
Microsortから発表されたテーブルデータにLLMを適用するためのTable-GPTを紹介します。
テーブルタスクの理解能力を向上させるために、テーブルタスクのトレーニングデータを使用して言語モデルを「テーブルチューニング」する新しいパラダイムを提案しています。
URL:https://arxiv.org/abs/2310.09263
1.イントロダクション
近年の言語モデルは多様な自然言語タスクでの優れた能力を示していますが、信頼性の高い「テーブル(表)」の読解は課題となっています。
自然言語の特徴:
(1)一方向性。
(2)左から右への読み出し。
(3)2つのトークンの位置を入れ替えると、文の意味が変わる可能性がある。
テーブルデータの特徴:
(1)二次元の性質を持ち、行と列の両方が存在する。
(2)同じ列の値を垂直に読むことが重要。
(3)行や列の並び替えによっても、テーブルの意味が変わることは少ない。
テーブルを用いたタスク例:
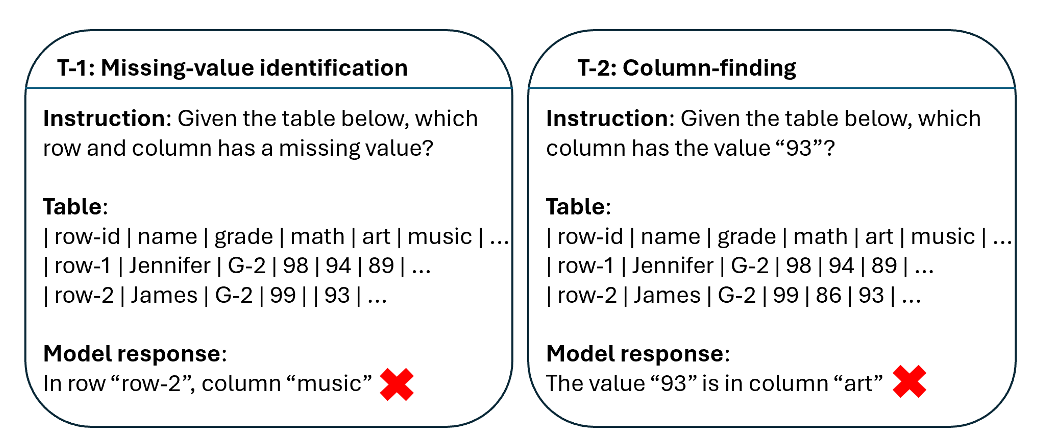
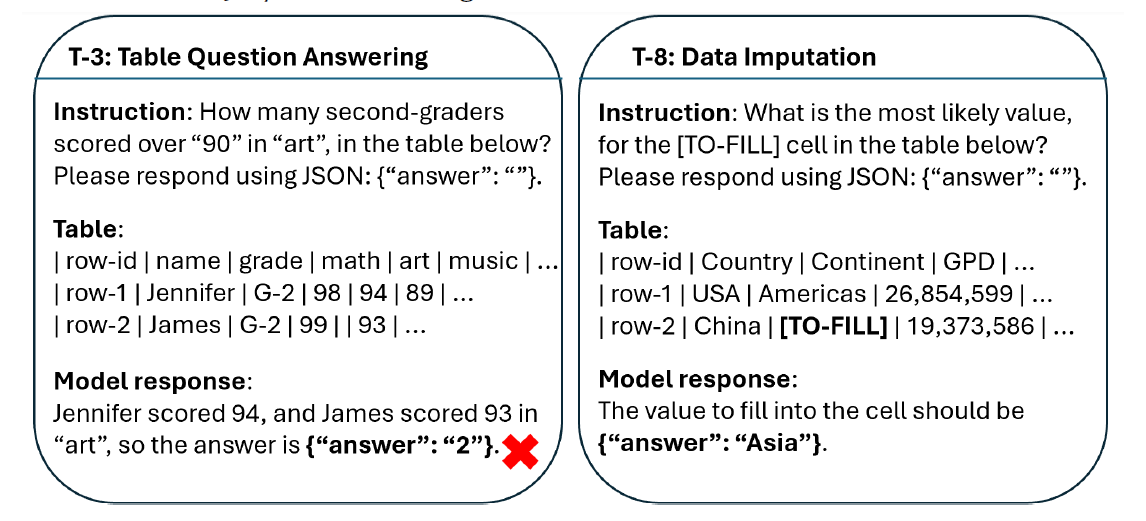
しかし、例えば175B GPT-3.5のような大規模モデルでも、これらのタスクでの精度は低く、一部のバリエーションでの精度は0.26となる場合があります。
そのため、本研究は「テーブルチューニング」という新しいアプローチを提案することで改善を図ります。この方法では、プロンプトの修正ではなく、多様なテーブルタスクを学習データとして使用して、言語モデルの重みを調整します。
2.テーブルチューニング
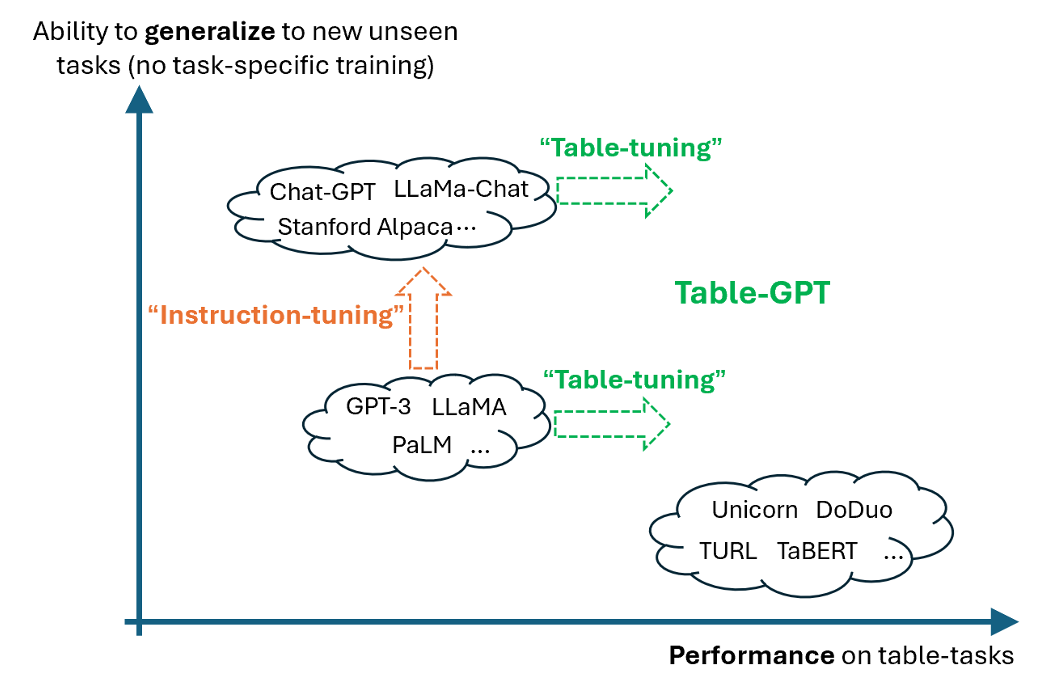
本研究で提案されているテーブルチューニングは、さまざまなテーブルタスクを効果的に実行する能力を持つモデルを目指しています。
プロンプトエンジニアリング(プロンプトの最適化)とは異なりますが、テーブルチューニングは、基本的な言語モデルを一度だけ訓練し続けることで(タスク固有ではありません)、さまざまなテーブルタスクでの性能向上を目指す方法を提案しています。テーブルチューニングは、プロンプトエンジニアリングを補完するものとして位置づけられています。慎重に設計された命令や例は、GPTとTable-GPTの両方に利益をもたらすことがあり、その効果は実験によって示されています。テーブルモデルが新しいデータセットや新しいタスクに「汎化」することは、理想的な状態と考えられています。
テーブルチューニングの例
列タイプアノテーション(CTA)
一般的なテーブルタスクにおけるターゲットタイプの選択は、データセットによって異なります。再トレーニングなしに新しいCTAデータセットに「汎化」するテーブルモデルを作成することは、非常に有益です。
テキストからテーブルを抽出
一般的なテーブルモデルは、新しい未知のテーブルタスクを実行するための指示に従う能力が求められます。(例:「テキストからテーブルを抽出する」というタスクを実行します。)ChatGPTのようなモデルと同様に、汎用性は非常に重要です。
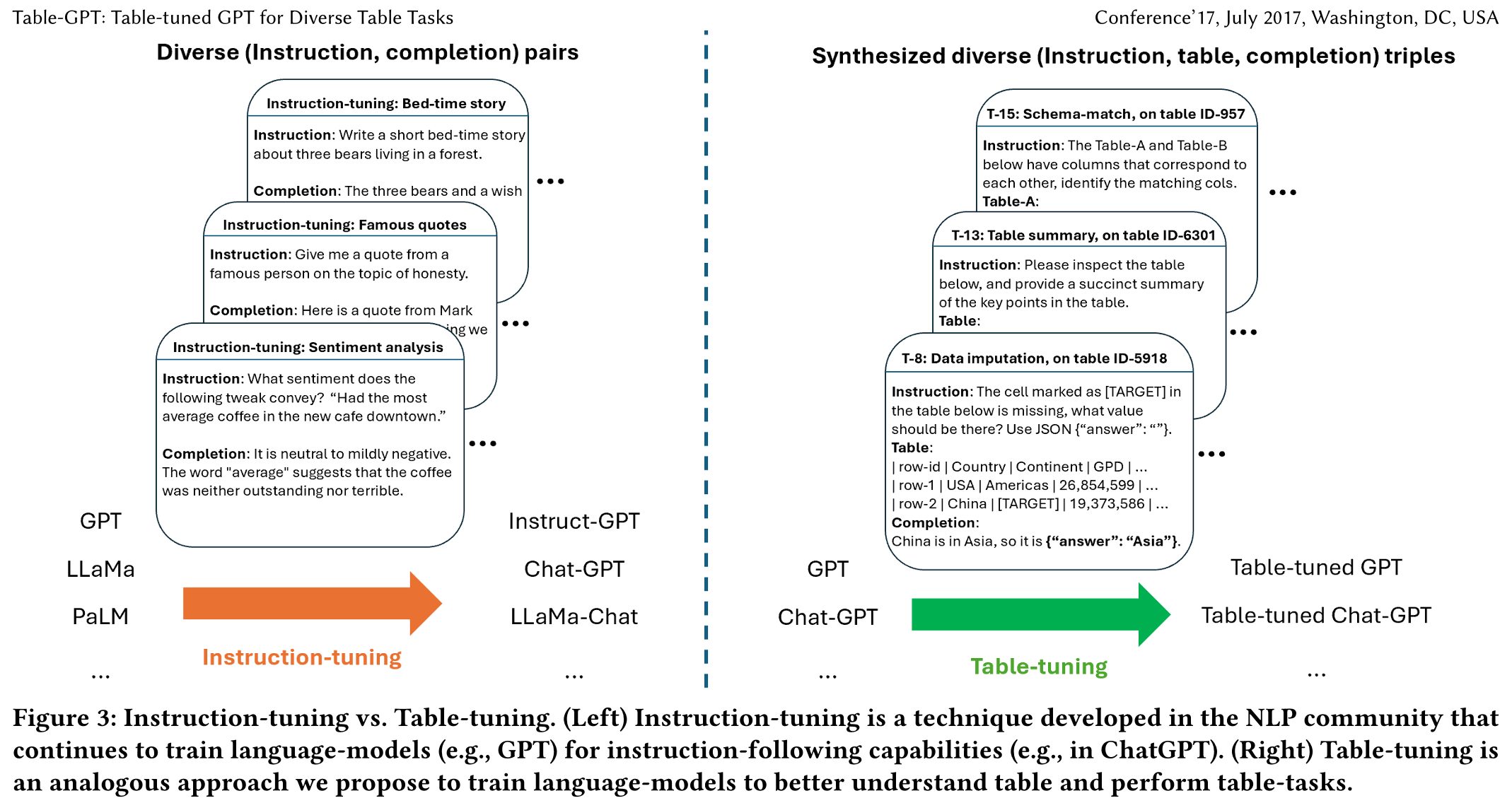
テーブルタスクとテーブルチューニング
テーブルチューニングは、テーブルを理解し、テーブルタスクの実行能力を高めることを目的としています。この技術により、テーブルタスクの汎化性と性能が向上し、さまざまなテーブルタスクを効果的に処理する能力を持ったモデルの構築が可能となります。
3. 言語モデルはテーブルを「読む」ことができるか?
一次元(テキスト) 対 二次元(表)の違い
言語モデルは、テキストの順序に非常に敏感です。例えば、単語の順序を変えるだけで、その文の意味が大きく変わってしまいます。一方、テーブルは順序にそれほど敏感ではありません。行や列の順序を入れ替えても、その基本的な意味は変わりません。しかし、これが言語モデルをテーブルタスクに適用するときの課題となります。具体的には、列の順序によって、モデルの出力結果に大きな影響を受ける可能性が考えられます。
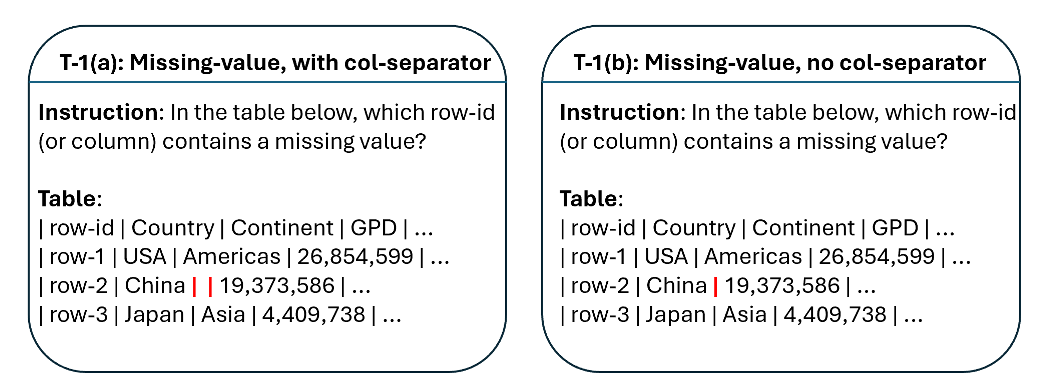
欠損値の取り扱いについて
テーブルにおける欠損値を補完する際のアプローチとして、まずは水平方向、そして垂直方向を見ることが一般的です。例えば、コラムヘッダー(「大陸」という名前の場合)や、そのコラム内の他の値(「アメリカ」といった値)を参考にして、最も適切な値を推測します。
セルの誤りを判断する方法
テーブル内のあるセルの値が誤っているかどうかを判断するためには、そのセルが所属する列のカラムヘッダーや他の値を確認し、列全体の意味を正確に理解することが不可欠です。
テーブルとテキストのその他の違い
さらに、テーブルはテキストとは異なる特性を持ちます。例えば、テーブルセル内の短い名前や、列に均質な値が格納されていること、また、正規の関係をエンコードする情報などが含まれています。これらの特性は、テーブルとテキストの明確な区別を生む要因となり、言語モデルをテーブルタスクに適用する際の難しさを引き起こしています。
TableGPT-TUNNING
TableGPT-TUNNINGの取り組みでは、テーブルタスクの幅広い適用に焦点を当てており、新しいテーブルタスクや既存のテーブルタスクの新しいテストケースの作成に向けた2つのアプローチを提案しています。
①多様な実テーブルの活用
実際のテーブルデータを大量に利用し、テーブルの理解、補強、そして操作に関するタスクを合成します。これは、言語モデルが2次元のテーブル構造をどれだけ正確に理解し、その能力をどれだけ向上させることができるのかを検証するためのアプローチとなります。
②テーブル要約タスクの導入
テーブル要約タスクとは、モデルにテーブルの内容を要約するように指示するものです。これにより、言語モデルがテーブルタスクをどれだけ効果的に実行することができるのか、多様な学習データを通じてその能力を向上させることを目指しています。
その他のテストについて
その他のテストとして、モデルがテーブルをどれだけ適切に操作する能力を持っているのかを評価します。具体的には、行や列を整列するタスクや、特定の列の値に基づいてテーブルの行をソートするソートタスク、さらには列ヘッダをシャッフルして再配置するヘッドバリューマッチングタスクなどが含まれています。これらのタスクは、モデルがテーブルの意味をしっかりと理解し、それをもとに正確に操作できるかを評価することを目的としています。
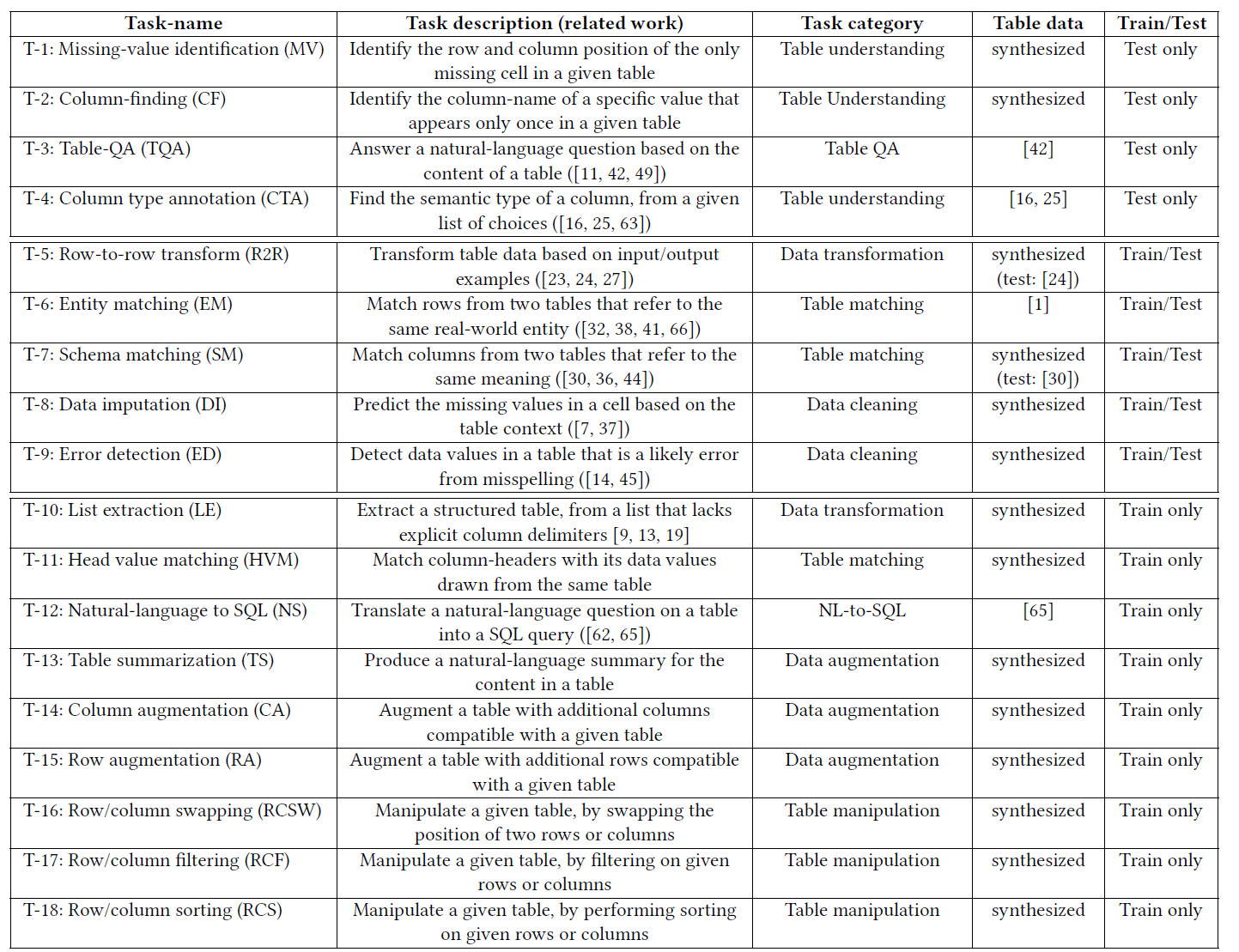
テーブルチューニングするために収集・合成した18のテーブル関連タスクの概要
テーブル関連タスクは、テーブルに関連する様々な作業を指し示します。今回ご紹介するタスクでは、テーブルの理解からテーブルの質問応答(QA)、テーブルマッチング、テーブルクリーニング、テーブル変換など、多岐にわたる分野をカバーしています。
中でも、T-1からT-4までのタスクは特別なもので、これらは未知のホールドアウトタスクとして扱われます。これにより、Table-GPTの未知の新しいタスクへの適応能力、すなわち汎化能力をしっかりと評価できます。
教師データを自動的に生成できる場合
教師データを自動で生成することができる場合には、その利点を活かして学習データの多様性を確保します。特に、過学習を避けるために、さまざまな実テーブルからテーブルタスクを「合成」し、より広範な学習を可能にします。
教師データを自動的に生成できない場合
一方で、教師データを自動生成できない場合、例えばエンティティマッチングやtable-QA、NL-to-SQLなどのタスクでは、既存の研究や文献に記載されているベンチマークデータを利用することとしています。
4.1 テーブルチューニングのアルゴリズム

テーブルチューニングのアルゴリズムは上記の通りになります。
本論文では、「合成-拡張」アプローチを提案しています。このアプローチを活用し、学習データとして言語モデルのテーブルチューニングを進めます。
具体的な手順として、2行目に示されているように、実際のテーブルの大規模なコーパス、𝐶からテーブル𝑇をランダムに選択します。同時に、テーブルタスク𝑆の種類もサンプリングします。
3行目では、選択されたテーブル𝑇とタスク𝑆の組み合わせから、具体的なテーブルタスク𝑡を合成します。
4行目では、このタスクの合成を実際に実行します。
次に、6-8行目で説明されている手順に移ります。こちらでは、生成されたテーブルタスクのさまざまなインスタンスから、命令やテーブル、そして完了レベルでのタスクを追加していきます。
最終的に、9行目に示されているように、これらのテーブルタスクの集合 𝐴が学習データとして用意され、言語モデルのテーブルチューニングに活用されます。
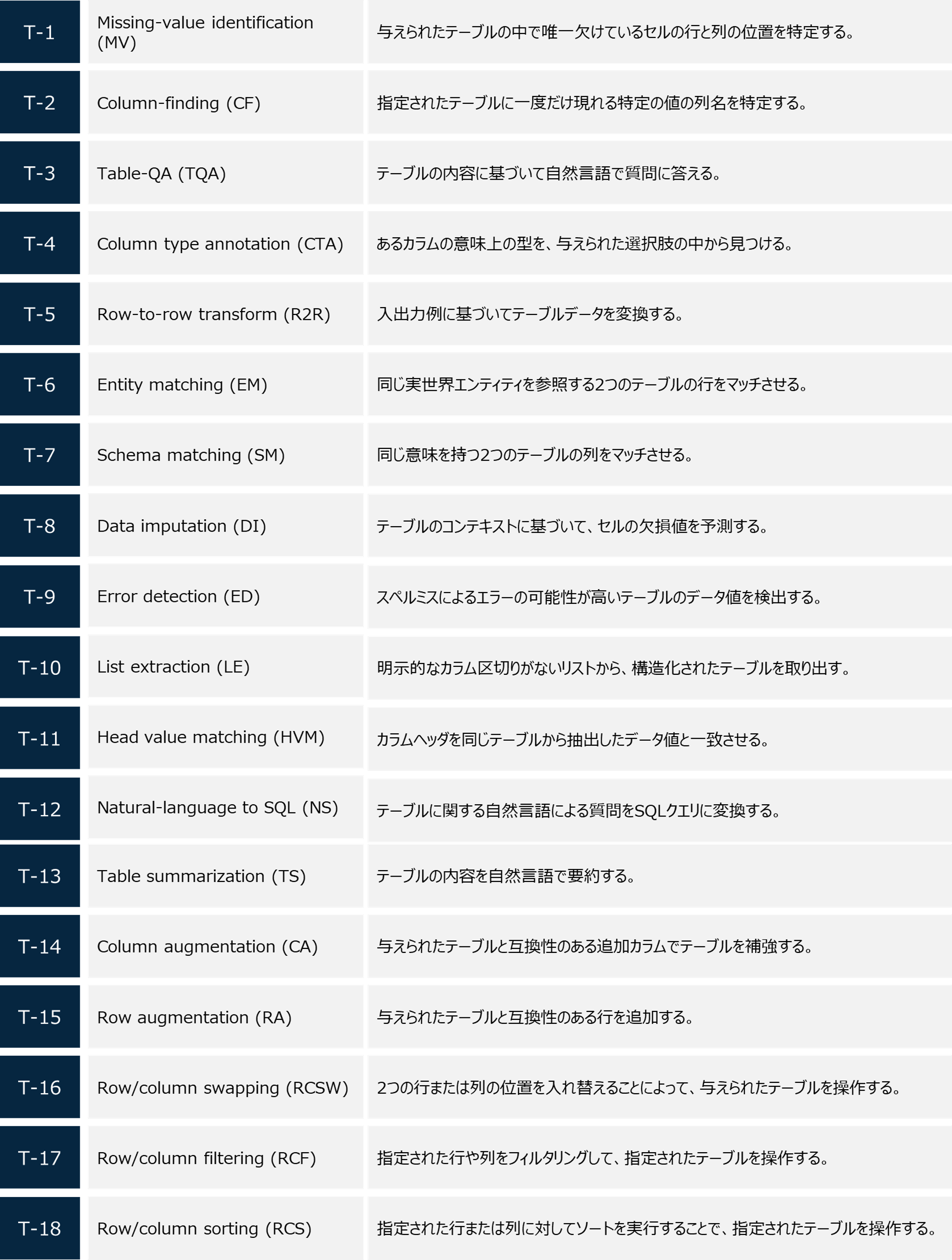
4.2 多様なテーブルタスクの合成
以下の表にまとめています。詳細は論文を参考ください。
4.3 Augment synthesized テーブルタスク
テーブルタスク 𝑡 = (𝐼𝑛𝑠,𝑇, 𝐶)の合成インスタンスから、アルゴリズム1の6行目〜8行目の手順に従い、複数のレベルでのオーグメンテーションを追加的に行います。このオーグメンテーションの目的は、タスクやデータの多様性をさらに高め、テーブルチューニング時の過剰適合を避けることにあります。
命令レベルでのオーグメンテーション
命令レベルでは、訓練データインスタンスの間で同じ命令を繰り返すと、過剰適合が生じる恐れがあります。この問題を回避するため、GPTなどの生成モデルを活用して、正準の命令をオーグメンテーションします。例として、人間が記述した命令を異なる形に言い換えます。
例:
“Please look at the table below and provide a title that can summarize the table”
を
“Please examine the table below and give it a descriptive title”
というように変えます。
言語モデルを使用して、タスクの代替指示を生成することができます。このようにして、「以下の表を見て、説明的なタイトルをつけてください」というバリエーションを生成し、テーブルタスクのインスタンスを代替指示として入力することが可能です。
テーブルレベルのオーグメンテーション
2次元のテーブルは、テーブルレベルで「順列不変」の性質を持つべきです。これは、行や列の順序を変更しても、そのテーブルの意味が変わらないということを意味します。たとえば、列の順序を変えたり、行の順序を変えたりしても、似たような意味を持つテーブルが得られるべきです。
この考えを基に、列の順序を変更したり、行の順序を変更したり、また列や行をサンプルするといった操作を実行することで、テーブルタスクに使用されるテーブルの多様性を高めることができます。具体的には、学習データには、元のインスタンス 𝑡 = (𝐼𝑛𝑠,𝑇,𝐶) だけでなく、そのオーグメンテーションされた版である 𝑡′ = (𝐼𝑛𝑠,𝑇′, 𝐶) も含まれます。ここでの T′ は、T のオーグメンテーションされた版であり、元のテーブルTと同じ意味を持ち、同じ補完Cを持っています。
このような学習データを使用して言語モデルの学習を行うことで、テーブルに関するモデルの安定性が向上することが期待されます。さらに、「意味を保持したテーブル操作」、例えば列の並べ替えなどに対するモデルの感度を低減させることも期待されます。
補完レベルのオーグメンテーション
補完レベルにおいては、テーブルタスク 𝑡 = (𝐼𝑛𝑠,𝑇, 𝐶) の合成インスタンスを対象に、オーグメンテーションが行われます。具体的には、元々の補完𝐶を基に、追加の推論ステップを含む新しい補完𝐶′を生成することでオーグメンテーションを進めます。
このような方法でオーグメンテーションを行うと、特に複雑なテーブルタスク、たとえばエンティティマッチングやエラー検出などに対しての推論ステップが追加されると、タスクの性能が向上することが確認されています。このことから、オーグメンテーションを通じてテーブルタスクの質を向上させることが期待できると言えます。
言語モデルによる補完オーグメンテーション
エンティティマッチングのタスクでは、2つのテーブル行が同じ実世界のエンティティを参照しているかどうかを正確に識別することが求められます。このような状況で、言語モデルのチューニング前の段階において、2つの操作モードを試みました。
(1) 直接回答モード:モデルに「はい」または「いいえ」と直接回答させる方法です。
(2) 理由付き回答モード:モデルに答える前に、段階的に説明する手法です。
この試みの主な目的は、言語モデルをテーブルタスクに特化してチューニングし、複雑なテーブルタスクの性能を向上させるとともに、ステップごとの推論の流れをモデルに学ばせることにあります。
特に、エンティティマッチングのような複雑なタスクにおいて、「直接回答」モードのモデルは誤答が増え、精度が低くなる傾向が見られました。しかし、「理由付き回答」モードを採用することで、チューニング前の言語モデルであっても性能が向上しました。これは、ステップごとの推論を経ることで、より正確な答えを導き出せる可能性が増すためです。
このように、シンプルな「はい/いいえ」の回答から、詳細な推論過程を経ての回答へと移行することで、言語モデルに推論の流れを学習させることができます。GPTに「はい/いいえ」との回答を与えて新しい推論ステップを生成させることで、テーブルタスクに特化したモデルが、正しい推論手順を効果的に実行することが期待されます。
教師データを用いた補修のサポート
補完の強化に関する一例として、(T-9)のタスクのシナリオで、教師データを活用してステップバイステップの推論を形成しています。
誤字脱字の検出
タスクの内容: 提供されたテーブルの中から、スペルのミスを正確に見つけること。
問題点: 言語モデルは、誤字脱字の検出タスクにおいて、スペルミスが実際には存在しないのにも関わらず、スペルミスがあると誤って判定してしまう場合があります。このような偽の正の結果は、「ステップバイステップ」の指示があるかないかに関係なく発生します。
解決の手段: テーブルタスクの生成段階で利用できる教師データを活用し、補完の強化を行い、推論のステップを具体的に示す。
具体的な方法: 補完として、モデルの予測値と、スペルミスの正確な形を示す説明を付け加えます。例として、「ミスシピ」という誤ったスペルを「ミシシッピ」と正しく指摘する、というような手法です。
このアプローチによって、偽の正の結果が大幅に減少し、出力の質が向上することが確認されました。
4.4 “テーブル・ファウンデーション・モデルとしてのTable-GPT”
アルゴリズム1に基づく合成・拡張の手法を使用し、様々なテーブルタスクA = {(Ins,T, C)}を構築します。この方法で、言語モデル、例えばGPTの学習を進めていきます。この際、(Ins,T)は「プロンプト」として、Cは「completion」として扱われます。この学習の過程で、プロンプトが提供された際の言語モデリングによる完了の損失を最小にすることを目指します。この手法を「テーブルチューニング」と称しています。GPTやChatGPTなどのデコーダ型言語モデルをMとし、このテーブルチューニングを適用したモデルをTableTune(M)と呼びます。

続いて、以下の様々なシナリオで、TableTune(M)がテーブルタスクにおいて、元のモデルMよりも優れた性能を発揮することを検証しています。
(1) Out of the box zero-shot: MやTableTune(M)を使って、事前学習なしでテーブルタスクを実施する場合。
(2) Out of the box few-shot: 特定の指示と、ランダムに選ばれたいくつかの例を利用して、テーブルタスクを実施する場合。
(3) タスク固有のプロンプトチューニング: 下流のタスクのための少量のラベル付きデータが存在するとき、プロンプトチューニングを行い、最適な指示の組み合わせを選ぶ場合。
(4) タスク固有のファインチューニング: 十分な量のラベル付きデータが存在し、そのタスクのために特定のファインチューニングを行う場合。
実験
5.1 実験セットアップ
比較モデル
Table-GPT
基本としてのモデルは、ChatGPT (text-chat-davinci-002)を使用しています。このTable-GPTはテーブルチューニングが施されたモデルで、元となるChatGPTとの性能比較のために設定されました。
GPT-3.5
このモデルの名称は、GPT-3.5 (text-davinci-002)です。175Bの規模を持つこのモデルは、OpenAIから取得できます。このGPT-3.5は、GPTモデル群の代表的なものとして、他のモデルとの比較の際の基準として位置付けられています。
Table-GPT-3.5
ベースとしては、GPT-3.5 (text-davinci-002)を利用しています。このTable-GPT-3.5はテーブルチューニングを施した結果得られたモデルであり、元となるGPT-3.5の性能との比較が期待されます。
ChatGPT
このモデルの名称は、ChatGPT (text-chat-davinci-002)です。このChatGPTはその系列のモデルの一つとして挙げられており、特定のバージョン情報は明示されていません。
学習データの設定
標準的な設定として、14種類のテーブルタスク(T-5からT-18まで)が学習データとして採用されています。特筆すべきは、タスクタイプ T-6(Entity Matching)や T-12(NL-to-SQL)は、他のテーブルタスクとは異なり、合成されたテーブルタスクのインスタンスを使用しない点です。
タスクインスタンスの生成
セクション4で触れられている合成-拡張アプローチに基づき、各タスクタイプごとにゼロショットと少数ショットのテンプレートを50%ずつの割合で組み合わせ、合計で1000個のタスクインスタンスを作成します。
データのサンプリング
125kの実際のウェブテーブル(𝐶^𝑤𝑡)およびデータベーステーブル(𝐶^𝑑𝑏)からのサンプリングを行い、これによって2M以上のオリジナルテーブルが集約的に推定されます。
エンティティマッチングとNL-to-SQLの特別な処理
これらのタスクは、自動的な合成が難しいため、それぞれのタスクにおいて、手動でラベルが付けられたベンチマークデータセットを活用しています。
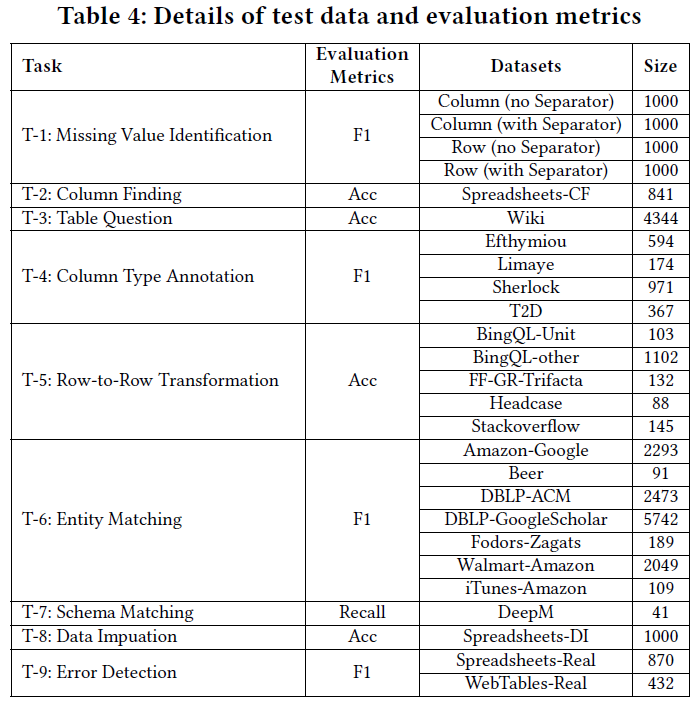
タスクとデータのテスト
評価目的:
テーブルチューニングを施したペアモデルと、テーブルチューニングを行っていないバニラモデルとの性能差を比較し、テーブルチューニングのメリットについて評価いたします。
比較対象となるグループ
今回の比較は、(GPT-3.5とTable-GPT-3.5)、および(ChatGPTとTable-ChatGPT)の2組み合わせに焦点を当てて行われます。
テストの内容:
新規の未知タスク、すなわちT-1からT-4までを対象にテストを行い、テーブルチューニングされたモデルが未知のタスクに対してどれだけの性能を発揮できるかを確認します。トレーニングデータとテストデータは完全に独立しています。
学習に使用されるデータ:
実際のテーブルデータ𝐶^𝑠𝑝のコーパスや、公認のベンチマークデータを用います。
テストに使用されるデータ:
実表テーブル𝐶^𝑠𝑝 のコーパスや確立されたベンチマークデータ。
追加で行われるテーブルタスクの評価:
T-5からT-9までの主要なテーブルタスクを評価し、テーブルチューニングを施したモデルがテーブル関連の概念をどれだけ理解しているかを確認します。
T-8タスクの内容:
新しいテーブルへの汎化能力をテストするために、実際の表計算テーブルのコーパス𝐶^𝑠𝑝からテストケースを抽出。
ベンチマークデータ:
既存のベンチマークデータを用いて、テーブルチューニングされたモデルの学習性能を評価します。
手動ラベル付け:
実際のスプレッドシートやウェブテーブルを使用し、ベンチマークデータに手動でラベルを付けます。
テストデータ詳細:
表4では、テストデータの具体的な詳細や統計情報を提供しています。
5.2 品質比較
GPT-3.5とChatGPTの両モデルを対象として、それぞれのデータセットに対してテーブルチューニングを施した際の結果は、以下になります。
比較対象:
GPT-3.5とChatGPTを基盤としたモデルを選び、そのバニラモデル、すなわちテーブルチューニングを行っていないモデルと、テーブルチューニングを施したモデルの性能を比較する。
表示内容:
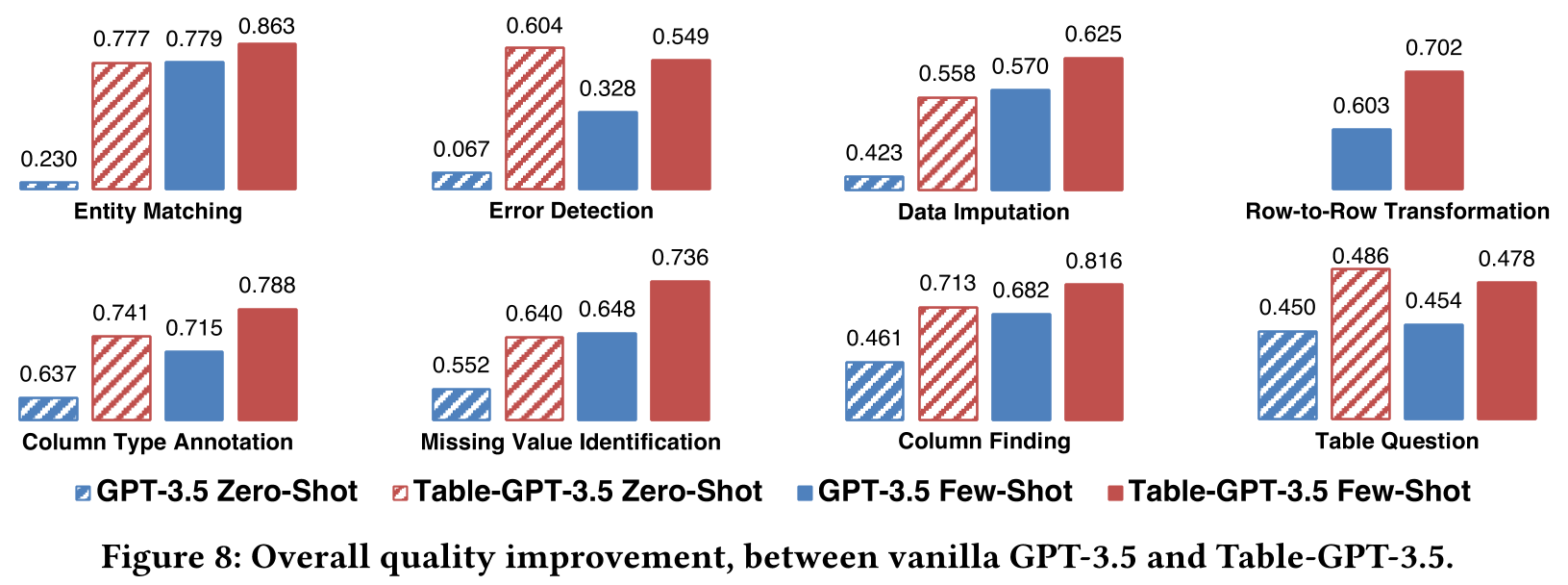
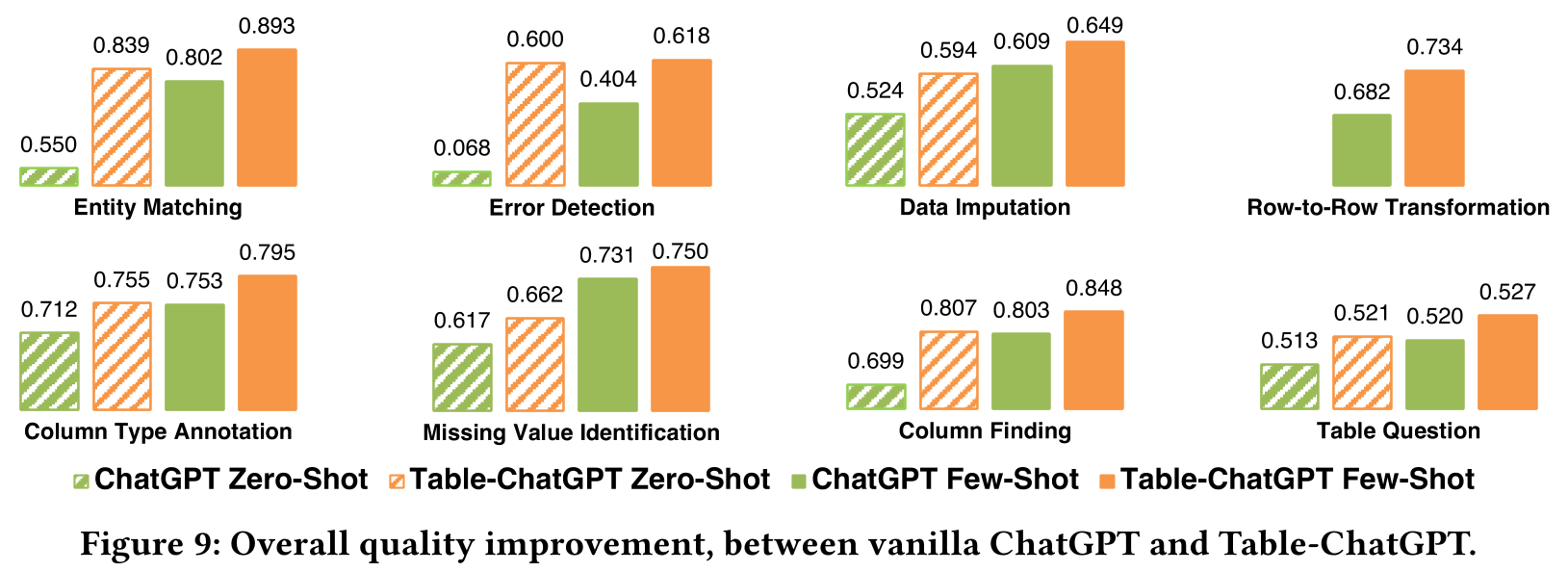
図8では、各タスクカテゴリに関して4つのバーが描画されており、前半の2つはゼロショットの設定を、後半の2つは数ショットの設定を示しています。
性能向上:
テーブルチューニングを施したモデルは、様々なテーブルタスクにおいて、顕著な性能の向上を見せています。
テーブルチューニングの利点:
GPT-3.5とChatGPTの2つのモデルを基に、テーブルチューニングの利点が明確に示されています。これは、異なる特性を持つ基本言語モデルに対して、テーブルチューニングの手法が一般的に適用可能であることを示唆しています。
詳細な結果については、各データセットごとに示されています。26のテストデータセットに対し、2つの基盤モデル(GPT-3.5とChatGPT)と、ゼロショット、数ショットの2つの設定を用いて、合計104回のテストが実施されました。テーブルチューニングを採用したモデルは、テーブルチューニングを行っていないモデルと比べて、104回のテストのうち98回でより高い性能を示しました(3回は同じ性能、3回は劣る結果でした)。これにより、テーブルチューニングの有効性が確かめられました。
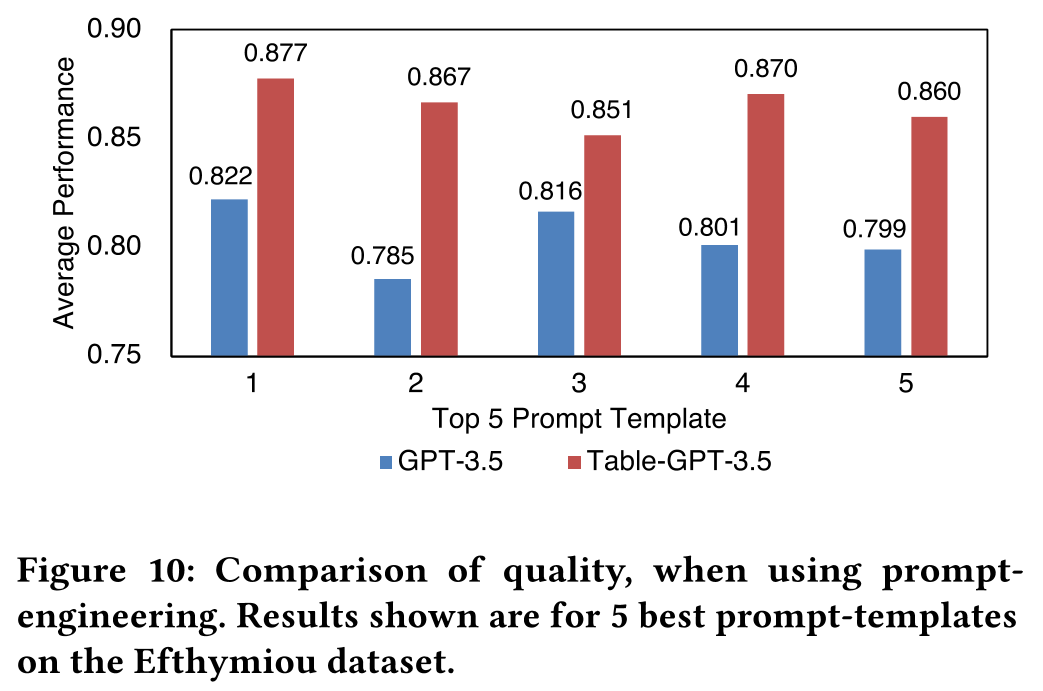
5.3 タスクに特化した最適化に対する利点
テーブルチューニングには、大きな可能性が秘められています。特に、ゼロショットやfewショットの設定で高い性能を発揮することができ、下流のタスクにおける品質を向上させるタスク特化型の最適化を施すことができる場合、テーブルチューニングされたGPTモデルは「テーブル基盤モデル」としての活用が期待されます。
プロンプトエンジニアリングの一環として、列型アノテーション(CTA)タスクにおいて、200個のラベル付き例から最適ないくつかの例を選び出し、プロンプトの有効性を検証いたしました。この結果、Table-GPT-3.5は、通常のGPT-3.5に比べて、一貫して高い性能を発揮しました。
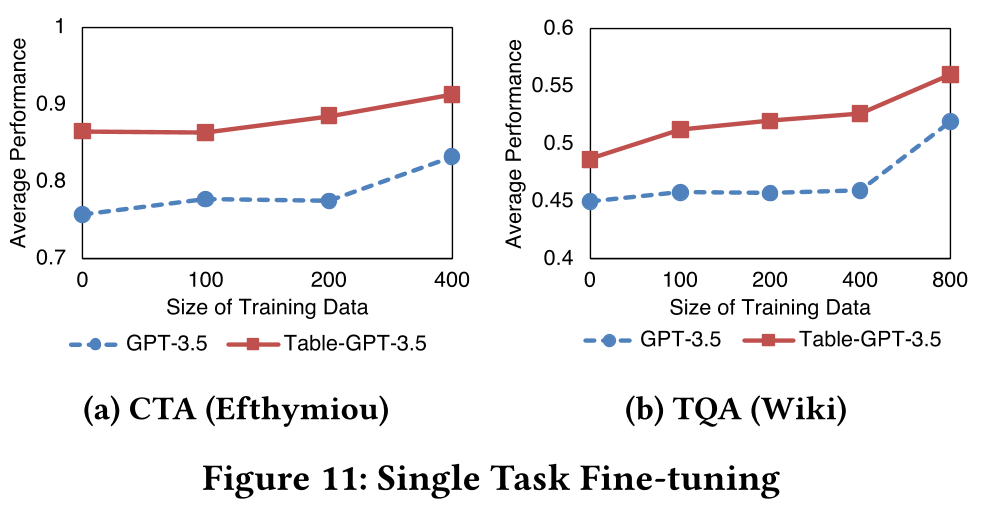
さらに、シングルタスクのファインチューニングの観点からも、Table-GPT-3.5とGPT-3.5を対象に、各タスクのラベル付きデータを利用して性能の比較を行いました。
具体的には、CTAタスクと表質問応答(TQA)タスクにおける性能を比較し、さらに学習データ量を変動させての評価を行いました。その結果、同じ学習データ量での評価において、Table-GPT-3.5はGPT-3.5よりも高い性能を持つことが明らかになりました。また、同じ性能を出すためには、Table-GPT-3.5をファインチューニングする際に必要となるラベル付きデータの量は、GPT-3.5をファインチューニングするよりも少なくて済むことが示されました。
5.4 Sensitivity Analysis
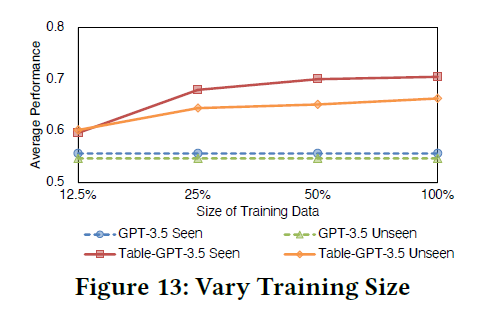
学習タスクの数を変えて、多くの学習タスクを使用することで得られる利点を確認しています。1/5/10タスクを全ての学習テーブルタスクから、それぞれ4回サンプリングしています。その後、選択したタスクのサブセットに対してファインチューニングを実施しました。ファインチューニングされた各実行の平均を計算し、その結果を詳しく分析しています。
図13に示されているのは、平均的な品質の結果です。タスク数が少ない場合(例えば、1タスクの場合)、テーブルチューニングはシングルタスクチューニングに縮退してしまい、実際には他のタスク全般のパフォーマンスが低下しています。しかし、タスク数が増えると、性能は全てのタスクおよび全タスクの平均で一貫して向上します。これは、マルチタスク学習の利点を示しています。
また、seen/unseen タスクにおけるベースモデルとテーブルチューニングモデルの平均的な性能についても示されています。未知のタスクにおいて、テーブルチューニングされたモデルは、小さなモデル(Ada/Babbage/Curie)では効果がほとんど見られませんが、大きなモデル(GPT-3.5やChatGPT)では、その効果が大きく増大しています。
5.5 アブレーション研究
異なるオーグメンテーション戦略の利点を比較した様子が以下です。
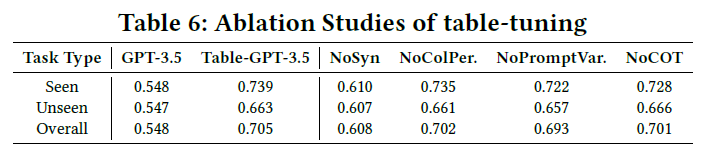
タスクレベルの拡張を行わない場合(合成タスクなし:NoSyn)
⇒SeenタスクとUnseenタスクの平均性能が顕著に低下しています。
テーブルレベルのオーグメンテーションを行わない場合(列の並べ替えなし:NoColPer)
⇒SeenタスクとUnseenタスクの平均性能が一定の低下を示しています。
命令レベルの増強を行わない場合(プロンプトの変動なし:NoPromptVar)
⇒SeenタスクとUnseenタスクの平均性能がわずかに低下しています。
完了レベルのオーグメンテーションを行わない場合(chain-of-thoughtを行わない:NoCOT)
⇒Seenタスクの平均性能のみが低下しています。
まとめ
本研究において、大規模言語モデル、例えばGPT-3.5やChatGPTを対象に、テーブルの理解やその上でのタスク実行の能力を向上させるための「テーブルチューニング」という新たなアプローチを提案いたしました。この手法は、モデルの重みを特定の方向でファインチューニングすることで、未知のタスクにも適応し、多岐にわたる人間の指示に応じる能力を強化します。
また、これまでの「命令チューニング」の成功を基に、テーブルチューニングも自然言語処理の研究領域で大きな成果を上げる可能性が秘められていると感じます。本研究は、テーブルやテーブル関連タスクの最適化に特化したモデルの開発の先駆けとして、非常に意義深い一歩となりました。
感想:
個人的には、テーブルデータという情報の凝縮された形態を理解・活用するモデルの重要性を改めて感じました。研究の進展が楽しみです。