はじめに
Googleが昨年12月にリリースしたGoogleフォトの新機能である写真への没入感を高めるシネマティックフォトに使われているAI技術について説明します。
『The Technology Behind Cinematic Photos』
https://ai.googleblog.com/2021/02/the-technology-behind-cinematic-photos.html

概要
GoogleがGoogleフォトにシネマティックフォトと呼ばれる機能を新たにリリースしました。シネマティックフォトは、写真を撮った瞬間に感じた没入感を取り戻すことを目的としたもので、2D写真をより没入感を感じられる3Dアニメーションにします。今回、この機能を導入するために画像の3D表現を推測することでカメラの動きと視差をシュミレートしています。Googleでは通常、複数視点から行われる深度推定をCNNを利用することで単一視点から撮られた写真でも高性能で予測することに成功し、より正確なシュミレートを可能にしました。

シネマティックフォト
深度推定
写真の3D構造に関する情報を取得するために基本的には深度マップが必要となります。深度マップは通常、カメラ間の距離がわかっているさまざまな視点で複数の写真を同時に撮影することで取得されます。最近のスマートフォンなどにはデュアルカメラや、デュアルピクセルセンサーなどが搭載されているものもあり、そこから深度マップを取得することができる場合もありますが、1つの視点からのみ撮影された画像に関しては基本的に深度マップを取得することができません。
そこで、研究チームはCNNを利用して、単一視点のRGB画像から深度マップを予測するモデルを構築しました。モデルは、オブジェクトの相対サイズ、線形遠近法、商店のボケなどの情報を利用して深度を推定します。
深度推定データセット
現在、単一視点からの深度推定をするためのデータセットは、ロボットや自動運転などで利用されるものであり、ふつうの写真(人、ペットなどがメイン)のものを中心とするものが少ないという問題がありました。Googleでは、その問題点を解決するために正解深度を測定した独自のデータセットを構築しました。複数のデータセットを混合することで、モデルの汎化能力の向上が期待されます。
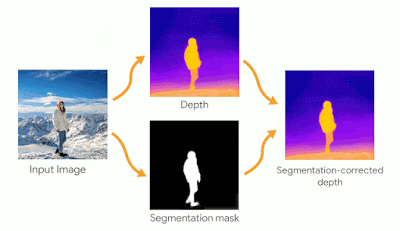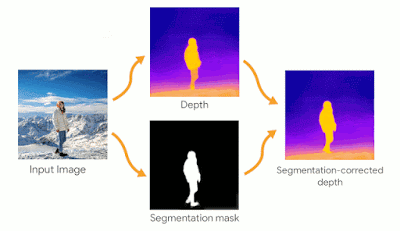
人物の深度マップ精度
シネマティックフォトは、特に人物周辺の深度マップの精度に対して敏感になるように構築されています。人物の周辺にずれが生じると不快な印象を与える可能性があるためです。セグメンテーションタスクを組み合わせて、人物の姿を予測したものと組み合わせることで、より正確な深度マップを構築します。
3Dシーンの自由度
3Dシーンでカメラをアニメーション化する場合、多くの自由度があります。没入感を高めることが目的のため、プロのビデオカメラリグを参考に、被写体を中心に回転に最適なピボットポイントを特定します。
3Dシーンを再構成するために、RGB画像を深度マップに押し出してメッシュを作成します。このとき、メッシュ内の隣接するポイントの深度に大きな違いが生じる可能性があります。この深度の違いは、仮想カメラを回転させるほど、物体が引き延ばされるようにみえるため、違和感を生み出してしまいます。引き延ばしを最小限にしながら、視差を導入する軌道を見つけることが求められます。

引き延ばしを最小にする損失関数
引き延ばしが少なくなる軌跡を見つけるように損失関数を定義します。この損失関数は単純に引き延ばされたピクセル数の総数を数えるのではなく、連続して引き延ばされているピクセルの数を数えることで、より違和感を減らすことができます。

人間のポーズネットワークからのパッド入りセグメンテーションマスクを利用して、画像を頭、体、背景の3つの異なる領域に分割します。損失関数は、正規化された損失の加重和として最終損失を計算する前に、各領域内で正規化されます。領域に重みを付けると、最適化プロセスにバイアスが異なり、画像の被写体に近いアーティファクトではなく、背景領域のアーティファクトを優先する軌跡が選択されます。
カメラの軌道の最適化中の目標は、目立つアーティファクトの量が最も少ないカメラのパスを選択することです。これらのプレビュー画像では、出力のアーティファクトは赤で表示され、緑と青のオーバーレイはさまざまな身体領域を視覚化します。
シーンのフレーミング
一般に、再投影された3Dシーンは、縦向きの長方形にうまく収まらないため、入力画像の重要な部分を保持したまま、正しいアスペクト比で出力をフレーミングする必要があります。そのため、画像全体のピクセルごとの顕著性を予測するディープニューラルネットワークを使用します。仮想カメラを3Dでフレーミングする場合、モデルは、レンダリングされたメッシュがすべての出力ビデオフレームを完全に占めるようにしながら、できるだけ多くの顕著な領域を識別してキャプチャします。これには、モデルがカメラの視野を縮小する必要がある場合があります。

まとめ
シネマティックフォトは、写真への没入感を高めるための機能であり直接的に収益につながりにくいものですが、将来的なユーザーの満足度を考えて導入したと考えられます。画像認識技術を組み合わせることで、今回のシネマティックフォトは可能になっており、基礎技術と組み合わせる能力の高さが改めて示されています。