はじめに
Googleからオープンドメインな自然言語処理用の構造化されたデータセットToTToが発表されましたので、ご紹介します。
GoogleAIblog
ToTTo: A Controlled Table-to-Text Generation Dataset
https://ai.googleblog.com/2021/01/totto-controlled-table-to-text.html
論文
ToTTo: A Controlled Table-To-Text Generation Dataset
https://arxiv.org/abs/2004.14373
背景
自然言語処理分野は高度に発達したものの、依然として幻覚 hallucination(理解できるがソースに忠実ではないテキストのこと)を生成する可能性は高く、高精度を必要とする多くのアプリケーションでこれらのシステムを使用することは難しい現状があります。
既存のシステムでも文章が構造化されている場合、比較的タスク難易度が楽になります。ただし、既存の大規模な構造化データセットはノイズが多いことが多く(つまり、参照文を表形式のデータから完全に推測できないため)、モデル開発における幻覚の測定には信頼性がありません。
そのため、新たに構造化データセットToTTo(“A Controlled Table-To-Text Generation Dataset”)を開発しました。ToTToはモデリング研究や、モデルの改善をより適切に検出できる評価指標の開発に役立つデータセットであることが示されています。
ToTTo
ToTToはオープンドメインなテーブル型のテキスト生成データセットです。学習用に121,000例、検証用およびテスト用にそれぞれ7,500例が用意されています。アノテーションの精度が高く維持されており、そのためこのデータセットは、高精度のテキスト生成の研究のための挑戦的なベンチマークとして適しています。
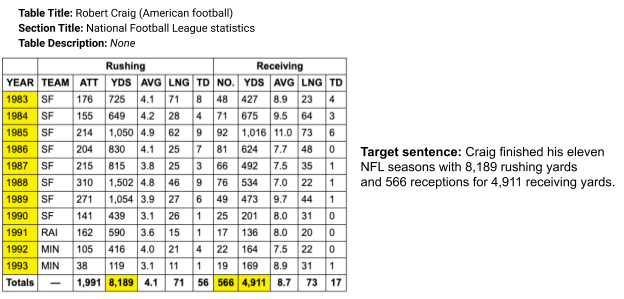
アノテーションプロセス
表形式のデータから自然でありながらクリーンなターゲット文を取得するためのアノテーションプロセスを設計することは、重要な課題です。これまでの自動的なWikibioなどではノイズが大量に混入してしまいますが、一方でゼロからアノテータに指示を出して設計するとノイズは消えますが、多様性が失われてしまうという問題があります。
そのため、ToTToではWikipediaを改定する際に利用されるアノテーション戦略を利用しています。このことで、形式がクリーンでありながら、自然であり、かつ多様な言語特性を内包することができます。まずWikipediaから情報を収集することから始めます。ここで、特定のテーブルは、ページテキストとテーブルの間の単語の重複や表形式のデータを参照するハイパーリンクなど、ヒューリスティックに従ってサポートページコンテキストから収集された要約文とペアになっています。この要約文には、表でサポートされていない情報が含まれている場合があり、文自体ではなく、表でのみ検出された先行詞を含む代名詞が含まれている場合があります。次に、アノテーターは、センテンスをサポートするテーブル内のセルを強調表示し、テーブルでサポートされていないセンテンス内のフレーズを削除します。また、文を非コンテキスト化して、スタンドアロン(たとえば、正しい代名詞の解決)と、必要に応じて正しい文法を使用します。
データセット内の分析
ToTToには44のカテゴリーが含まれていますが、そのうち約56.4%がスポーツと国に関する内容になっています。
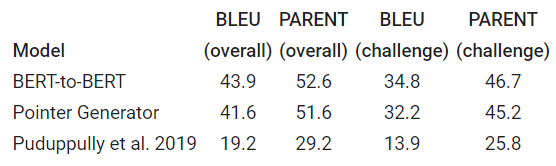
実験
ToTToを用いて学習されたモデルをBLEUとPARNETのふたつの指標で評価しています。
また、人力で専門家との精度を比較したところ、20%とほど悪いことがわかりました。

ほかにも、情報量が大きく削減されてしまう、間違いがあるなどの問題があることも明らかにされました。
