
はじめに
MITからより効率的にAttention機構が利用できる自然言語モデル及びハードウェアを発表しました。
A language learning system that pays attention — more efficiently than ever before
https://news.mit.edu/2021/language-learning-efficiency-0210
論文
SpAtten: Efficient Sparse Attention Architecture with Cascade Token and Head Pruning
https://arxiv.org/pdf/2012.09852.pdf
概要
近年、自然言語処理の分野ではAttention機構の有用性が確認され、利用が増えています。Attention機構は、単語同士の結びつきに対して異なる重みづけをするものです。単語の重要性やほかの単語との関連性がわかることで、自然言語処理のタスクの多くが精度よくこなせるようになりました。
しかし、Attention機構は精度のために、速度と計算能力を犠牲にします。汎用的なプロセッサでは低速で動作してしまうため、今回MITの研究チームが、Attentionメカニズムに特化した「SpAtten」とよばれるソフトフェアとハードウェアを組み合わせたシステムを設計しました。効率性が向上し、エネルギー効率も向上したことで、今後Attentionが個人用デバイスなどでも利用できることが期待されています。
課題
Attention機構がもつ課題のひとつは、大きなメモリを必要とするということです。そのために、強力なコンピュータが必要となります。また、CPUやGPUなどの汎用プロセッサだと、Attentionメカニズムの複雑なデータ移動と演算のシーケンスに問題が発生します。
SpAtten
SpAttenは、人間の脳が言語を処理する方法からアイディアをもらっています。人間が文章の意味をはやく理解できるのは、文章のキーワードに焦点をあてることができるためです。SpAttenも同様に、より効率的にキーワードに注目できるようにしました。ソフトウェアとハードウェアの両方が改良されました。
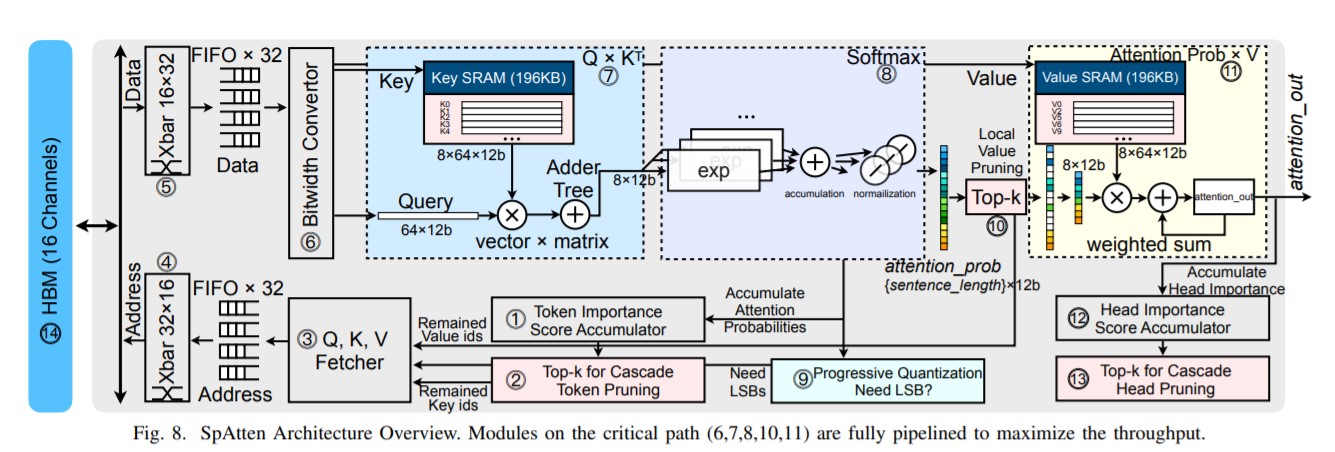
ソフトウェア
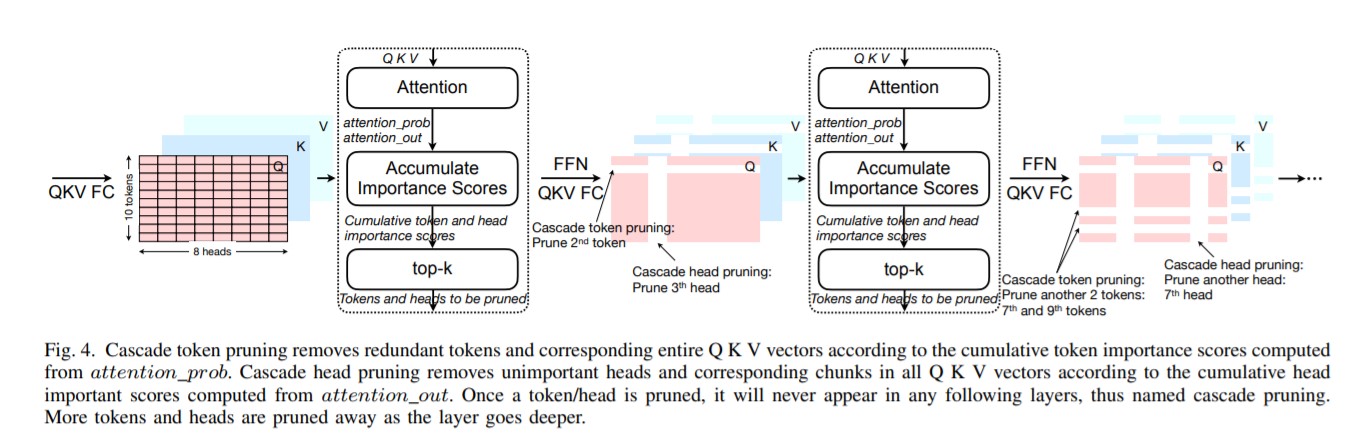
SpAttenによる「カスケードプルーニング」(計算から不要なデータを排除すること)の実装が、改良のひとつです。重要性の低いトークンを削除することで、必要な計算とデータ移動の負荷を減らします。
もうひとつは、Attentionメカニズムがもつマルチヘッド部分でも、重要性が低いものを削除するという工夫です。このことで、根本的な計算量を削減します。
さらに、メモリの使用を削減するために「プログレッシブ量子化」とよばれる手法も開発しています。この方法によって、より小さなビット幅のチャンクでデータを使用し、メモリから可能な限り少ないデータをフェッチすることができるようになります。単純な文には小さいビット幅に対応する精度の低いデータが使用され、複雑な文には高い精度のデータが利用されます。

ハードウェア
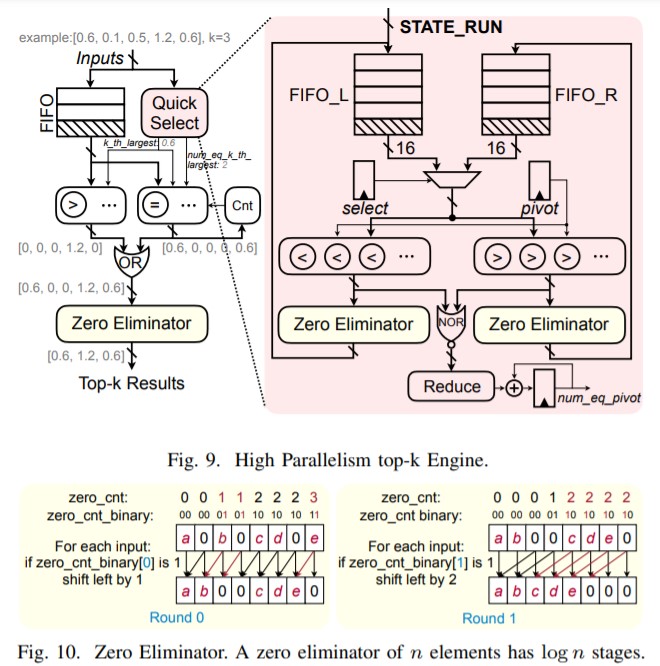
高速な「並列処理」が可能になるアーキテクチャの設計を採用しています。この設計により、小数のコンピュータークロックサイクルでトークンとヘッドの重要性をランク付けすることができます。
実験
SpAttenはまだ物理チップとして製造されていませんが、シミュレーション上、次善のTITAN Xp GPUよりも100倍以上高速に動作しました。また、1000倍以上エネルギー効率がよいことも明らかになりました。ハードウェア対応トランスフォーマー(HAT)フレームワークを使用して、SpAtten専用のNLPモデルアーキテクチャを構築し、より一般的なモデルの約2倍のスピードアップを達成しました。
まとめ
Attentionを利用したTransformerがいま、自然言語処理だけでなく画像処理、生成モデルなどでも応用されています。今回の研究はより巨大なモデルをつくることを可能にするものであり、Transformerは理論上、モデル容量を大きくすることで精度の向上が見込めるため、より精度が向上したモデルの誕生が予感されます。