はじめに
FacebookのAIリサーチチームから、画像処理にTransformerを利用して効率化を目指した新たなモデル「Data-efficient image Transformers (DeiT)」が発表されたので、簡単にご紹介します。
Training data-efficient image transformers & distillation through attention
https://arxiv.org/abs/2012.12877
●Facebook AI Blog
Data-efficient image Transformers: A promising new technique for image classification
https://ai.facebook.com/blog/data-efficient-image-transformers-a-promising-new-technique-for-image-classification
●GitHub
https://github.com/facebookresearch/deit
概要
TransformerアーキテクチャがNLP(自然言語処理)分野で著しい成果を出していることで、近年、画像処理の分野でもTransformerを取り入れたモデルの開発が進められています。(Facebookでも昨年物体検出にTransformerを組み合わせたDETRを発表し、直近では完全にTransformerのみ(CNNを使わない)で構成されたViTがGoogleから発表され、両者ともに話題を呼びました。)※「Transformer」「DETR」「ViT」について詳しく知りたい方は、解説記事をご参照ください。
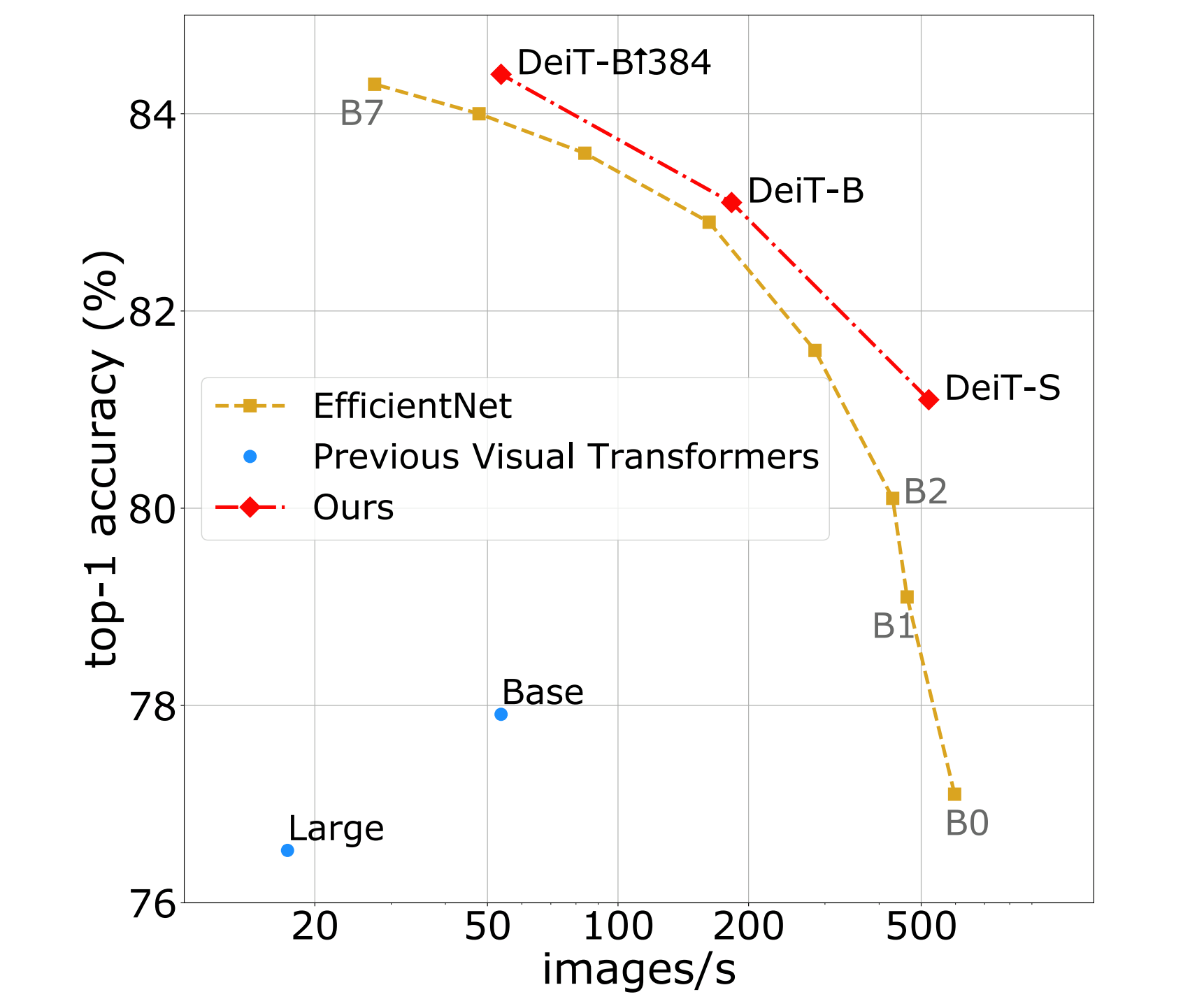
今回、Facebookが提案しているDeiT(Data-efficient image Transformers )は、精度を維持しながら学習に必要なデータやパラメータを減らしたモデルです。開発の背景には、モデルの大規模化が進み、最新モデルにアクセスできるのが大企業に所属している人間のみになっていることへの危惧があります。多くの人が自分のパソコンで処理できるモデルを提供することが目指されました。
DeiTをシングル8-GPUサーバーで三日間トレーニングした結果、ImageNetベーンマークで84.2%の精度を達成しました。なお、この精度はCNNの最先端モデルに匹敵します。
●Transformerについての解説記事
自然言語処理の必須知識 Transformer を徹底解説!
●DETRについての解説記事
Transformer を物体検出に採用!話題のDETRを詳細解説!
●Vision Transformerについての解説記事
画像認識の革新モデル!脱CNNを果たしたVision Transformerを徹底解説!
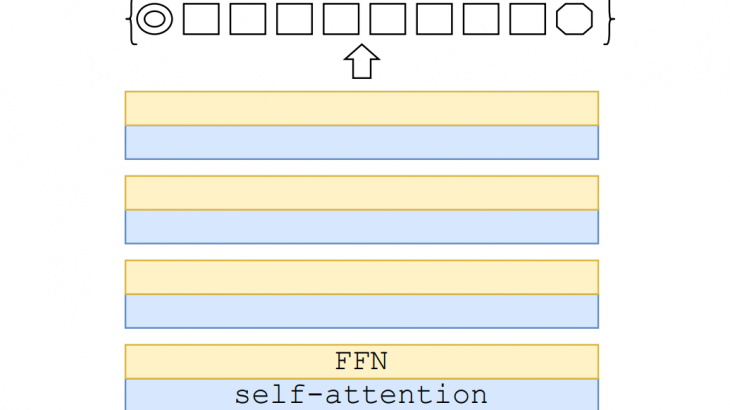
現状・課題
画像分類は人間には比較的容易でも、機械にとっては難しいものとされてきました。特に最近発表されたViTなどの(CNNを利用せず)Transformerのみで構築されたモデルには、統計的事前確率を利用できないため大変困難なものとされていました。そのためViTなどのモデルは、シンプルに画像例から異なる物体を分類することを学習していきます。このことで、大量の画像例が必要となります。
DeiTは効率的に学習できるように改良され、それまで数億の画像が必要だった学習を、120万枚で十分にすることに成功しました。
論文の提案
DeiTでは、学習戦略の変更が行われています。これは、これまでの戦略(データ拡張、最適化、正則化など)がCNNモデルのため(特に大規模データセットを利用したCNNモモデルのため)に開発されたためです。
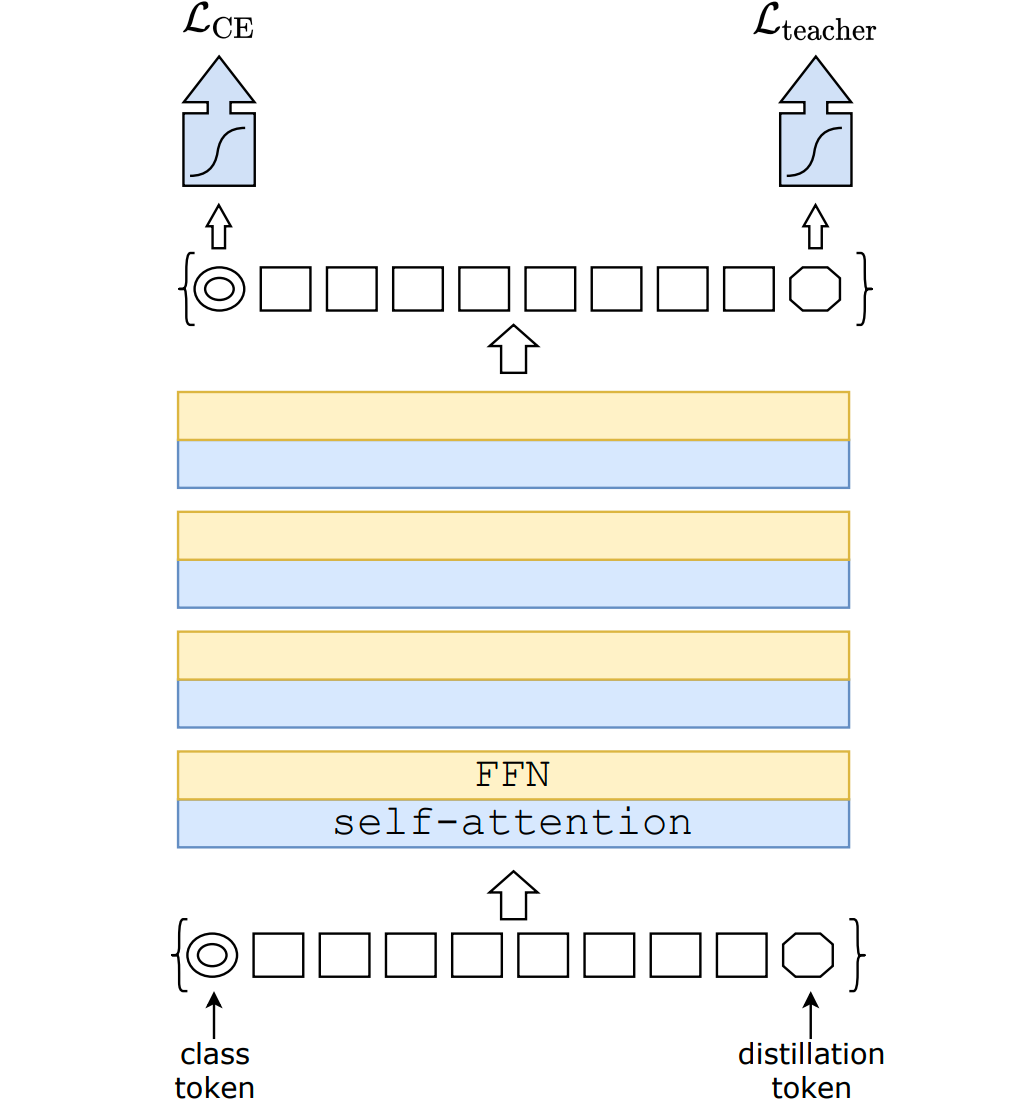
次に、「蒸留」が行えるようにTransformerアーキテクチャを修正しています。「蒸留」とは、べつのネットワーク(教師ネットワーク)の出力から、本体となるネットワーク(生徒ネットワーク)が学習できるようにすることです。このとき、DeiTでは教師ネットワークにCNNモデルを利用します。これはCNNモデルはTransformerとは異なり多くの事前確率を取得することができることを利用したものです。このことで、画像の枚数を減らすことができます。
生徒ネットワークは、蒸留によりラベルデータセット(影響は強い)と教師ネットワークから学習するため、分岐する可能性がある二つの異なる物体を追うことになります。この追及自体はネットワークの負荷になるため、この負荷を軽減するためにDeiTでは蒸留用のトークン(変換された画像データに沿う形でネットワーク内で学習されるベクトル)が導入されています。この蒸留用のトークンは、アテンションレイヤーを通して、分類トークンと画像構成トークンと相互作用するように教師モデルから学習されていきます。この蒸留の工夫によって、画像分類がより効率的に行えるようになります。
まとめ
DeiTは、今後画像処理の分野でも普及していくと考えられるTransformerを利用するうえで重要な一歩となる可能性があります。開発研究の蓄積があるCNNを利用したモデルと同等の成果をすでに上げていることは、今後Transformerが画像処理の分野でも主流になることを予感させます。