はじめに
BERT(Bidirectional Encoder Representations from Transformers)は、2018年10月にGoogleが発表した自然言語処理(Natural Language Processing:NLP)のためのモデルです。BERT以降のほとんどのモデルがBERTのアイディアをベースに改善・開発されています。つまり、NLPを学ぶ上では避けては通れないといえます。
Google公式
論文 https://arxiv.org/abs/1810.04805
ブログ https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html
SEARCH https://blog.google/products/search/search-language-understanding-bert/
なお、BERTはTransformerを利用したモデルであり、Transformerの理解が前提になりますのでこちらの記事も参考としてご参照下さい。
Transformerについての解説記事
「自然言語処理の必須知識 Transformer を徹底解説!」
https://deepsquare.jp//2020/07/transformer/
概要
BERTとは
BERT(Bidirectional Encoder Representations from Transformers)とは、大規模教師なしデータを用いる双方向型のTransformerによる事前学習モデルのことです。(注意:事前学習モデルであり予測モデルではないため、BERT単体では何もできません。タスク用に新たなレイヤーを追加する必要があります。)BERTによって生成されるパラメータはより汎用性が高く、様々なタスクでSoATの結果を残しました。
なおGoogleがBERTを学習させて生成したパラメータは公開されているため、そのパラメータを自分のモデルに共有することで、だれでも計算コストをかけずにタスクごとに必要なアーキテクチャを最後に加えるだけで高性能な予測が可能となっています。
BERTの特徴
・プレーンテキストコーパスのみを使用した教師なし学習による事前学習モデル (pretrain-model)。
⇒教師なし学習の可能性を改めてひらきました。
・初めての深い双方向型教師なし言語モデル。
⇒文脈表現を把握する能力が飛躍的に向上しました。
・個別タスクのためにアーキテクチャを変更することなく最後に出力層を追加するだけで利用できる
⇒汎用性が高いモデルです。
・少量の教師ありデータによるfinetueningで様々なタスクに対応できる。
⇒タスクに対して必要なデータセットの少量化に成功しました。
・当時のNLPタスクのうち、11のタスクで最先端の結果を残した。
BERTの開発動機
BERTの開発動機は、いかに少ない教師ありデータでタスクに対しての精度を上げるかにあります。NLP分野において、実務必要性のあるタスクが多様に存在するのに対して、各タスクに対応している教師ありデータセットが少ないことがあります。(なお機械学習分野において基本的に教師ありデータセットの数と精度は正比例関係にあります。)そこでBERTの研究者はデータセットを増やすのではなく、データセットそのものが少なくても精度を向上できる多様なタスクに応用できる汎用性の高い基盤となる言語表現を生成する教師なし事前学習モデル(=BERT)を作ることを目指しました。
双方向型文脈モデルとは
BERTはよく、双方向型Transformerを用いて、文脈を理解できるモデルと表現されます。
事前学習によって作られる基盤となる言語モデル(特徴量やパラメータとして表現される)は、文脈自由モデル(単語同士の対応関係のみを利用)または文脈に応じた文脈モデルにすることができます。そのうえで、文脈モデルはさらに単方向または双方向という区別があります。
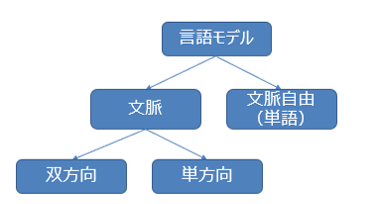
NLPの初期モデルであるword2vecやGloVeなどは文脈自由モデルであり、語彙の各単語に対して単一の単語埋め込み表現を生成するモデルです。文脈自由モデルの問題点は多義語や文脈に応じて意味の変わる単語に対応することができないという点があげられます。それに対して、BERTなどの文脈モデルは、文脈を加味した答えを返すことができます。
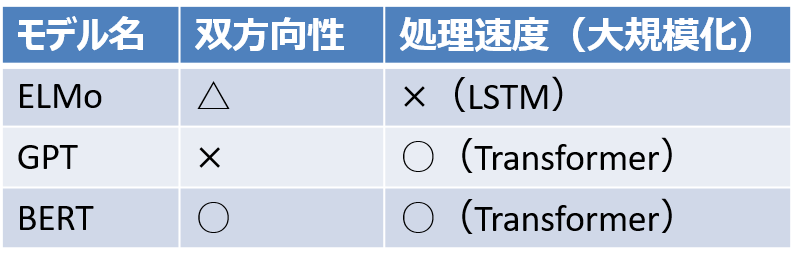
BERT以前のTransformerを利用したモデルであるGPT(GPTシリーズの一番最初のモデル)は文脈モデルのなかでも一方向型モデルに該当します。一方向型とは片方の文脈のみを利用するモデルのことをいいます。しかし、(直観的に理解されるとおもいますが)文章は前後半双方向から加味することで意味を特定できる単語、文が数多くあります。そのため、一方向型では精度が下がるという問題がありました。BERT以前のELMoなどは双方向型モデルですが、一方向の結果を結合しただけなので、「浅い双方向型」とBERRTの開発チームからは指摘されています。また、LSTMを利用したモデルであるため処理速度が遅く大規模化に向かないという問題もありました。BERTではTransformerを利用した双方向型にすることで、該当箇所の前後半すべての文章を踏まえることができ、そのことでNLPタスクの精度を向上させることを可能にしました。
BERTの革新性
BERTの革新性はTransformerを利用した双方向型の教師なし事前学習を可能にした点にあります。
Transformerを利用した双方向型の事前学習モデルを構築できない理由は単純に学習方法がなかったためです。文章などの順番がある時系列データは、予測すべきデータが学習データのなかに混ざっています。答えを学習データに与えてしまうと汎化性能が大きくさがってしまいますが、文章の次の単語を予測するなどの問題を双方向で行おうとするとどうしてもその問題にぶつかってしまいます。そのため、GPTは単方向型になっていました。
この問題を解決するために、BERTでは、入力内のいくつかの単語をマスキングし、各単語を双方向に条件付けして、マスキングされた単語を予測するという学習手法が導入されました。この方法によって、うまく双方向型の学習を行うことに成功しました。なお、この手法のアイディアそのものは以前から提案はされていましたが、この手法はかなりの計算コストを必要とするため、成功することができた大きな要因の一つとして、Googleが独自開発しているTPUの存在があると開発者グループは公言しています。
BERTの応用性
BERTは基本的に事前学習して言語表現モデル(パラメータ)を生成するためのモデルです。そのため機械翻訳、自動応答機など様々なタスクに幅広く応用することが可能です。特に開発元でもあるGoogleでは検索エンジンに応用されており、これまで困難とされてきた検索を可能にしていることが確認されています。
詳細解説
基本的に論文に沿う形で、BERTについて詳細解説をしていきます。
BERTの技術的革新性
・言語表現に対する双方向型表現言語モデルを事前学習する重要性を実証したこと。
⇒一方向性表現言語モデルを事前学習pretrainedに用いるモデルに対して、BERTはマスクされた言語タスクを用いて、深い双方向性表現言語モデルで事前学習したことで精度を飛躍的に向上させました。
・ 汎用性の高い事前学習された表現を用いることで、多くの複雑に設計されたタスク固有のアーキテクチャの必要性を減らすことを示したこと。
⇒BERT は、文レベルおよびトークンレベルの大規模なタスクにおいて最先端の性能を達成し、多くのタスク固有のアーキテクチャーを凌駕する、初の微調整finetuningに基づく表現モデルです。
教師なし学習について
教師なし学習には特徴量ベースのアプローチと微調整(finetuning)アプローチがあります。BERTは後者に属するモデルですが、それぞれのモデルについて概要を確認しておきましょう。なお、双方のアプローチには善し悪しがあり、どちらも万能とはいえませんが、BERT以前はどのアプローチを利用したとしても、単方向型言語モデルのみが利用されており、この点をBERTの研究チームは問題視していました。
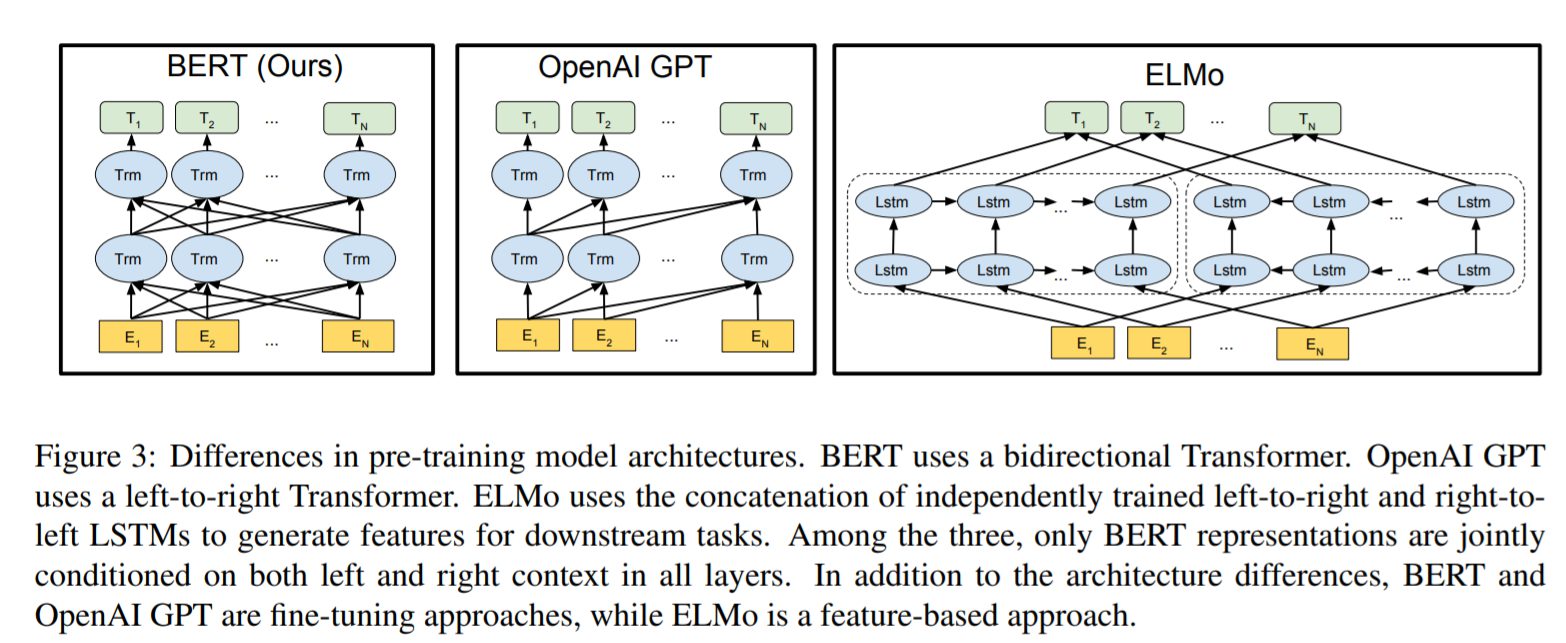
教師なし特徴量ベースのアプローチ
広範なタスクに適用可能な単語表現を特徴量として利用して学習することを目的としたアプローチです。どんなタスクにでも使える単語表現特徴量を獲得できれば、どんなタスクに対しても教師なし学習させるだけで対応できるのではないかという考えがもとになっています。ただし、アーキテクチャをタスクに応じて変える必要があります。BERTの前身モデルでもあるELMoなどはこの単語表現の特徴量をベースにしたモデルです。なお、ELMoなども一般に双方向の文脈を考慮したといわれることがありますが、BERTの研究チームから言わせれば、左方向と右方向の表現を連結しただけで深い双方向性はないと断じられています。
教師なし微調整アプローチ
基本となる単語表現を事前学習したパラメータを重みの初期値として利用するモデルです。最後にタスクごとに必要となるデータセットを個別に読み込ませる微調整することで対応するモデルとなります。最後に追加層を加えるだけでもよく、大きなモデル変更はありません。OpenAI GPTも微調整アプローチです。基本となる部分は転用が効くため、多くの場合学習時間を削減することもできます。
BERTの仕組み
BERTで独自に組まれている仕組みについて、説明します。
モデルアーキテクチャ
BERTの最終的な目標は言語モデルを生成することにあるので、Transformerにおけるエンコーダだけのつくりになっています。基本的にモデルアーキテクチャの部分に特別な工夫はしていないと研究チームは述べています。
※「Tensor2Tensor」(https://github.com/tensorflow/tensor2tensor)や「The Annotated Transformer」(http://nlp.seas.harvard.edu/2018/04/03/attention.html)のモデルとほぼ同じだそうです。
論文では二つの大小モデルが作成されました。
BERTBASE L=12, H=768, A=12 :Total Parameters=110M
BERTLARGE L=24, H=1024, A=16 :Total Parameters=340M
*層の数(トランスフォーマーブロック)をL、隠れサイズをH、自己注意ヘッドの数をAと表記しています。
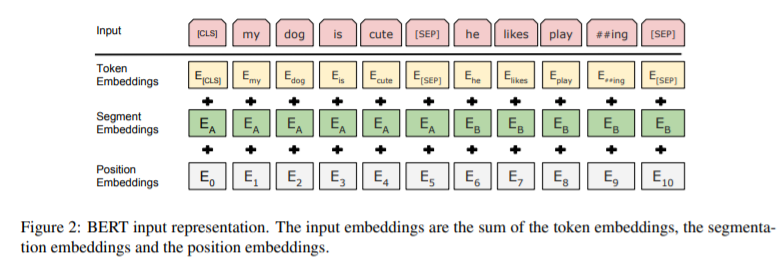
入力/出力表現について
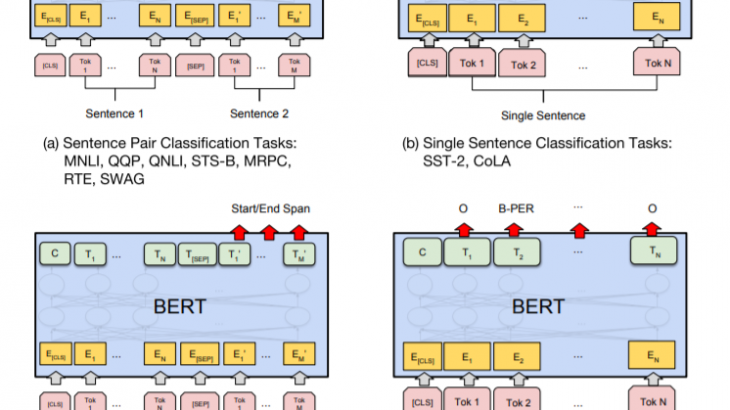
さまざまなダウンストリーム作業(個別タスクに対応すること)を処理できるようにするために、BERTでは入力表現が1 つのトークン列の中で単一文と文の組(例:h Question, Answeri)の両方を明確に表現することができるようにされています。この作業を行うことで、「sentence 文」とは実際の言語的文ではなく、任意の連続したテキストのスパンを意味するようになります。「sequence シーケンス」とは、BERT への入力トークンシーケンスを指し、これは単一の文である場合もあれば、2 つの文をまとめたものである場合もあります。
すべてのシーケンスの最初のトークンは常に特殊分類トークン([CLS])となります。このトークンに対応する最終的な状態表現が、分類タスクのための集約シーケンス表現として使用されることになります。文のペアは1つのシーケンスにまとめられ、文を2つの方法で区別しています。一つ目は特別なトークン([SEP])で文を分離する方法です。二つ目は、各トークンにそれが文Aに属するか文Bに属するかを示す学習済みの埋め込みを付加する方法です。

与えられたトークンについて、その入力表現は、対応するトークン、セグメント、および位置のエンベッディングを合計することで構築されることになります。この構造を可視化すると、以下のようになります。
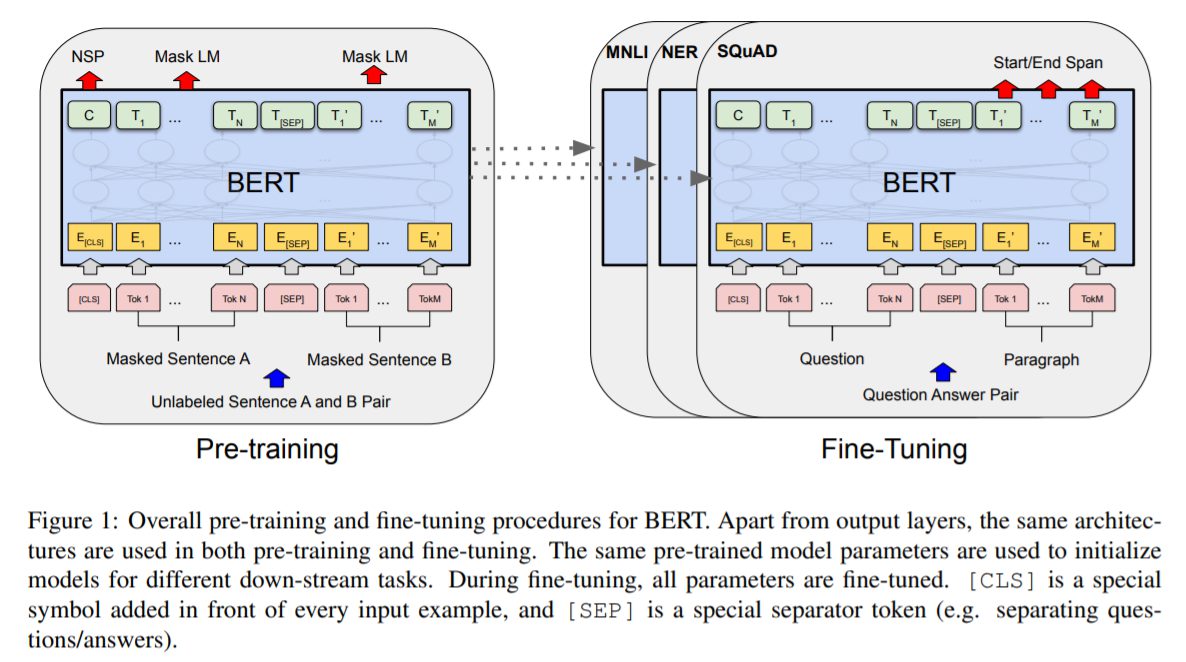
事前学習Pretrainingと微調整Finetuning
BERTモデルは、ラベル付けされていないデータ上で事前学習され言語表現モデル(パラメータ)を獲得します。その後、最初に事前学習されたパラメータで初期化され、すべてのパラメータは下流タスクからのラベル付きデータを使用して微調整されることになります。各下流タスクは、同じ事前学習されたパラメータで初期化されているにもかかわらず、個別に微調整されたモデルを持っていることになります。BERTのモデル特徴は、異なるタスク間で統一されたアーキテクチャにもあります。事前学習されたアーキテクチャと最終的な下流のアーキテクチャの間には、最小限の違いしかないと研究チームは論じています。
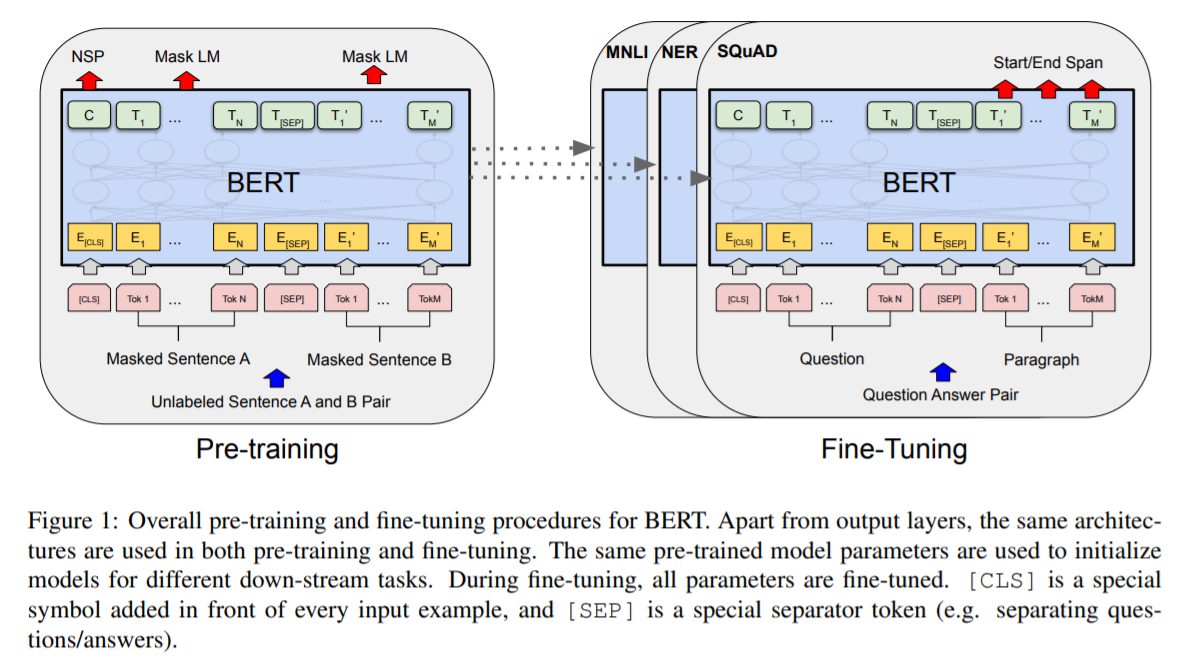
事前学習について(マスク言語モデル/次文予測)
BERTのような双方向モデルは、単方向型で行われる次の単語を予測するようなタスクでは学習できません。代わりに、BERT特有の二つの教師なしタスクが設定されています。
タスク⑴:マスク言語モデル(Masked Language Model:MLM)
従来の次の単語を予想するタスクによって言語モデルを得る学習方法を用いると、双方型では予測する単語の情報を得てしまっているため、学習がうまくいきません。そのため深い双方向性表現を訓練するためにBERTでは、入力トークンの何%かをランダムにマスクし、それらのマスクされたトークンを予測するという手法がとられています。(なおこの手法は、文献ではClozeタスクと呼ばれることが多かったそうですが、BERTの研究チームがこの手法を “masked LM” (MLM)と呼称するようになってからは現在ではマスク言語モデルという呼び方が一般化しています。)この場合、標準的な手法と同様に、マスクトークンに対応する最終的な隠されたベクトルは、語彙を対象とした出力ソフトマックスに供給されることになります。
なお、この方法で双方向の事前学習モデルを得ることができますが、欠点は、事前学習と微調整の間にミスマッチが生じることであると論文では述べられています。これを軽減するために、論文では「マスクされた」単語を常に実際の[MASK]トークンに置き換えないという手法がとられています。
まず学習データ生成器は、予測のためにトークン位置の15%をランダムに選択します。そして、i番目のトークンが選択された場合には、i番目のトークンを(1)80%の確率で[MASK]トークンに置き換える(2)10%の確率でランダムなトークンに置き換える(3)10%の確率で変更されていないi番目のトークンに置き換える、という選択肢から選ばれます。なぜこの手法がうまくいくかというと、もし予測対象となるトークンの100%が[MASK]トークンに置き換えられた場合には、もはやBERTモデルはマスクされていない単語のために有意味なトークンを生成する必要がなくなってしまうからです。(BERTモデルは予測対象となるマスクされたトークンにだけ最適化されてしまいます。)次に、予測対象となるトークンの一部が[MASK]トークンではなくランダムな単語に置き換えられるようにする場合、BERTモデルは予測対象となるはずだったトークンがオリジナルの単語とはまったく違った状態を学習することになります。最後に予測対象となるトークンの一部がもともとの単語のままであった場合、BERTモデルは予測対象となるトークンにオリジナルの文字列の文脈とはまったく関係のない埋め込み情報のみを学習することになります。
なお、各出力のうち Cは識別タスク(Ex.感情分析) に使われ、Tiはトークンレベルのタスク(Ex.Q&A) に使われます。
タスク⑵:次文予測(Next Sentence Prediction:NSP)
NLPタスクの多くが、文同士の関係性を理解することに基づいているということから、このタスクが設定されたようです。関係性を学習するために、どのような単言語コーパスからでも簡単に生成できる二値化された次文予測タスクのための事前学習を行うという手法が行われています。
具体的には、各事前学習例の文AとBを選択する際に、50%の確率でBはAに続く実際の次の文(IsNextと表示)であり、50%の確率でコーパスからのランダムな文(NotNextと表示)になるようにします。そして、次文なのか(IsNextか)、そうではないのか(NotNextか)を予測し、学習していきます。
この手法はそのシンプルさにもかかわらず、非常に有益であることが報告されています。
微調整について
トランスフォーマーのSelf-Attentionメカニズムにより、BERT は適切な入力と出力を入れ替えることで単一のテキストまたはテキストペアを含むかどうかに関わらず多くの下流の作業をモデル化することができるため微調整は簡単である、としています。なお微調整は一般的には、双方向の交差注意を適用する前に、テキストペアを独立してエンコードすることで行われます。しかし、BERTは、Self-Attentionを用いて連結されたテキストペアを符号化することが、2つの文間の双方向の交差注意を効果的に含むことから、代わりに自己注意メカニズムを用いて、これら2つの段階を統一しています。
各タスクについて、単にタスク固有の入力と出力を BERT にプラグインし、すべてのパラメータをエンドツーエンドで微調整するだけです。なお事前学習に比べて、微調整は比較的計算コストが安価です。論文で行われた結果は、まったく同じ事前学習モデルから出発して、1つのクラウドTPUで最大1時間、GPUで数時間で再現することができるとしています。
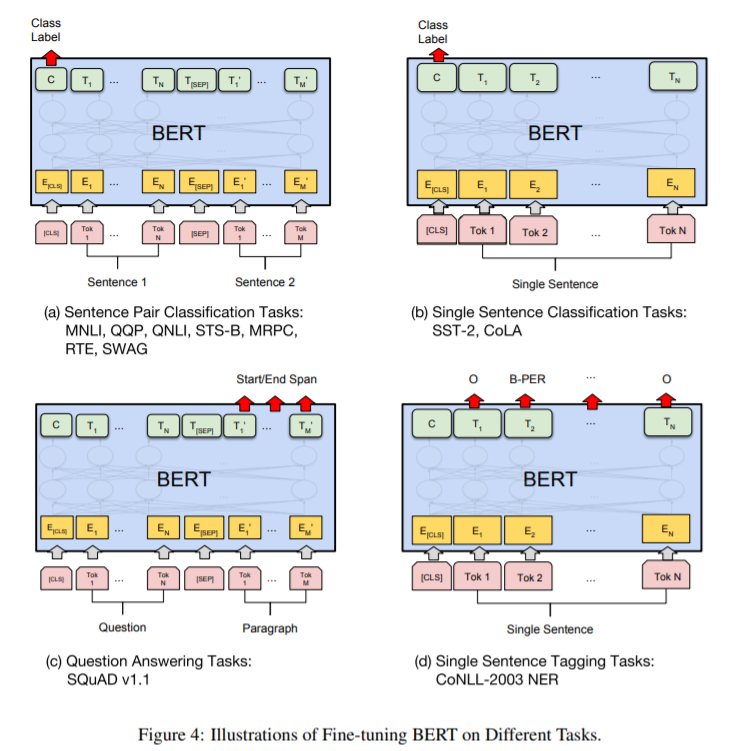
実験について
BERT論文で行われた各実験について解説します。
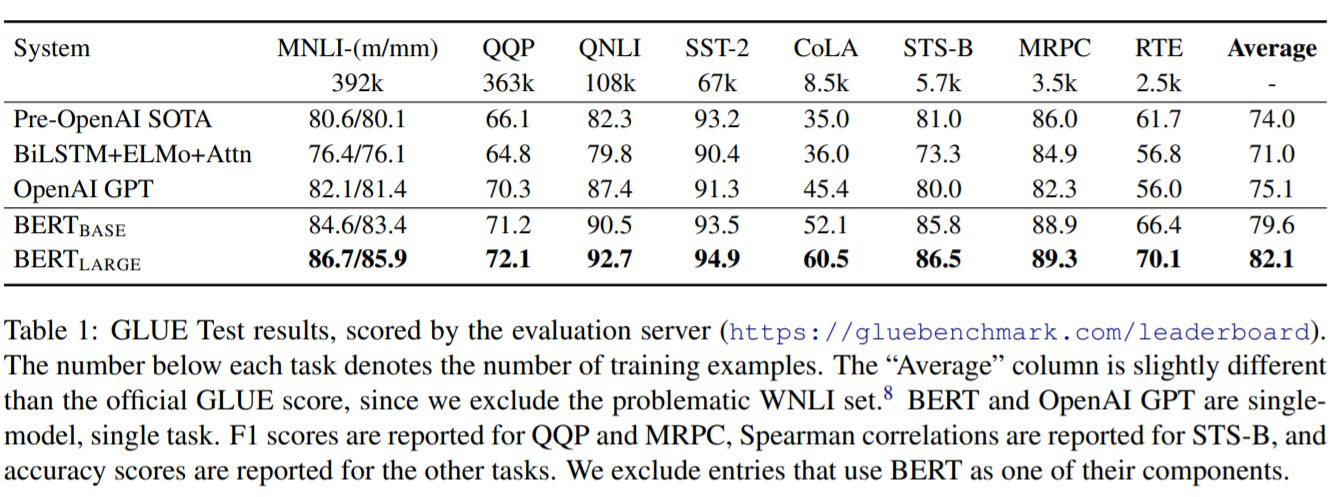
GLUE
BERTの評価はGLUEベンチマーク(General Language Understanding Evaluation)を用いて行われています。GLUEは8つのタスクから総合的に判断するものです。
MNLI 多分類タスク:前提文と仮説文が含意/矛盾/中立のいずれかに分類
QQP 二値分類タスク:2つの疑問文が意味的に同一かを分類
QNLI 二値分類タスク:文と質問のペアが渡され、文に答えが含まれるかどうかを分類
SST-2 二値分類タスク:映画レビューのポジ/ネガの感情分析
CoLA 多分類タスク:文が文法的に正しいか否かを分類
STS-B 多分類タスク:2文の類似度を1~5で分類
MRPC 二値分類タスク:ニュースに含まれる2文が意味的に同じかを分類
RTE 分類タスク:文書が含意しているか否かを分類
それまでのSoTAモデルよりもよい性能を出していることがわかります。
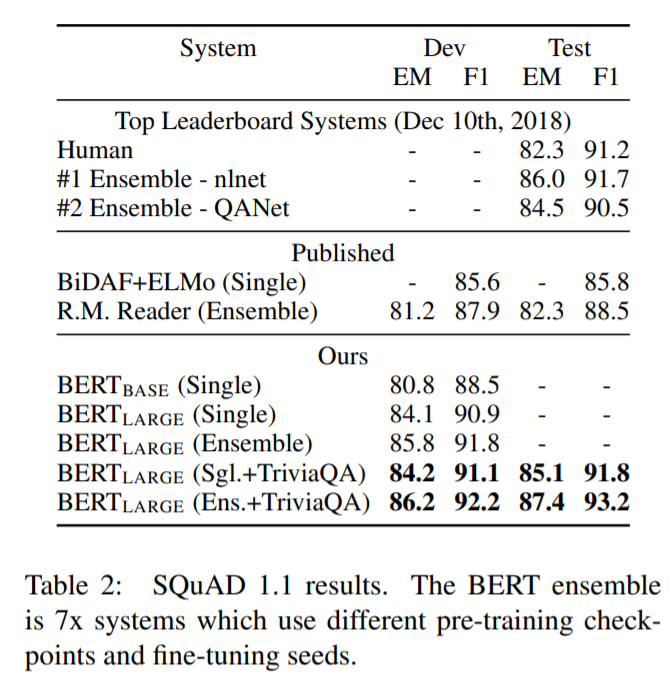
SQuAD(Stanford Question Answering Dataset)
スタンフォードが作った、質問文と答えを含む文章から答えがどこにあるかを予測するタスクです。
BERTモデルはここでも最もよい性能をだしていることがわかります。特にアンサンブルモデルよりもよい性能をだしていることは特筆に値します。
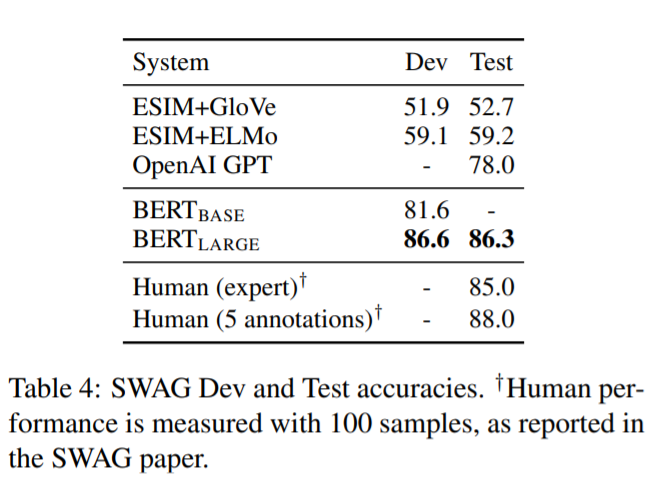
SWAG(Situations With Adversarial Generations)
与えられた文に続く文としてもっともらしいものを4つの選択肢から選ぶというタスクで、常識的な推論を行うタスクとされます。ここでも最もよい成果を出しています。
BERTモデルに関する効果の実験
BERTモデルの工夫について様々な実験がなされて、その効果が実証されています。事前学習、モデルサイズ、特徴量ベースアプローチをBERTに行った場合について解説されています。
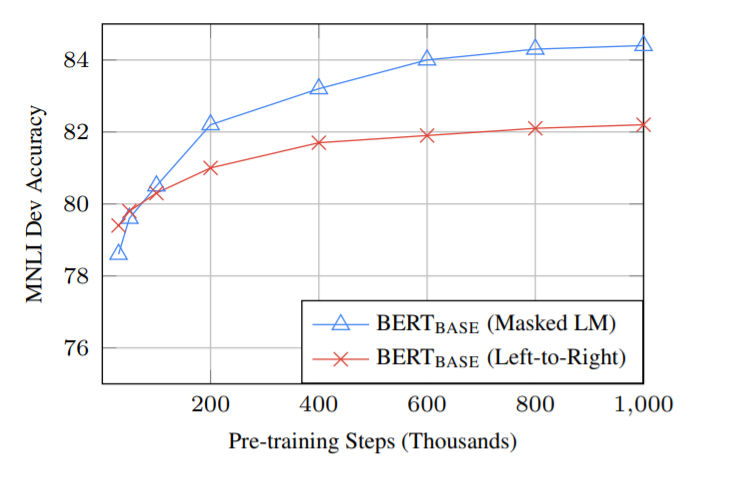
事前学習
まず、マスク言語モデルや次文予測タスクの効果があることがはっきりと示されています。効果が顕著なのが、MRPCとSQuADタスクです。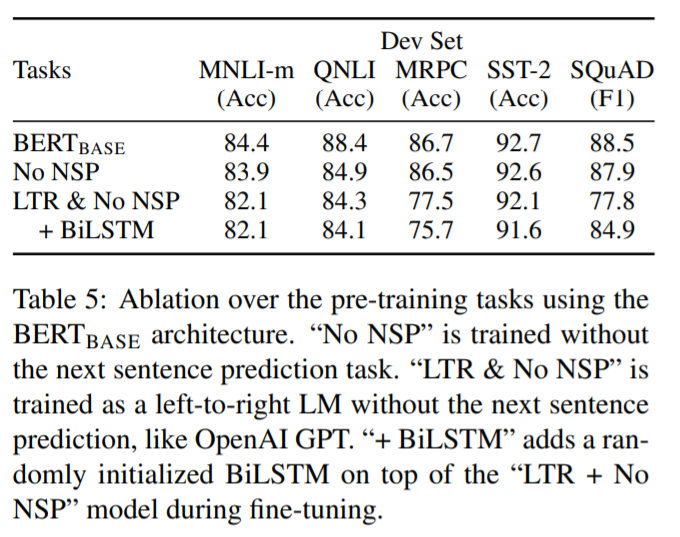
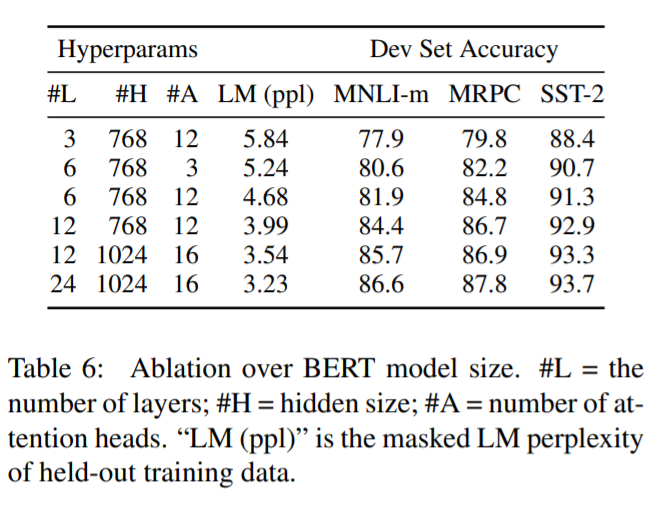
モデルサイズ
一般的に知られているように、BERTでもモデルサイズを大きくすることで、精度が向上しています。特に、研究者チームは、モデルが十分に事前に訓練されていれば、小さなデータセットしかないタスクでも大きな改善が得られることを実証した最初の研究であるとしています。
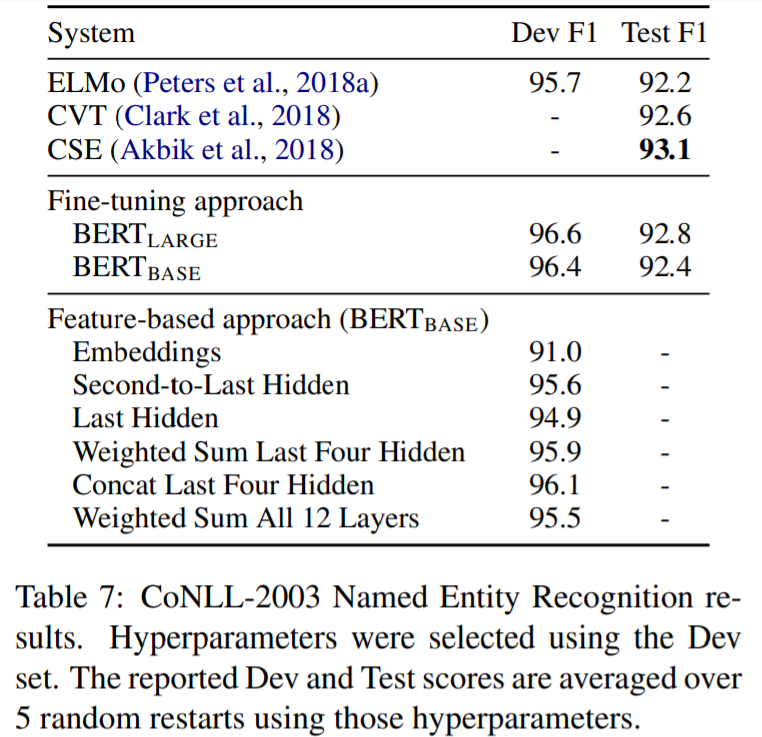
特徴ベースアプローチによるBERT
事前学習されたモデルから固定の特徴を抽出する特徴ベースのアプローチには、一定の利点があることが指摘され、この実験が行われています。利点の一つは、すべてのタスクがトランスフォーマーエンコーダアーキテクチャで簡単に表現できるわけではないため、タスク固有のモデルアーキテクチャを追加する必要があるということ。もうひとつは、訓練データの高価な表現を一度事前に計算し、この表現の上に安価なモデルを乗せて多くの実験を行うことには、計算上の大きな利点があるということです。
結果は、特徴ベースアプローチでもよい結果を残しており、調査チームはBERTはどちらでも有用なモデルであると結論付けています。
まとめ
BERTはTransformerを用いた双方向型の事前学習を可能にしたことで、高精度で文脈理解をした表現を獲得することに成功しました。BERTの誕生はNLPの方向性を大きく定め、その後に誕生したモデルの多くはBERTのアイディアを引き継いだものになっています。BERTは複雑なアーキテクチャなどはなく、タスクなどの工夫によってそれまで不可能であったことを可能にしたことで多くのひとに参考にされるものになりました。またTransformerの有用性を改めて確認させるものとなり、そのごTransformerを利用する流れをつくったともいえます。現在では画像認識でも利用されており、今後もどのような形でTransformerが使われているのか、注目しています。