はじめに
香港大学やNvidia社らの研究チームよりセマンティックセグメンテーションタスク向けのモデルSegFormerが発表されました(2021年5月31日公開)。よりシンプルで効率的なモデルをTransformerアーキテクチャとMLPアーキテクチャを組み合わせることで実現しています。
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
https://arxiv.org/abs/2105.15203
概要
セマンティックセグメンテーションタスク向けに新たにSegFormerが発表されました。
SegFormerの特徴
・階層構造のTransformerエンコーダで構成されている。
階層構造をとることで、ポジショナルエンコーディングを利用する必要がなくなりました。なお、ポジショナルエンコーディングは学習時と異なる解像度の画像を受け取った時、精度を低下させる要因となります。
・新たに複層のMLPデコーダを追加した。
異なる層の情報を統合するMLPデコーダを追加することで、ローカルアテンションとグローバルアテンションが非常に強力な表現として組み合わせることに成功しました。このことで従来の複雑なデコーダ構造を排除することができました。
・精度、効率性、ロバスト性が向上した。
現状のモデルよりも省パラメータながら、より良い精度をだすことに成功しました。また高いロバスト性も確認されました。
詳細
背景
セグメンテーションタスクは画像分類タスクから大きな影響を受けてきました。そのため、VGGなどのCNN型のモデルがベースモデルとして使われてきました。しかし、近年Transformerを画像分類に利用したVision Transformer(ViT)が発表されてから、セグメンテーションタスクでもViTをベースモデルとしたものが発表されてきました。そうしたなかで、ViTには以下のような限界が指摘されていました。
ViTの限界
・単一スケールの低解像度の特徴しか出力しない(複数スケールができない)
・おおきな画像に対して高い計算コストが必要となる
こうした問題点を解決するために、CNN型のベースモデルでもみられたように階層構造型のアーキテクチャがTransformer型のベースモデルでも作られるようになりました。代表的なものとしてPyramid Vision Transformer(PVT)があります。
Pyramid Vision Transformer(PVT)
・ViTをよりセマンティックセグメンテーション向けの「密な」予測のためにピラミッド構造に拡張したもの。
・ViTよりも精度がおおきく改善した。
PVTの成功を受け、多くの改良モデルがつくられました。ただし、それらはエンコーダ部分に改良が集中しており、デコーダ部分に改善の余地が特にあると研究チームは考えました。そこでSegFormerが開発されました。
SegFormer
SegFormerは一般的なセグメンテーションモデルにみられるように、エンコーダ—デコーダモデルです。
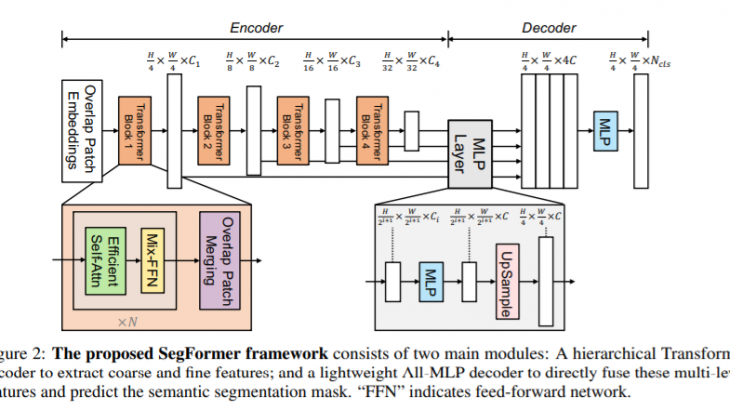
階層的Transformerエンコーダ:高解像度の特徴量と低解像度の特徴量を生成する
軽量MLPデコーダ:複数スケールの解像度を受け取り、最終的なセマンティックセグメンテーションマスクを生成する
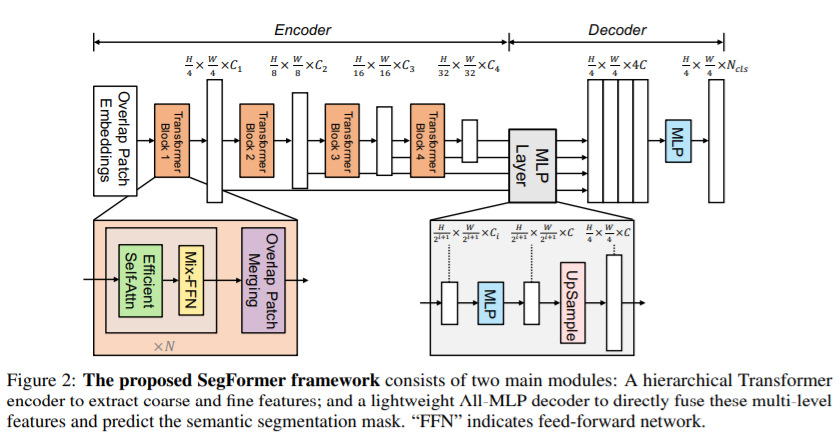
SegFormerの処理の流れ
SegFormerでは以下のような処理が行われます。
①H×W×3の画像を受けとる
②4×4のパッチサイズずつに分割する(16×16がViTでは使われているが、より小さいほうが密な予測タスクには向いているとこのこと)
③それらのパッチを入力として階層的Transformerエンコーダに与える
④複数レベルの特徴量(オリジナル画像の1/4, 1/8, 1/16, 1/32の解像度)を出力し、MLPデコーダに与える。
⑤MLPデコーダからH/4×W/4×Nclsのセグメンテーションマスクを得る
階層的Transformerエンコーダ(Hierarchical Transformer Encoder)
ViTに影響を受けながら、PVTをベースに異なる特徴量マップを生成できるMix Transformer エンコーダを作成したことにポイントがあります。ほかの改良としては、計算量のボトルネックになるエンコーダのSelf-Attention層でKの次元を減らすことで計算量を減らしています。
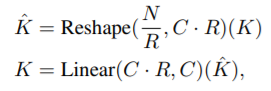
こうすることで、もともとのK=H×W×C次元から(H×W)/R×C次元に削減しています。このことで、全体計算量オーダーがO(N**2)からO(N**2/R)まで減らすことが出来ます。
軽量MLPデコーダ(lightweight All-MLP Decoder)
MLPデコーダでは高解像度の特徴量と低解像度の特徴量という異なるスケールの情報をシンプルつかつ効率よく統合することが目的です。実際には以下のような計算が行われています。

CNNよりも広い受容野を達成しています。
効果的な受容野
SegFormerでは、MLPを利用することで効果的に情報を統合することでより広い受容野の獲得に成功しています。これは大域的Attentionからもたらされるもので、同じようなデコーダをCNNベースのモデルに接続しても同様の効果は得られなかったとしています。

さらに重要なこととして、SegFormerのデコーダ設計は、高度に局所的なAttentionと大域的な(=非局所的な)Attentionの両方を同時に生み出すTransformerの特徴を本質的に利用している点であるとしています。これらの情報を統一することで、MLPデコーダは、わずかなパラメータを追加するだけで、補完的で強力な表現を行うことができるようになっています。単に大域的なAttentionの情報を渡すだけでは、精度の向上はできません。
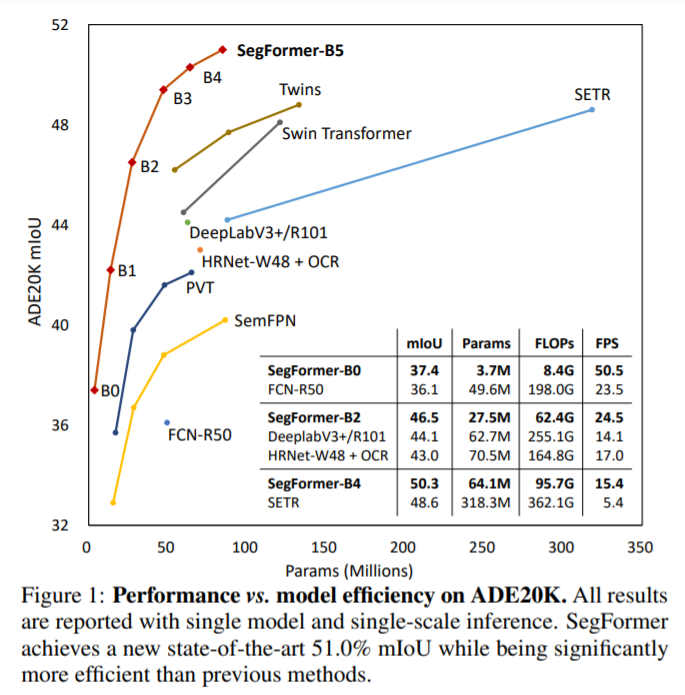
実験結果
基本的なセグメンテーションタスクで効率と精度で大幅な向上を達成しました。
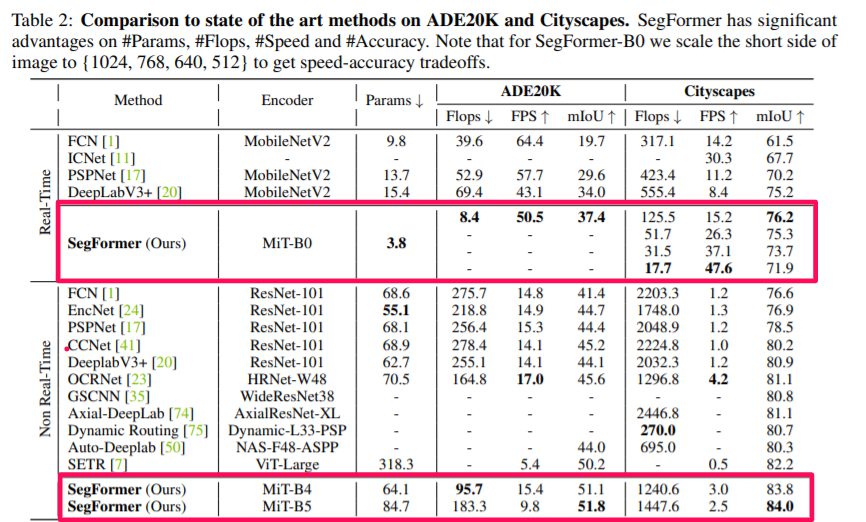
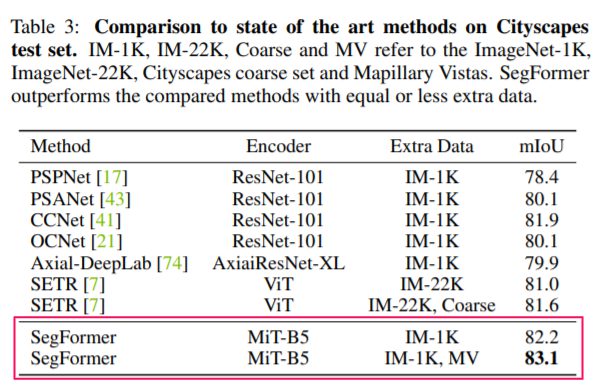
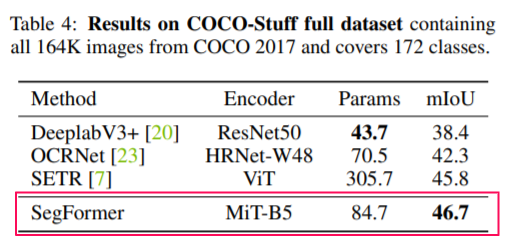
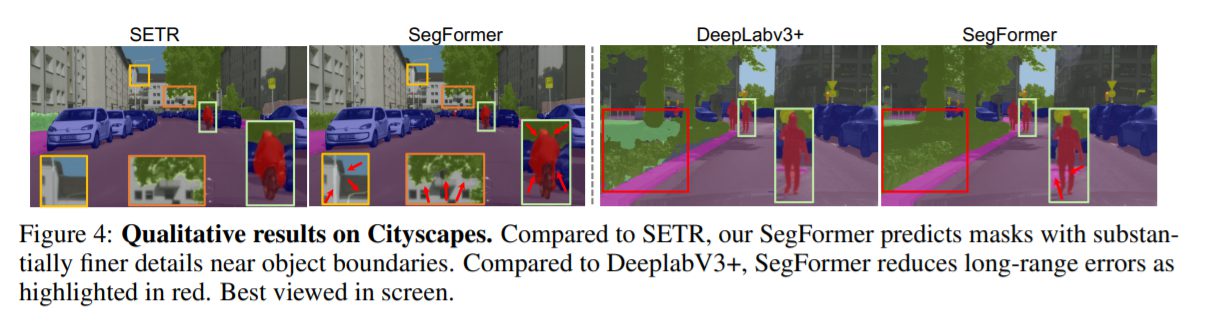
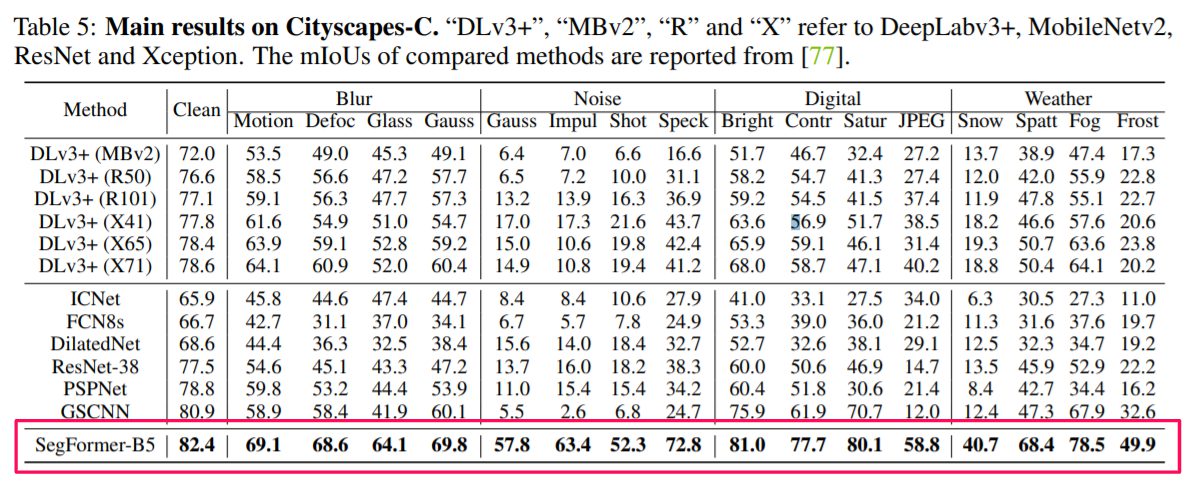
劣悪な環境下に対するロバスト性実験
SegFormerはどのような状況下であっても最高精度を達成することが出来ています。
課題
現状の課題として、最小の3.7Mパラメータモデルは既存のCNNのモデルよりも小さいといえども、100k程度のメモリしかないエッジデバイスのチップでうまく機能するかどうかはわからないということを挙げており、将来的な研究課題としています。
まとめ
効率、精度、ロバスト性などは安全性を保障するために重要な観点ですが、今回のSegFormerはこれらを大きく改善しており、セマンティックセグメンテーションモデルの境界を大きく押し広げるものであると研究チームは考えているようです。特に、自律走行やロボットのナビゲーションなど、知覚と認識を伴う幅広いアプリケーションに役立つとしています。またよりコンパクトなモデル群を提案したことで、より少ない学習資源で済むため、二酸化炭素排出量の削減にもつながりとしています。