
「Language Models are Unsupervised Multitask Learners」はOpenAIが2019年に発表した自然言語処理モデルGPT-2に関する論文です。2023/7/14時点ではGPT-4まで発表されており、本論文は旧モデルの研究について書かれています。
Language Models are Unsupervised Multitask Learners
参照URL:
https://www.slideshare.net/DeepLearningJP2016/dlselfsupervised-learning-from-images-with-a-jointembedding-predictive-architecture
概要
「質問に答える」、「翻訳をする」といった自然言語処理の技術は従来、特定のタスクに特化した学習によって発展してきました。本論文では WebText と呼ばれる数百万ものウェブページをデータセットとして訓練することにより、事前学習のタスクから取得された特徴量が複数のタスクに対しても利用できる汎用的なモデルになることが明らかになりました。本モデルは、特定のタスクに対して追加で大量のデータセットを用意せず、少量のデータセットでファインチューニングしても、特定タスク用に作成された従来モデルよりも性能がよい結果を出しています。また、未学習のタスクを処理するためにはモデルの容量も必要不可欠ですが、GPT-2は1.5Bの容量があり十分であるとしています。
詳細解説
イントロダクション
既存の機械学習システムは、特定のタスクに特化するように構築されており、タスクが変更されるとシステムが期待通りの性能を発揮しないことがありました。そのため、本研究では多くのタスクに精度よく対応でき、最終的には教師ありデータを用意しなくても機能するシステムの開発を目指しました。
現在の言語処理に関する最も優れたシステムでは事前学習と転移学習が組み合わされています。このアプローチには長い歴史があり、より柔軟な転移学習が好まれる傾向にあります。最近ではタスク固有のアーキテクチャはもはや必要なく、自己注意ブロックの転移のみで十分であることが示唆されています。これらの方法でも言語モデルの教師あり学習が必要ですが、教師データがほとんど利用できない場合にも、常識的推論や感情分析といった特定のタスクを言語モデルで処理できることが先行研究で実証されています。
本論文ではこれらの二つの作業ラインを結びつけ、これまでの転移学習の発展傾向に従う形で研究を進めています。本モデルはパラメータやアーキテクチャの変更をすることなく多様なタスクを処理することができることが実証されています。
アプローチ
本研究のアプローチの核は言語モデリングです。言語モデリングは変数長のシーケンス(s1,s2,…,sn)からなる一連の例(x1,x2,…,xn)からの教師なし分布推定としてとらえられます。言語は自然な順序付けがあるため、シンボルの結合確率は、以下のように条件付確率の積として因数分解されることが一般的です。
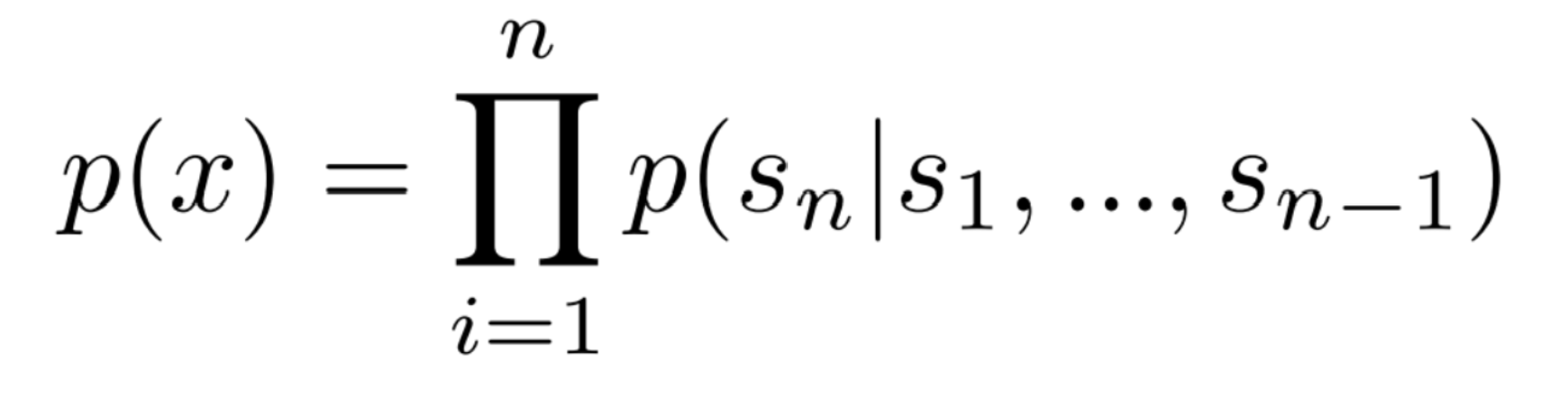
このアプローチでは、言語モデリングを使用して条件付確率を推定し、多様なタスクを実行することが可能です。本研究では、十分な容量を持つ言語モデルが、自然言語のシーケンスからタスクを推論・実行し、さらに予測を向上させるために学習をはじめる可能性があるという仮説をたて、この仮説を検証するために様々なタスクに対するゼロショット設定でのパフォーマンスを分析しています。
データセット
従来の言語モデルの訓練はニュース記事や小説といった単一ドメインのテキストデータセットに限定されていましたが、本研究では多様なデータセットで訓練することを目指しました。多様なテキスト情報源として Common Crawl などのウェブスクレイプが挙げられますが、データの品質に問題があります。そのため、本論文では人間によってキュレーションされたWebページからテキストを収集するというドキュメントの品質を重視した新しいスクレイプ方法が導入されました。
入力表現
一般的な言語モデルは、Unicode 文字列をUTF-8バイトのシーケンスとして処理することで、任意の文字列の確率を計算できます。しかし、単語レベルの言語モデルに比べるとバイトレベルの言語モデルは、大規模なデータセットでの競争力がありませんでした。それに対し Byte Pair Encoding(BPE)は頻出の記号列に対して単語レベルの入力を効果的に行い、頻度の低い記号列に対して文字レベルの入力を行う、実用的な中間解決策です。しかし、BPE は Unicode のコードポイントを操作するため、非常に大きな語彙が必要になります。バイトレベルの BPE を使用することで、語彙のサイズを 256 まで制限することはできますが、バイトシーケンスに BPE を直接適用すると効率的なマージが妨げられます。この問題を解決するため、本研究ではバイトシーケンスを扱う際に文字カテゴリを超えたマージを防止する手法を取り入れました。
この入力表現を使用することによって、単語レベルの言語モデルの利点とバイトレベルのアプローチの汎用性を組み合わせることができます。また、任意の Unicode 文字列に対して確率を計算することができるため、前処理、トークンか、語彙サイズに関係なく、さまざまなデータセットで言語モデルを評価することができます。
モデル
本研究では、Transformer ベースのモデルが使用されており、 既存のGPT モデルと大部分は同じですが、いくつかの変更が加えられています。まず、層正規化はサブブロックの入力に移動されており、追加の層正規化が行われています。また、モデルの深さによる残差パスの累積を考慮して、初期化時には残差層の重みを1/√N(Nは残差層の数)の倍率でスケーリングされています。さらに、語彙における50,257までの拡張、コンテキストサイズにおける 512 から 1024 トークンまでの拡大などが行われ、より大きな 512 のバッチサイズが使用されています。
実験
研究では下表のようにサイズの異なる4つの言語モデルが訓練され、ベンチマークテストが行われました。最小のモデルは既存の GPT と同等であり、2番目に小さいモデルは BERT の最大モデルと同等です。一方、最大のモデルである GPT-2 は他モデルと比べると10倍以上のパラメータを持っています。また、モデルの学習率は最適なパープレキシティを得るために手動で調整され、現時点ではまだ Web Text に対して適合不足であることが指摘されています。
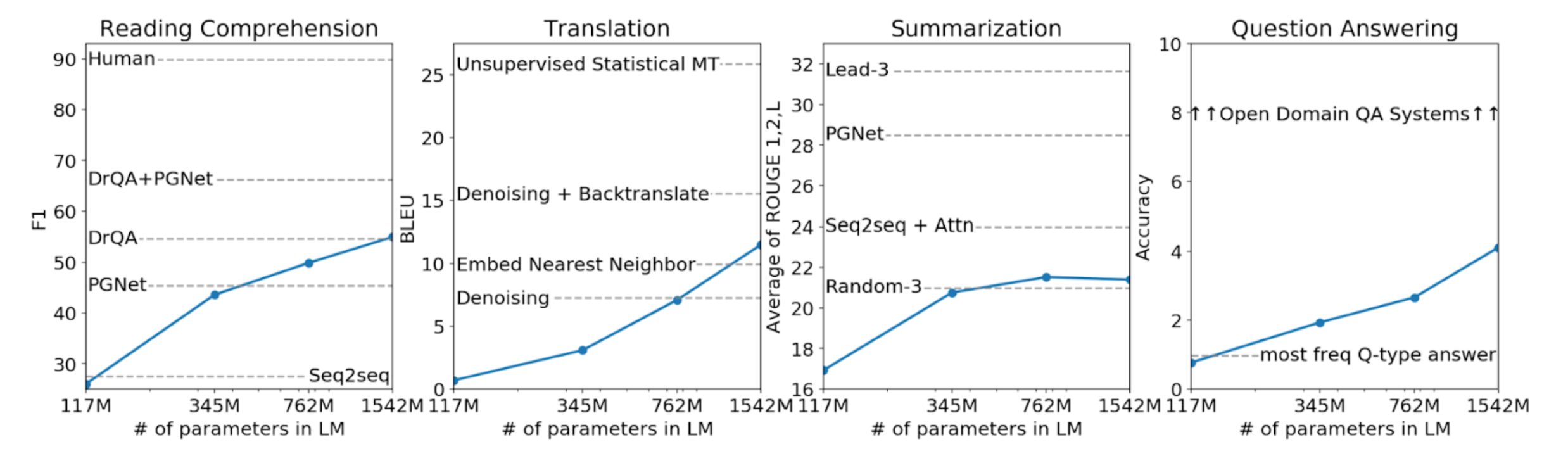
以下の図は4つのモデルにおける「読解」「翻訳」「要約」「質問応答」のタスクに対するゼロショットパフォーマンスを示しています。
言語モデリング
ここではWeb Text 言語モデルのゼロショットのドメイン転送における評価について説明されています。 Web Text 言語モデルは、言語モデリングという主要なタスクで訓練されており、バイトレベルで動作するため、損失の多い前処理やトークナイゼーションは必要ありません。そのため、任意の言語モデルのベンチマークテストで評価することができます。
実験では、WebText 言語モデルによるデータセットの対数確率を計算し、正規化単位数で割ることを評価しました。多くのデータセットでは、Web Text 言語モデルはドメイン外の予測を行う必要があり、標準化されたテキストやトークナイゼーションのアーティファクト、入れ替えられた文などを予測する必要があります。しかし、逆トークナイザを使用することでこれらのアーティファクトを最小限に抑えることができます。
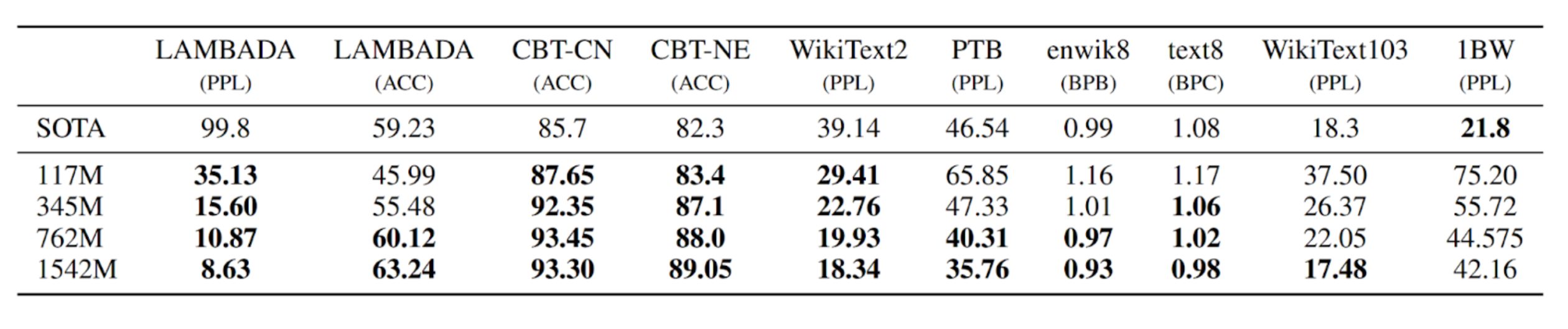
その結果、下表のように、Web Text 言語モデルはゼロショットの設定において、ほとんどのデータセットに対して既存のモデル性能を上回っていることがわかりました。特に、トレーニングトークンが 100~200 万しかない小規模なデータセットや、長期依存関係を測定するために作成されたデータセットでは大きな改善が見られました。ただし、最大のデータセットである One Billion Word Benchmark では、既存の研究と比較して性能が低くなっています。これは、このデータセットと前処理の組み合わせがすべての長文構造を取り除いているためであると考えられます。
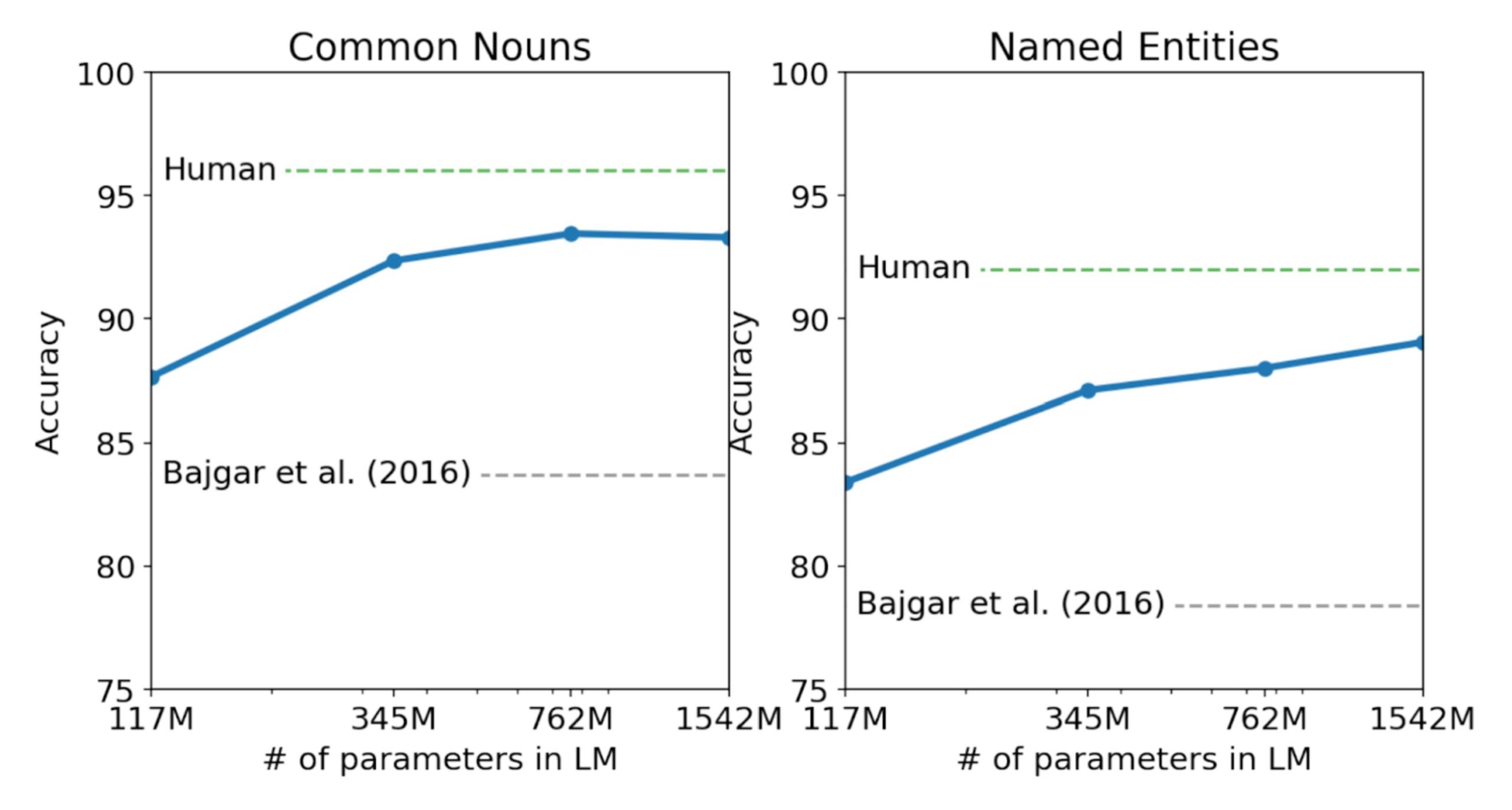
子供向けの本によるテスト
Children’s Book Test(CBT)は、固有名詞、名詞、動詞、前置詞の異なるカテゴリの単語に対する言語モデルの性能を評価するために作成されました。CBT では、パープレキシティではなく正解率を報告し、自動的に作成されたクローズテストにおいて、欠落した単語の正しい選択肢を予測する課題を行います。下図に示されているように、モデルサイズが大きくなると性能が向上し、人間のパフォーマンスとの差を縮めることができます。また、 CBT の結果は、データの重複を考慮して報告されており、GPT-2 は一般的な名詞に対して93.3% 、固有名詞に対して 89.1% という非常に高い成績を残しました。この時、CBT から PTB スタイルのトークナイゼーションのアーティファクトを除去するために逆トークナイザが使用されました。
LAMBADA データセット
LAMBADA データセットは、テキスト内の長い依存関係をモデル化する能力を評価するためのものです。GPT-2 は、これまでの最高モデルのパープレキシティを99.8から8.6に改善し、正確性を19%から52.66% に向上させるなど、高い成績を残しました。GPT-2 は、文脈の最後の単語を予測するタスクにおいて、最後の単語という制約を考慮せずに予測を行っています。また、ストップワードフィルタの追加により、さらに正解率が63.4% まで向上し、既存モデルから 4% の改善が見られました。先行研究では、モデルの出力を文脈に現れる単語のみに成約した異なる制限付きの予測設定が使用されていましたが、これによりモデルの性能低下が見られたため、本研究では前処理を行わないデータセットが使用されています。
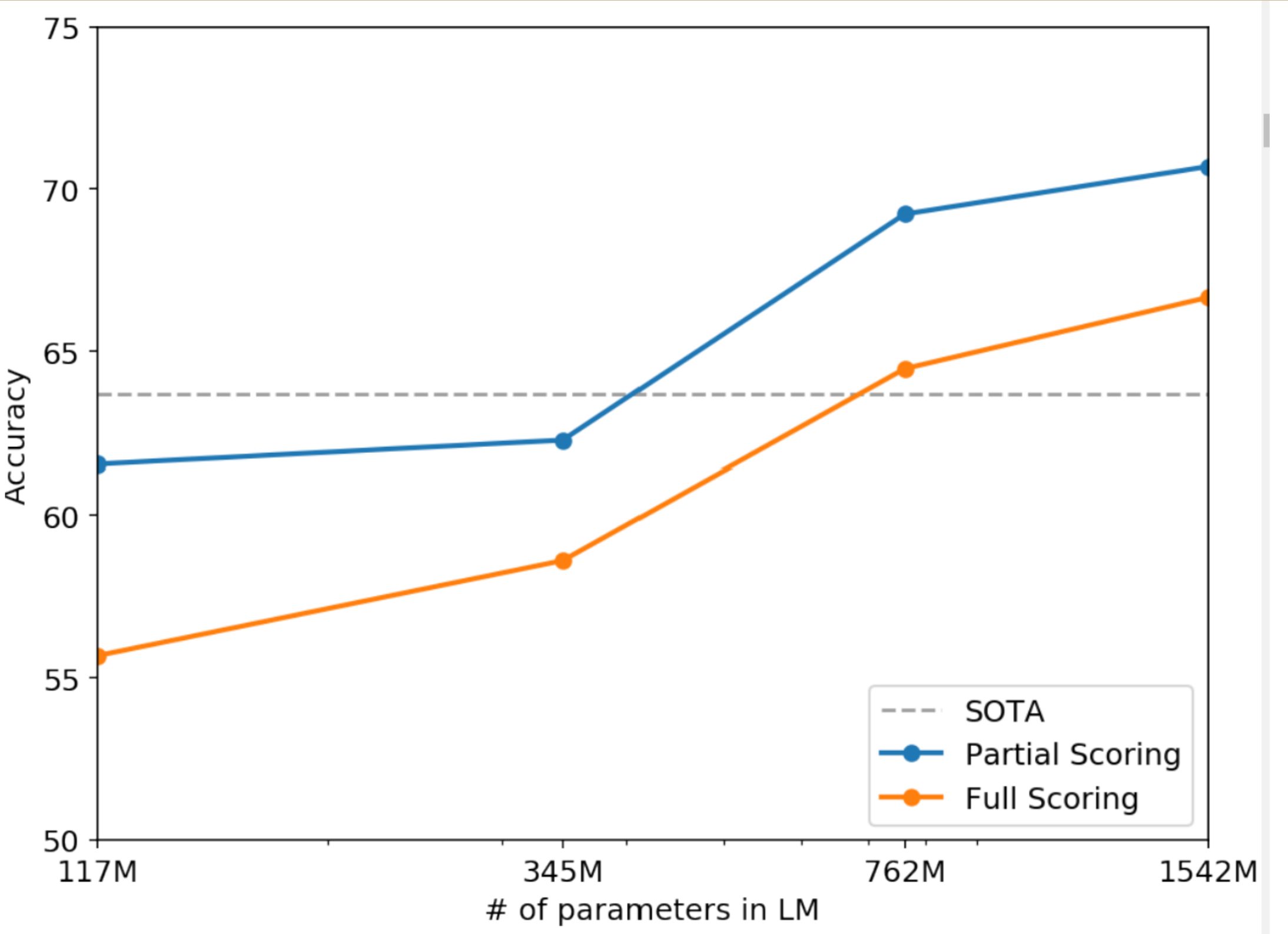
Winograd Schema Challenge
Winograd Schema Challenge は、システムがテキストのあいまいさを解決する能力を測定するもので、システムの常識的な推論能力を評価するために作成されました。近年、Trinh & Le (2018) が言語モデルを使用してこの課題について大きな進展を達成し、本研究でもその問題設定を用いて、下図のようにモデルのパフォーマンスを完全なものと部分的なものに分けてスコアリング技術で可視化しました。GPT-2 は、この課題で正解率を 7% 向上させ、70.7% を達成しました。ただし、データセットが小規模であることから、結果の評価には関連研究の参照(Trichelair et al., 2018)が推奨されています。
読解
CoQA(Conversation Quetion Answering)データセットは、異なるドメインの文書とそれに関する対話からなる質問応答の評価セットです。GPT-2 は教師なし学習のみでこれに取り組み、ベースラインシステムのうち3つを上回るパフォーマンスを達成しました。しかし、GPT-2 の回答の検査から、単純な情報検索のヒューリスティックを使用する傾向にあることがわかりました。例えば、who の質問に対して質問の内容にかかわらず文書内の名前を解答するなどの傾向が見られました。
要約
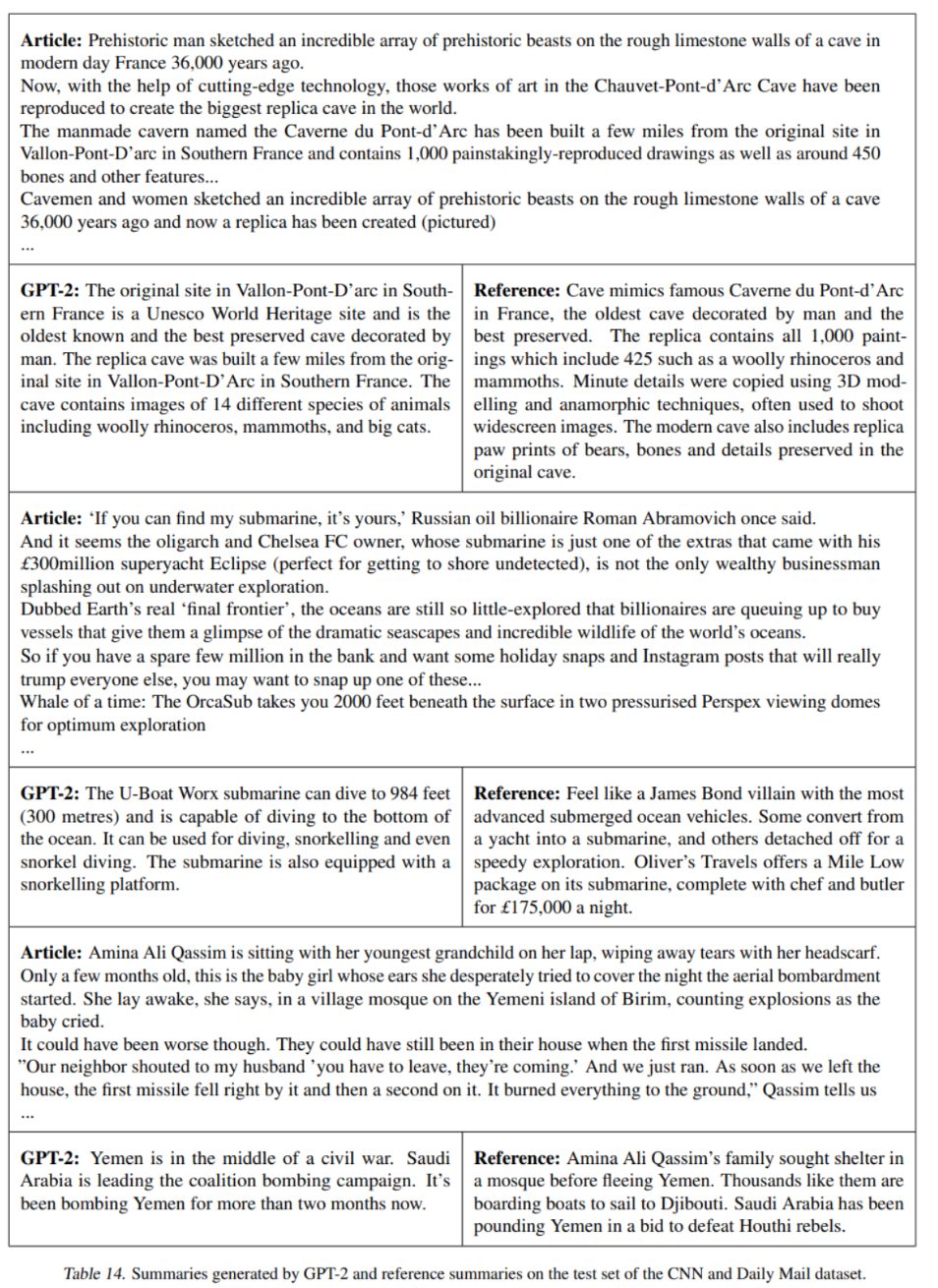
CNN とデイリーメールのデータセットでは、 GPT-2 の要約能力の検証がされました。下の表にGPT-2 にあたえられたデータセットと出力例を示しています。これらの例からもわかるように、生成された要約は、記事の最新の内容に焦点を充てたり、具体的な詳細を混同してしまう傾向にあります。ROUGE メトリックでは、従来の古典的なニューラルベースラインの性能と同程度で、記事の文をランダムに選択することとほとんど変わりません。また、タスクヒントが削除されると GPT-2 の性能は低下し、このことは GPT-2 が自然言語においてタスク固有のふるまいを引き出す能力を持っていることを示しています。
翻訳
さらに、本研究ではGPT-2 の異なる言語間の翻訳性能についてテストを行いました。結果、英仏翻訳では先行研究の単語翻訳よりもわずかに劣り、仏英翻訳では GPT-2 の強力な英語の言語モデルをかつ法することで、従来の教師なし機械翻訳のベースラインよりも優れた性能を発揮しました。ただし、現在の最高水準の教師なし機械翻訳手法には及んでいません。このタスクのパフォーマンスにおいて注目すべき点は WebText から非英語のウェブページがフィルタリングされ除外されていた点です。
質問応答
言語モデルの情報量を評価する方法の一つとして、事実型の質問に対して正しい解答を生成する頻度を調べることが挙げられます。GPT-2 はこのテストで約 4.1% の正解率を示しました。(cf. 最も小さいモデルでは1.0% 以下の正解率)このことから、モデルの容量がこの種のタスク性能に大きく影響していることがわかります。GPT-2 の生成された回答の予測確率は適切にキャリブレーションされており、最も自信のある 1% の質問に対しては 63.1% の正解率を示しました。しかし、GPT-2 のパフォーマンスは、情報検索と抽出型ドキュメント質問応答を組み合わせたオープンドメインの質問応答システムに比べはるかに低いものとなっています。
一般化vs暗記
最近のコンピュータビジョンの研究ではトレーニング画像とテスト画像の間で重複する画像が含まれていることによって、機械学習システムの汎化性能が過大評価されることがあります。データセットのサイズが増えると、この問題はさらに発生しやすくなり、本研究で用いている WebText でも同様の現象が起こっている可能性があるため、テストデータとトレーニングデータが重複している割合を分析することが重要です。
この分析のため、本研究では WebText トレーニングセットのトークン8グラムを含む Bloom フィルターを作成し、データセットごとにトレーニングセットとの8グラムの重複率を計算しました。下表は一般的な言語モデルのベンチマークのテストセットにおける重複分析の結果を示しています。WebText トレーニングセットでは1〜6% の重複を持ち、平均 3.2 %の重複であるのに対し、データセットトレーニングではより重複率が大きくなっており、平均 5.9% の重複があります。全体的にWebText をトレーニングデータとして用いることでわずかに重複率が向上しているといえます。

考察
これまでの研究では、教師ありと教師なしの事前トレーニング手法の表現に関しての学習と評価が行われてきましたが、本研究の結果によって、教師なしのタスク学習が有望な研究領域であることが示されました。GPT-2 のゼロショットパフォーマンスは、読解などの一部タスクでは従来モデルよりも高い性能を発揮しましたが、ほかのタスクではまだ改善の余地があります。さらなる研究によって、GPT-2 のパフォーマンスを向上させていく必要があります。
結論
十分に多く種類に富んだデータセットを用いて言語モデルを学習させることで、多くのドメインやデータセット上でのパフォーマンスを向上させることができます。GPT-2のゼロショットパフォーマンスは8つのうち7つの言語モデルデータセットで最も高い性能を発揮しました。また、ゼロショットでモデルが実行できるタスクが多様性に富んでいることから、多様なテキストコーパスの尤度を最大化するようにトレーニングされた高容量モデルが、教師なしで多くのタスクを学習し始めるということがわかります。
まとめ
最新モデルGPT-4が公開され注目が集まっているChat GPTですが、今回はGPT-2の開発プロセスについて解説しました。