はじめに
OpenAIが新たに画像処理モデルとしてCLIP(Contrastive Language–Image Pre-training)を発表しました。従来よりも汎用性能が高いことが特徴で、今後画像処理の世界を大きく変える可能性があります。今回は、簡単に概要だけご紹介します。(今後、論文の詳細記事を掲載する予定です。)
現状の問題点
OpenAIの研究チームは、画像処理分野における問題点を以下のように指摘しています。
⑴典型的な画像データセットは、視覚的概念の狭い集合しか扱えていないのに、作成に人手が必要で費用がかかる
⑵基本的なモデルは一つのタスクに最適化されており、別のタスクに応用が効かない
⑶ベンチマークテストではよい結果を出しても、実用の場でよい結果を出すことが少ない
CLIPはこれらの問題点に対して、インターネット上から豊富な画像とラベリングを利用することで、多様な表現とノイズをうまく取り込み、様々なタスクにロバストな作りにすることに成功しました。特定のベンチマークテストに対応させていないのにもかかわらず、優れた結果を残すことで高い汎用性を示しています。
●コストのかかるデータセット
一般にデータセットの構築は大変コストのかかる作業として知られています。特に画像処理分野では、人手によってラベルづけされたデータセットを利用するのが一般的なため、その問題は顕著でした。(例えば、画像処理分野でデータセットに関して最大の取り組みの1つであるImageNetデータセットでは、22,000のオブジェクトカテゴリに対して1,400万の画像に注釈を付けるために25,000人を超える作業者が必要でした。)
→今回はインターネット上の画像データとテキストを利用したため、こうしたコストを減らすことができています。
●狭い概念
ImageNetは1000カテゴリーを予測する分には問題なく機能しますが、それ以上の広いカテゴリーを予測することができないという問題があります。
→CLIPではインターネット上で集めた豊富な概念を利用して学習するため、未知の概念であっても柔軟に対応できるようになりました。
●実用性の低さ
ベンチマークテストでは非常によい精度(時には人間を超えるような精度)を出しながら、実用には耐えられないということが幾度もありました。これは「ベンチマーク性能」と「実用性能」の間に差があることを意味します。これはベンチマークテスト用の教師データで学習することで、ベンチマーク特有の表現を学習(ある意味でカンニング)している状況にあったことに起因しています。
→CLIPではベンチマークテスト用の教師データで学習することなく、ベンチマークテストに挑むということをしています。
アプローチ
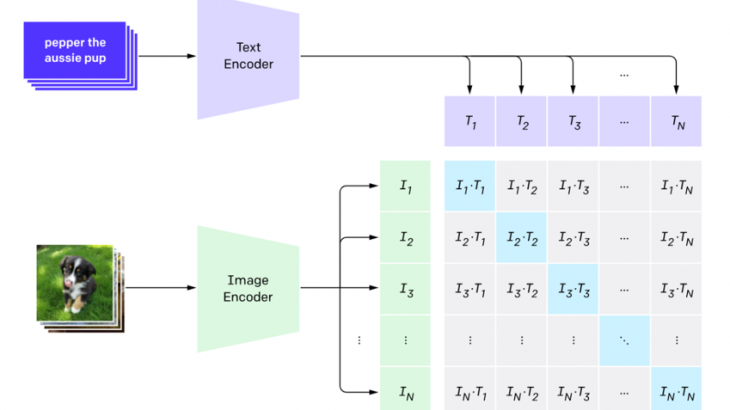
さまざまな画像分類データセットで、ゼロショットパフォーマンス(未知のデータを識別する性能)を高めるには、単純に事前トレーニングタスクをスケーリングするだけで十分である、という仮説に基づいて、モデルが作成されています。CLIPでは、インターネット上で見つかった画像とテキストのペアという、多様で豊富に利用可能な教師データを使用します。
モデルは与えた画像に対して、ランダムにサンプリングされた32,768個のテキストスニペットのセットのうち、データセットで実際にペアになっているものを予測します。この学習を通して、モデルは多様な画像概念とそれに関係する名称を覚えます。
結果として、拡張性が高い柔軟な画像分類ができるようになりました。また汎用的な性能を示したため、ある程度、ゼロショットパフォーマンスを高めるためには、単純に事前トレーニングタスクをスケーリングするだけで十分である、仮説が正しいことも示されました。
モデルの特徴
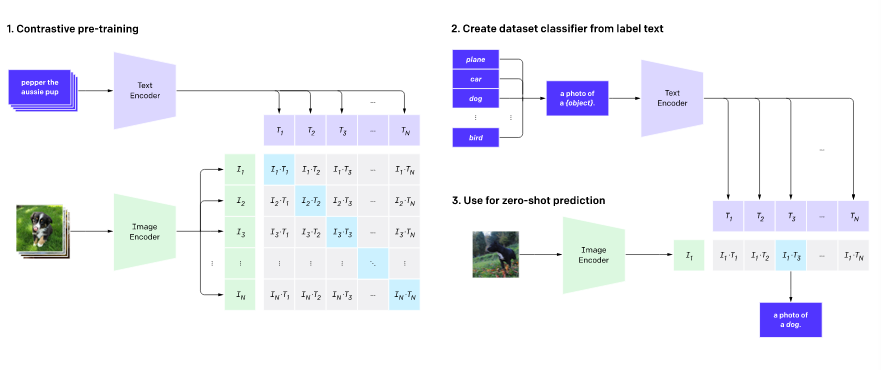
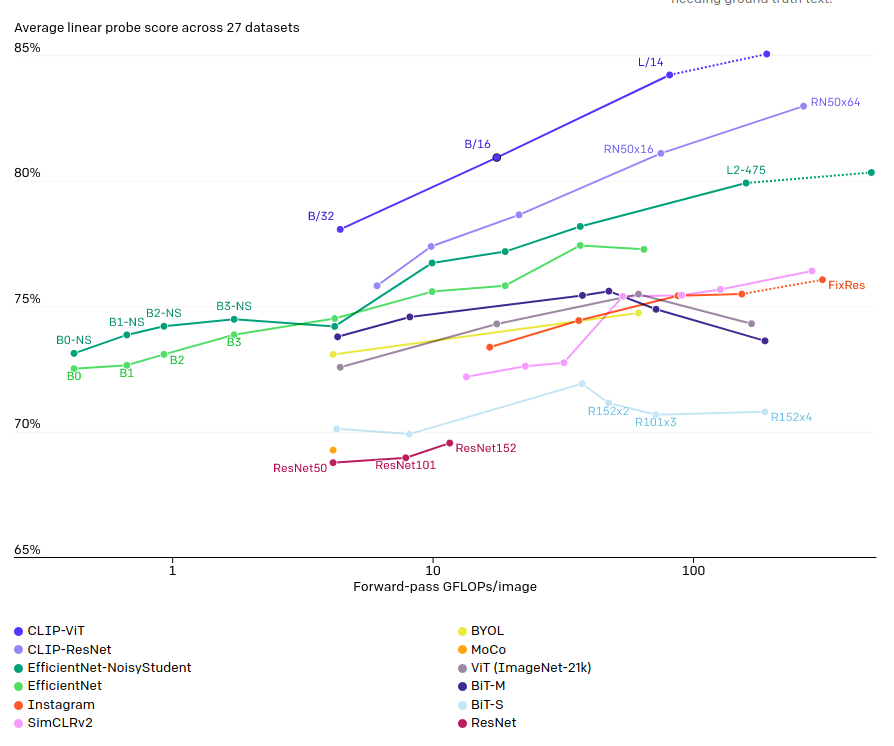
CLIPは前述の通り、汎用性が高く効率のよい学習モデルであることが売りです。CLIPは特に優れた精度を出すタスクがあるというよりも、多くのタスクで高い精度を、しかもタスク固有のデータセットで学習することなく出すことができるということが特徴です。
●効率的な学習モデル
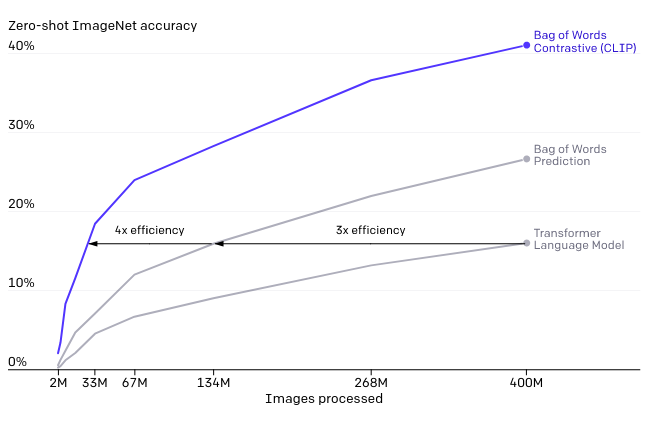
VirTexの対照学習とVisionTransformerの導入によって、従来のモデルから7倍も効率的になりました。(なお、基本的なアーキテクチャに関しては、独自に開発してはいるものの参考にした論文から大きく変えていないそうです。)
●柔軟で汎用的なモデル
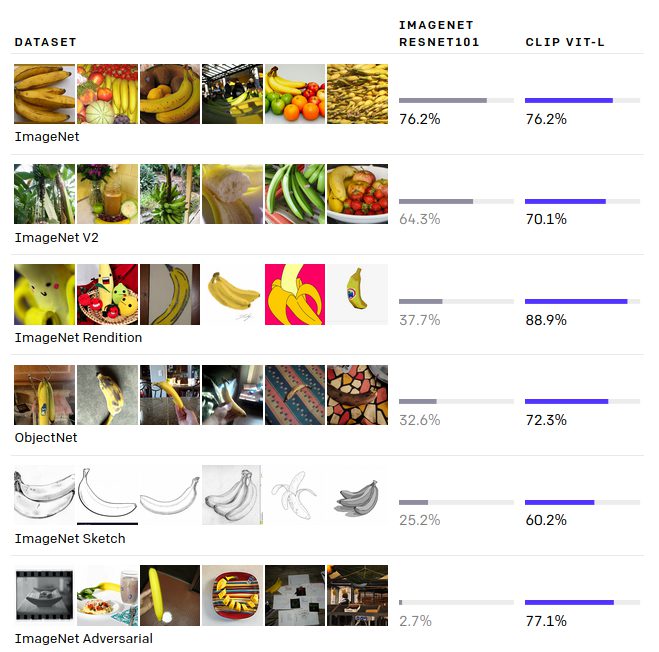
異なるタスクに応用することができます。より細かいオブジェクト分類、地理的位置特定、ビデオでの行動認識、OCRなどのタスクを含む30の異なるデータセットでよい精度を出すことができました。
モデルの限界
より抽象的、もしくはシステマティックなタスク(画像内の物体の数を数えるタスクや、画像内で一番近い車がどれくらい近いかが計測するタスク)では限界が見られました。これらのタスクではランダムに推定するよりは多少上回る程度の精度しか得られませんでした。また、より細かい分類(車のモデル分類や花の種別分類など)にも対応することができませんでした。
またCLIPのゼロショット分類器は、言葉遣いや言い回しが変化すると対応できないことがわかりました。うまく機能するために試行錯誤の「プロンプトエンジニアリング」が必要になる場合があることが確認されました。
まとめ
論文からはCLIPの開発チームの目線はもはや固有のタスクの精度を追って他のSOATモデルと争うものではなく、人間の汎用的な力にどのように近づくのかに移行しているような感覚を受けました。
今後、どれだけ同じモデルが色々なタスクでよい精度を出せるのか、ということに注目が集まる気がします。汎用型AIへの足がかりになるのでしょうか。