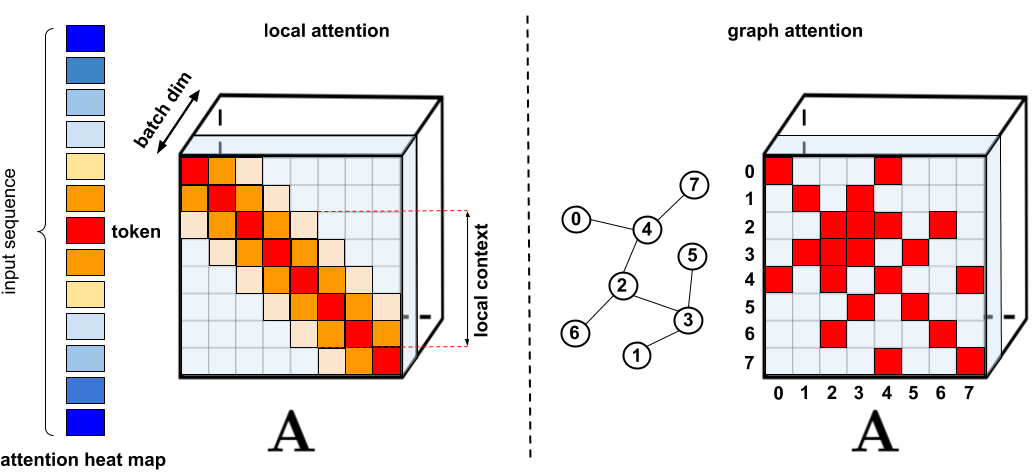
Sparse Attentionの問題点
ただし、Sparse Attentionには以下の問題点があることが指摘されています。
①効率的なスパース行列乗算演算が必要ですが、すべてのアクセラレータで使用できるわけではありません。
②Sparse Attentionの表現力に対して一般的に厳密な理論的保証がなされていません。
③Sparse Attentionは主にTransformerモデルと生成的事前学習用に最適化されてしまっています。
④通常、スパース表現を補正するためにより多くのAttention層を積み重ね、他の事前学習済みモデルでの使用を困難にします。そのため、再学習にかなりの労力の消費を必要とします。
これらの欠点に加えて、Sparse Attentionメカニズムは、通常のAttention方法が適用される問題の全ての範囲に対処できるわけではありません。また、一般的に使用される(Attentionモジュールの類似性スコアを正規化する)ソフトマックス関数などが、スパース化できない演算としてあるという問題もあります。Performersはスパース性を取り入れることに生じる問題を解決するために考案されました。
Performers
スパース性を取り入れることによって生じる上記の問題を解決するために、線形にスケーリングするAttentionモジュールを備えたTransformerアーキテクチャであるPerformersが提案されました。これにより、ImageNet64などの画像データセットおよびPG-19などのテキストデータセットなどより長い処理を必要とするデータセットに対しても、より高速な学習を可能としました。
Performersは、効率的な(線形)Generalized Attentionフレームワークを使用します。これにより、さまざまな類似性の尺度(カーネル)に基づいた幅広いクラスのAttentionメカニズムが可能になります。このフレームワークは、「Positive Orthogonal Random Features(FAVOR +)」アルゴリズムを介した新しいFastAttentionによって実装されます。
このアルゴリズムによって、ランダムな特徴マップ分解(特に、正規化されたソフトマックスAttention)によって表現されるAttentionメカニズムのスケーラブルな低分散かつ偏りのない推定が提供されます。線形空間と時間の複雑さを維持しながら、強力な精度保証を取得することができます。これは、スタンドアロンのソフトマックス操作にも適用することができます。
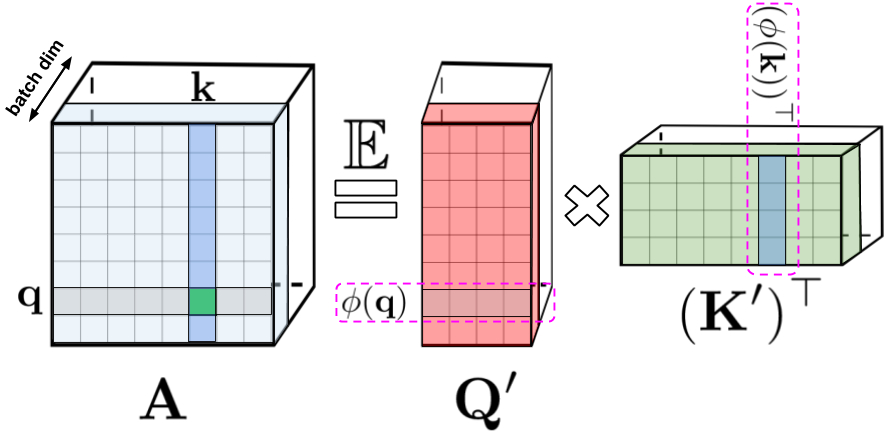
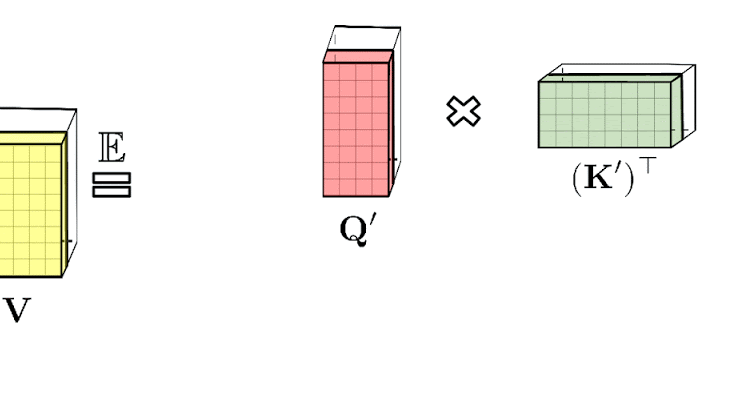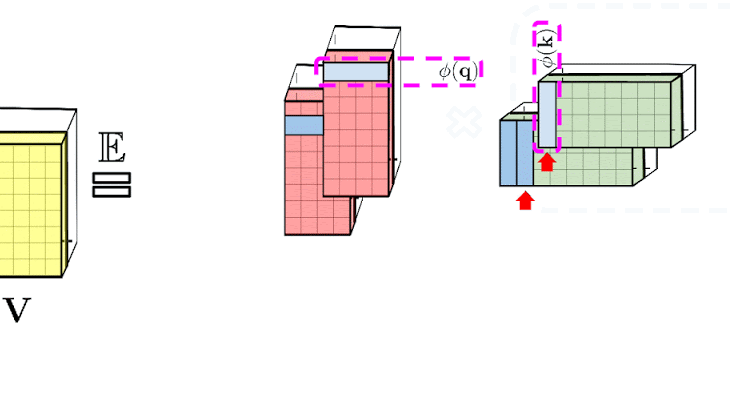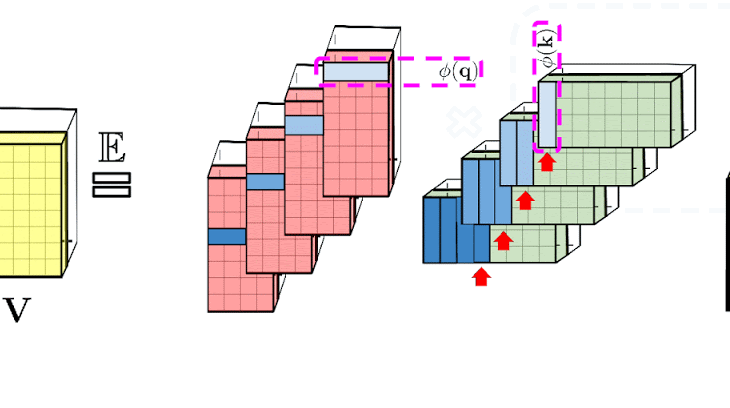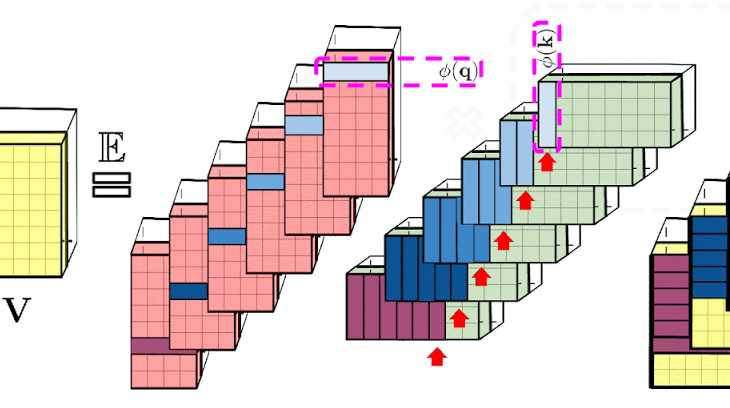
普通のAttentionメカニズムでは、マトリックスの行と列にそれぞれ対応するクエリ(query:上図中央)とキー(key:上図右部)の入力が乗算され、softmax演算を通過して、類似スコアを保存するAttentionマトリックス(上図左部)が形成されます。この方法を用いた場合、クエリとキーによるプロダクトを非線形ソフトマックス関数に渡した後、元のクエリとキーに分解することはできません。しかし、Attentionマトリックスを分解して、元のクエリとキーのランダムな非線形関数の積に戻すことは可能です。これは、ランダム特徴(random features)とも呼ばれ、これにより、類似性情報をより効率的な方法でエンコードすることができます。
ソフトマックスAttentionは、指数関数とガウス射影によって定義されるこれらの非線形関数の特殊なケースと見なすことができます。より一般的な非線形関数を最初に実装し、クエリとキーによるプロダクトで他のタイプの類似性尺度またはカーネルを暗黙的に定義することによって、逆に推論することもできるということを意味します。カーネル法の研究に基づいて、これらをGeneralized Attentionとして組み立てます。(ほとんどのカーネルには閉じた形の式は存在しませんが、Generalized Attentionはそれらに依存しないため、このメカニズムを適用することができます。)
Performersはランダム特徴を使用して、ダウンストリームのTransformerアプリケーションでAttentionマトリックスを効果的に近似できることを最初に示した例です。正のランダム特徴、つまり元のクエリとキーの正の値の非線形関数の使用という新しいメカニズムがこのことを可能にしています。これらは、学習中の不安定性を回避するために重要であり、ソフトマックスAttentionメカニズムのより正確な近似を提供することが証明されています。
Towards FAVOR+: Fast Attention via Matrix Associativity
上記で示した分解により、Attentionマトリックスを二次的ではなく線形のメモリ複雑度で格納できます。この分解を使用して、a linear time attentionメカニズムを取得することもできます。
具体的には、Attentionメカニズムは、保存されたAttentionマトリックスに入力された値を乗算して最終結果を取得していましたが、Attentionマトリックスを分解した後、二次サイズのAttention行列を明示的に作成しなくても、行列の乗算を再配置して、通常のAttentionメカニズムの結果を近似することができます。こうして生み出されたものが、最終的にFAVOR +につながります。これらはいわゆる双方向性Attentionと呼ばれる過去と未来の概念がない非因果的Attentionに関連しています。トークンが入力シーケンスの後半に表示される他のトークンに対応しない単方向(因果的)Attentionのにするために、事前合計値を使用するようにアプローチをわずかに変更します。
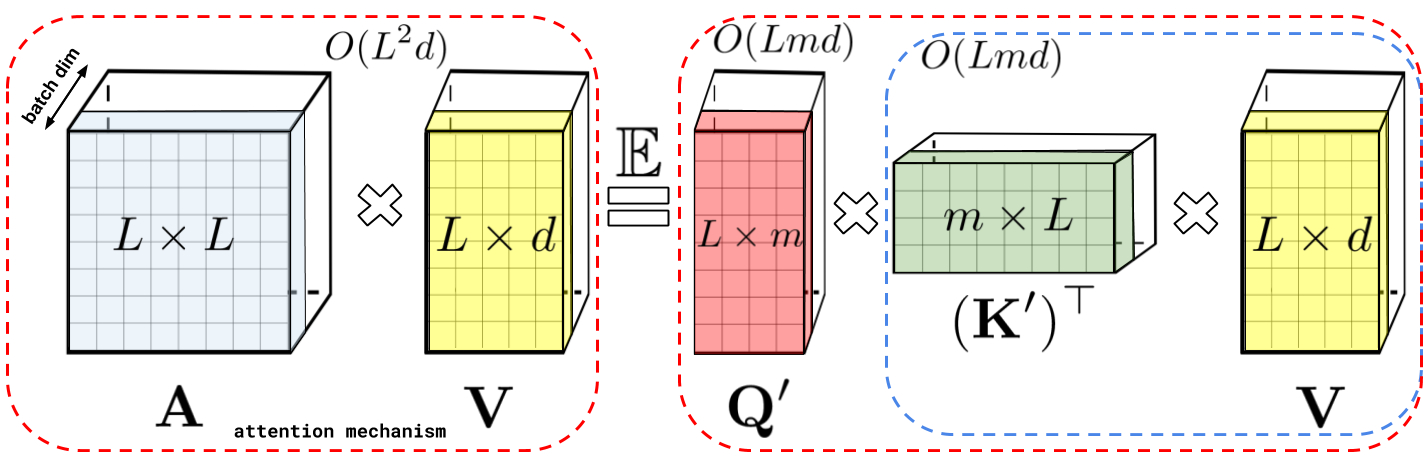
上図左部は標準的なAttentionモジュールの計算を示しています。ここでは、Attention行列 A とValueテンソル V で行列の乗算を実行することで、最終的な目的の結果が計算されています。それに対して、上図右部はAのもとである行列Q′とK′を分解し、破線枠で示された順序で行列の乗算を行うことで、線形のAttentionメカニズムを得ます。ただし、決して明示的にAやその近似を構築することはありません。
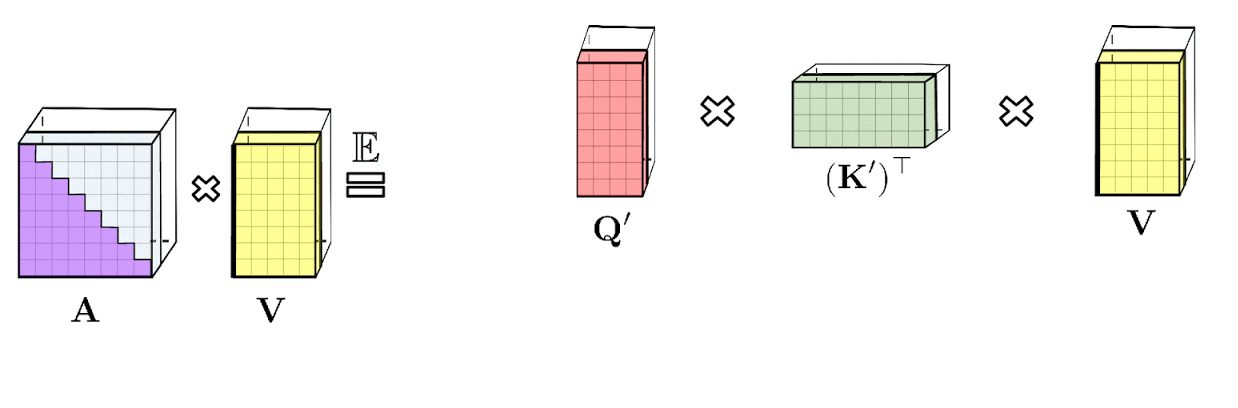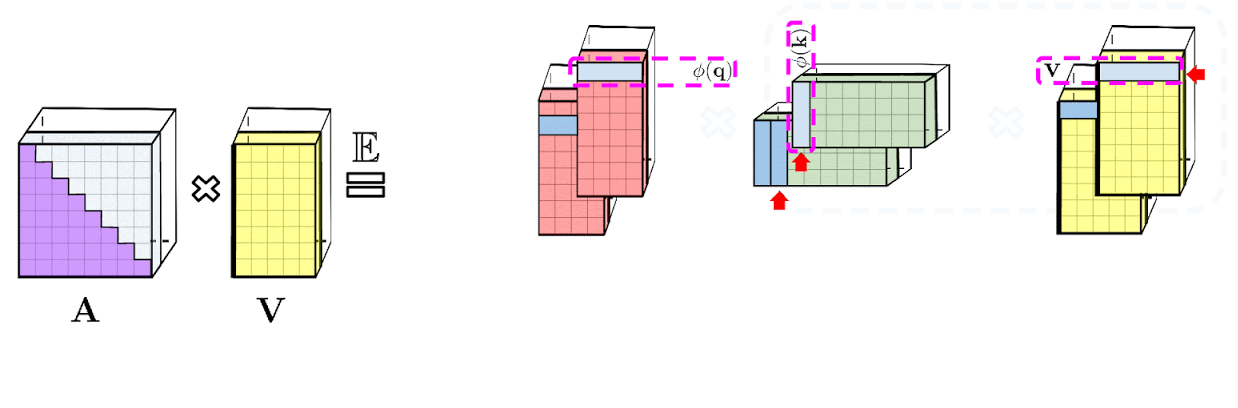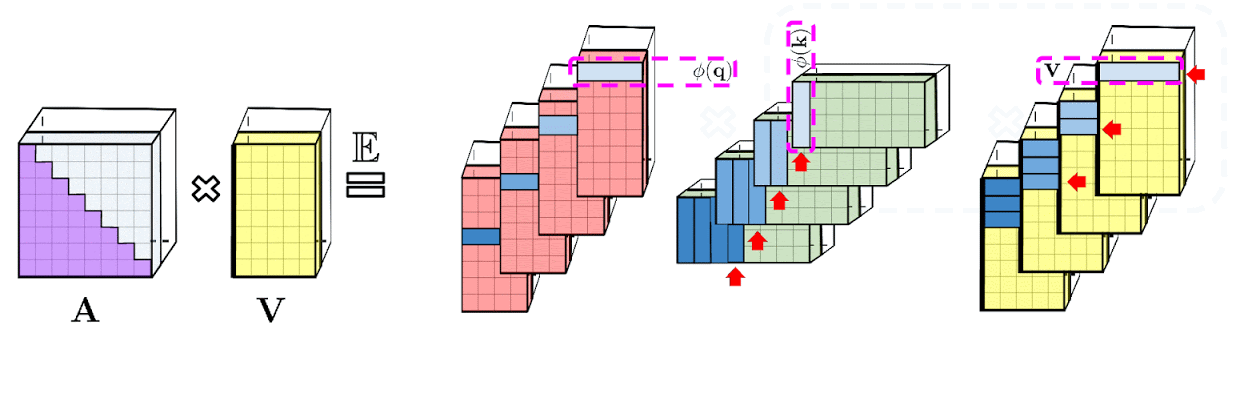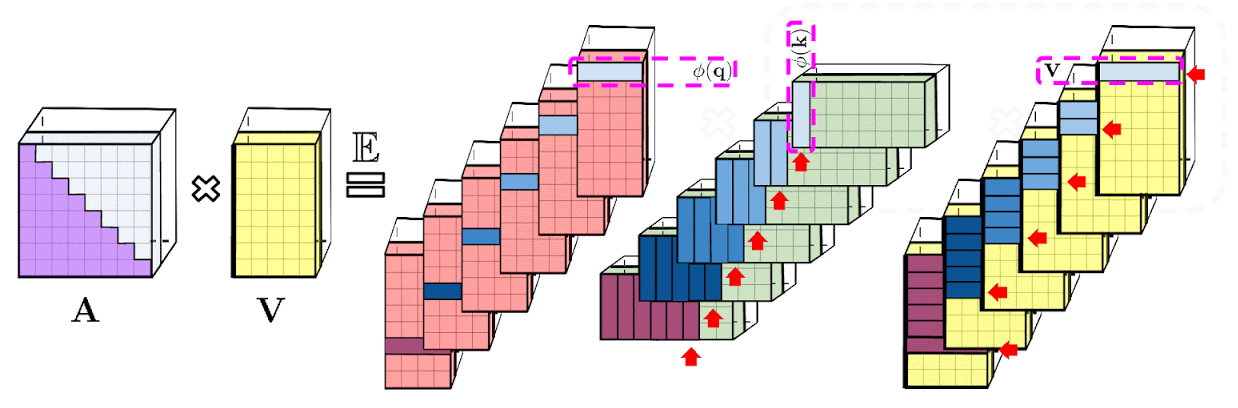
実験結果
最初に、Performerの空間と時間の複雑さをベンチマークし、Attentionのスピードアップとメモリの削減が経験的にほぼ最適であること、つまり、モデルでAttentionメカニズムをまったく使用しないことに非常に近いことが示されました。
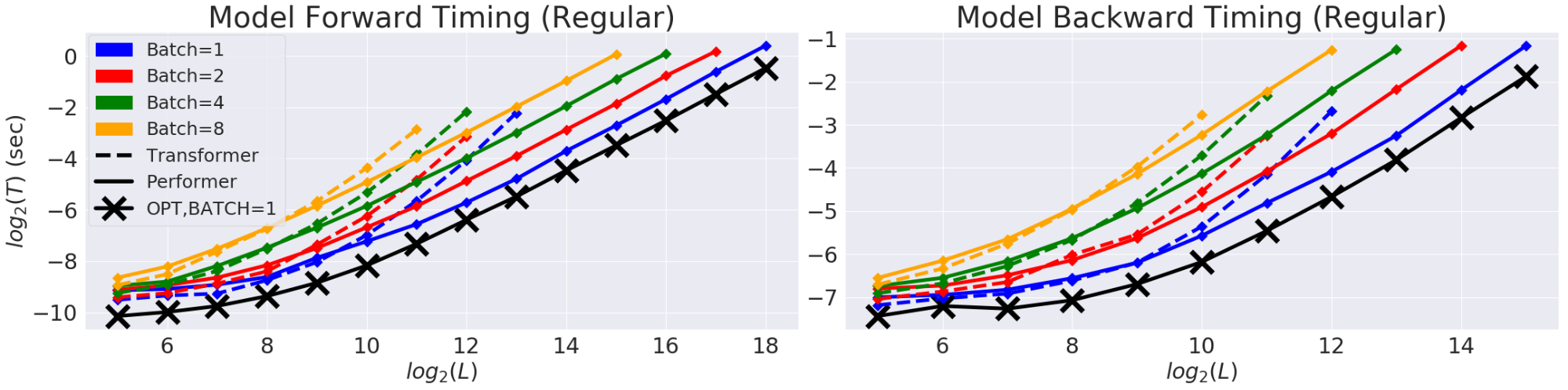
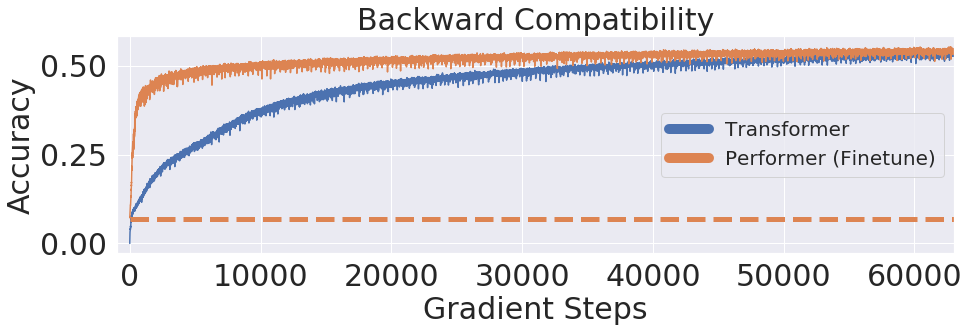
さらに、バイアスのないソフトマックス近似を使用して、少しのfine-tuningが、事前学習されたTransformerモデルと下位互換性があることを示しています。これにより、既存のモデルを完全に再トレーニングすることなく、推論速度を向上させることでエネルギーコストを削減できる可能性があることを意味しています。
実用例
タンパク質モデリングアプリケーションでの実用例が紹介されています。
タンパク質は、生命に不可欠な複雑な3D構造と特定の機能を備えた大きな分子です。タンパク質は線形シーケンスデータとすることができ、各文字は20個のアミノ酸ビルディングブロックの1つと考えることができます。そのため、タンパク質配列の大きな非標識コーパス(UniRefなど)を入力データとすると、折りたたまれた機能性高分子について正確な予測を行うことができるTransformerモデルをつくることができます。
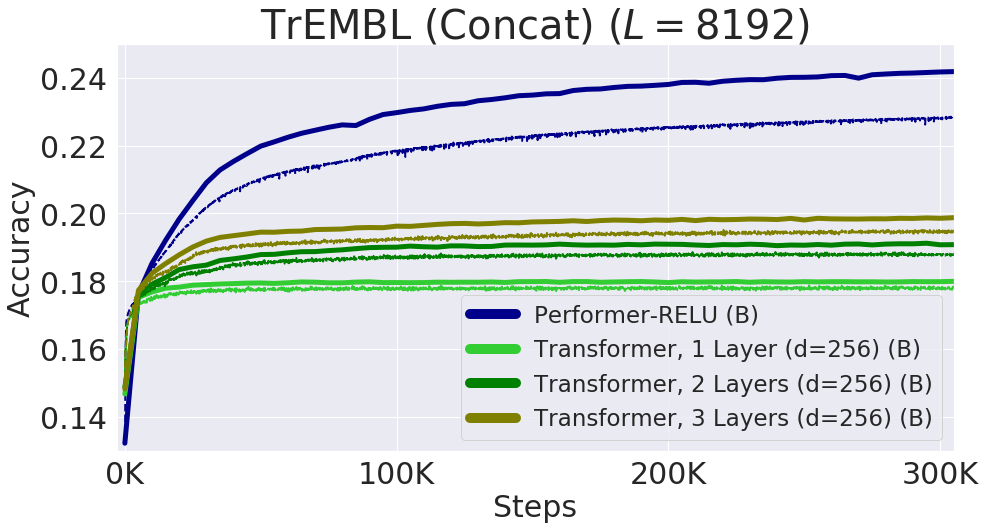
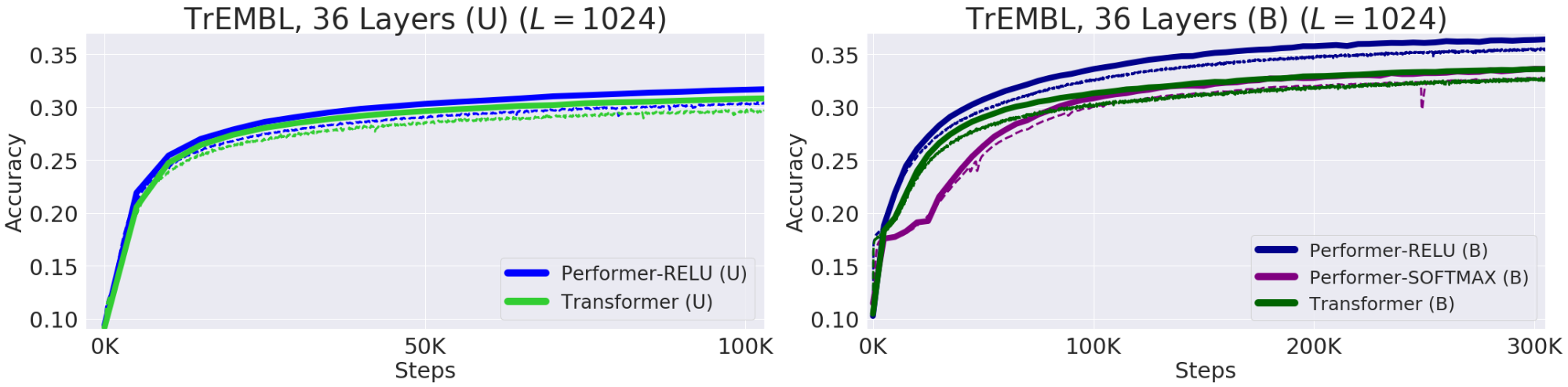
Performer-ReLU(ReLUベースのアテンション、softmaxとは異なるGeneralized Attentionのインスタンスを使用)は、タンパク質配列データのモデリングで強力に機能することがわかりました。一方、Performer-Softmaxは、理論的な結果から予測されるように、Transformerのパフォーマンスと一致していることがわかります。
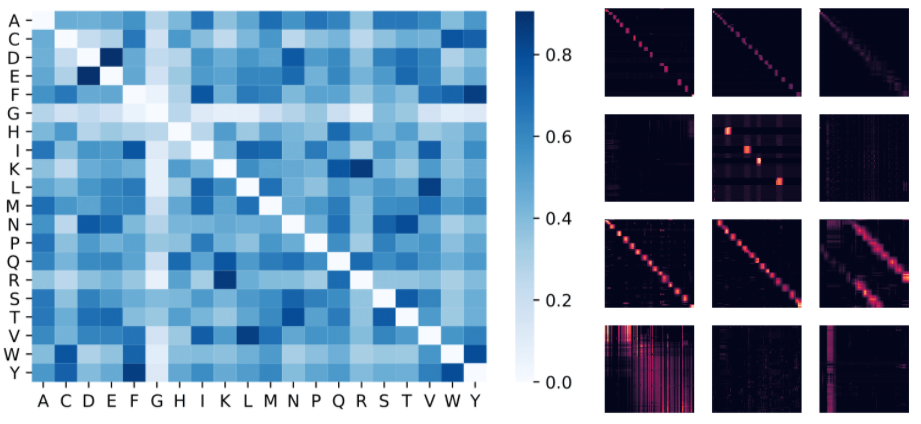
以下では、ReLUベースの近似Attentionメカニズムを使用して学習されたタンパク質のPerformerモデルを視覚化します。Performerを使用してアミノ酸間の類似性を推定すると、慎重にキュレーションされた配列アラインメント全体の進化的置換パターンを分析することによって得られた、よく知られた置換マトリックスと同様の構造が再現されます。
より一般的には、タンパク質データで学習されたTransformerモデルと一致するローカルおよびグローバルなAttentionパターンが見つかります。Performerの密なAttentionの近似は、複数のタンパク質配列にわたるグローバルな相互作用を捉える可能性があります。概念実証として、長い連結タンパク質配列でモデルを学習させました。通常のTransformerモデルのメモリが過負荷になる一方で、スペース効率のためにPerformerは過負荷にならないことが示されています。
下図左部は、Attentionの重みから推定されたアミノ酸類似度マトリックスです。このモデルは、生化学に関する事前情報がなく、またタンパク質配列にしかアクセスできないにもかかわらず、(D、E)や(F、Y)などの非常に類似したアミノ酸ペアを認識していることがわかります。下図右部は、BPT1_BOVINタンパク質の4つのレイヤー(行)と3つの選択されたヘッド(列)からのAttentionマトリックスです。ローカルおよびグローバルなAttentionパターンが示されています。
下図は個々のタンパク質配列を連結することによって得られる長さ8192までの配列でのパフォーマンスを示したものです。 TPUメモリに収まるように、Transformerのサイズ(レイヤー数と埋め込み寸法)が縮小されています。Performer-ReLUが最もよい性能をだしていることがわかります。