
今回は、2017年にGoogleから発表されたMobileNet(V1)について、論文やGoogleブログを参考に解説する。
(なお、とくに断りがない限り、図の引用元は下記MobileNets論文からとなる。)
・論文:
「MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications」(2017/04/17)
https://arxiv.org/abs/1704.04861
・Googleブログ:
「MobileNets: Open-Source Models for Efficient On-Device Vision」(2017/06/14)
https://ai.googleblog.com/2017/06/mobilenets-open-source-models-for.html
MobileNet概要
・従来はより深く、より複雑化することで精度をあげようとすることがモデル開発の主流だった。それに対してMobileNetは、オンデバイスや組み込みアプリケーションの限られたリソースを意識しながら、効率的に精度を最大化することに重点をおいて設計された。
・MobileNetのアーキテクチャの特徴は、depthwise separable convolutions(depthwise convolutionsと pointwise convolutionsの組み合わせ)に基づいてる点にある。
・ハイパーパラメータとしてwidth multiplier と resolution multiplier を用いることで、モデルサイズとレイテンシー、精度のトレードオフを最適化するより小さく高速なモバイルネットを構築する方法を示している。
MobileNetがつくられた背景
CNNの性能が認められて以来、ニューラルネットワークのモデルは精度をあげるために、より深く、より複雑なものが主流となっている。しかし、これらのモデルは速度やネットワークのサイズという観点から効率のよいモデルであることを必ずしも意味するわけではない。ロボットの制御や自動運転、スマホなどでの高度なアプリケーションの実行などでは、計算力、電力、スペースなどリソースに制約のある環境で、高精度で高速に実行する必要がある。(とくにモバイルデバイスの計算能力の向上により、インターネット接続の有無に関係なく、いつでも、どこでも、高度な技術をユーザーの手に届けることができるようになる必要があると今回のMobileNetを考案したGoogleチームは考えた。)MobileNetは、オンデバイスや組み込みアプリケーションの限られたリソースを意識しながら、効率的に精度を最大化することを目的として設計された。
MobileNetのユースケース
MobileNetは小型、低レイテンシー、低消費電力のモデルで、様々なユースケースのリソース制約を満たすようにパラメータ化されている。分類、検出、埋め込み、セグメンテーションのために、Inceptionのような他の一般的な大規模モデルと同様に構築することができる。実際に利用する際は、レイテンシーとサイズの予算に合わせて適切なMobileNetモデルを選択する必要がある。下記図はモデル選択の際に参考となるものになる。(なお、Googleブログより引用した。)
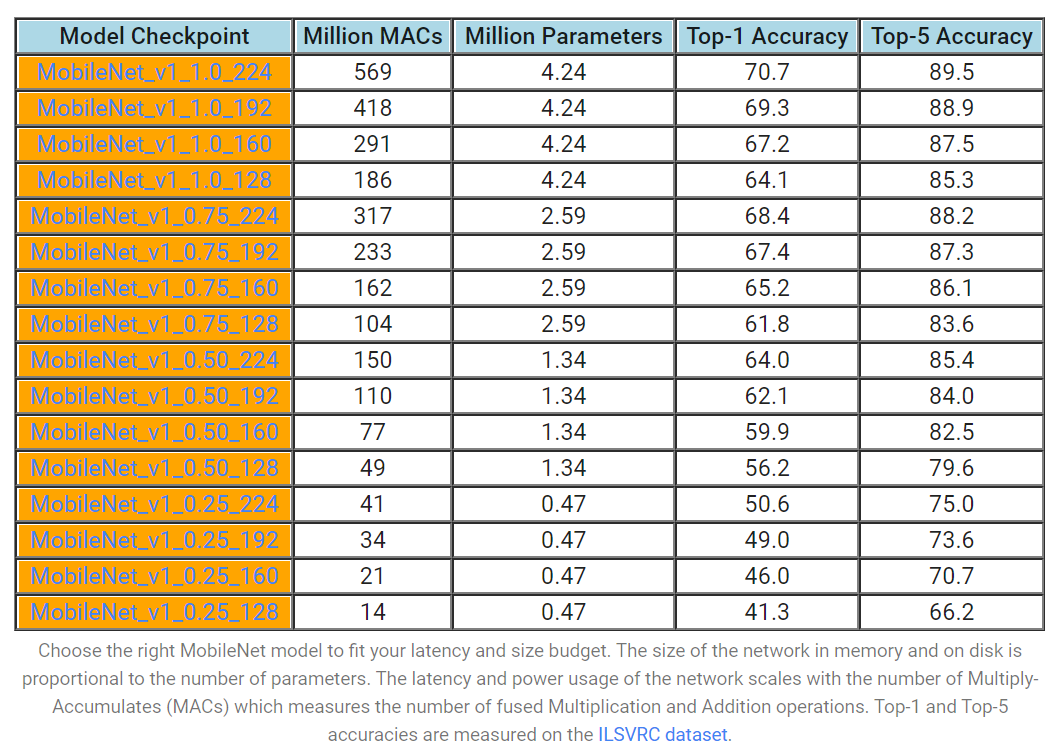
MobileNetのモデル構想
MobileNet以外にそれまでも効率的かつ小さなモデルをつくろうという試みがないわけではない。小規模活効率的なモデルをつくるときの一般的なアプローチは、①事前に訓練されたネットワークを圧縮するか、または②小さなネットワークを直接訓練するかのいずれかに分類される。MobileNetは基本的に後者の流れに属しながら、「モデル開発者がアプリケーションのためのリソース制限(レイテンシ、サイズ)に適合する小さなネットワークを特別に選択することを可能にするネットワークアーキテクチャのクラスを提案する」ことを目指している。
MobileNet詳細解説
MobileNetのアーキテクチャの概要について説明する。その後、①depthwise separable convolutionsと、ハイパーパラメータである②Width Multiplier(幅乗算機)と Resolution Multiplier(解像度乗算機)について解説する。
アーキテクチャ概要

MobileNetの構造は、第1層が完全畳み込みであることを除いては、depthwise separable convolutionsで構築されている。すべての層は、バッチノルムとReLU非線形性に続いているが、最終的に完全に接続された層は非線形性を持たず、分類のためにsoftmax層に供給される。ダウンサンプリングは、第1層と同様に、depth方向の畳み込みにおいてもストライド畳み込みで処理される。最終的な平均プーリングは、完全に接続された層の前に空間分解能を1に減少させる。depthwise convolutionsとpointwise convolutionsを別々のレイヤとしてカウントすると、MobileNetには28のレイヤがあることになる。
なお、 論文のMobileNetモデルは、Inception V3と同様のRMSpropを使用して、TensorFlowで学習された。しかし、大規模なモデルを訓練するのとは逆に、小さなモデルではオーバーフィッティングの問題が少ないため、正則化やデータ増強の技術をあまり使用していない。MobileNetsを学習する際には、サイドヘッドやラベルスムージングを使用せず、さらに、大規模なInceptionの学習で使用される小クロップのサイズを制限することで、歪みのイメージ量を減らしている。さらに、depth方向のフィルタはパラメータが非常に少ないため、重み減衰(l2正則化)をほとんど、あるいは全く行わないことが重要であることが明らかになった。
depthwise separable convolutions
〇概要
MobileNetは、標準的な畳み込みではなく、depthwise separable convolutions(depthwise convolutionとpointwise convolution(1×1の畳み込み)のふたつを組み合わせた畳み込みの総称)を利用している点に特徴がある。(なお、depthwise separable convolutions の発想自体は、GoogleチームのもではなくL. Sifreによる2014年に発表された博士論文「Rigid-motion scattering for image classification.」に基づいている。)
標準的な畳み込み処理は、畳み込みカーネルに基づいて特徴をフィルタリングし、新しい表現を生成するためにフィルタリングされた特徴を結合するという動作をワンステップとして行っている。MobileNetでは、フィルタリングと結合を、depthwise separable convolutionsを使用することで2 つのステップに分割することで、計算コストを大幅に削減する。
〇構造
標準的な畳み込みでは、両方のフィルタを適用し、入力を 1 つのステップで新しい出力セットに結合するが、MobileNetでは①depthwise convolutionで、各入力チャネルに 1 つのフィルタを適用し、次に②pointwise convolutionで1×1 畳み込みを適用して、depthwise convolutionの出力を結合する。
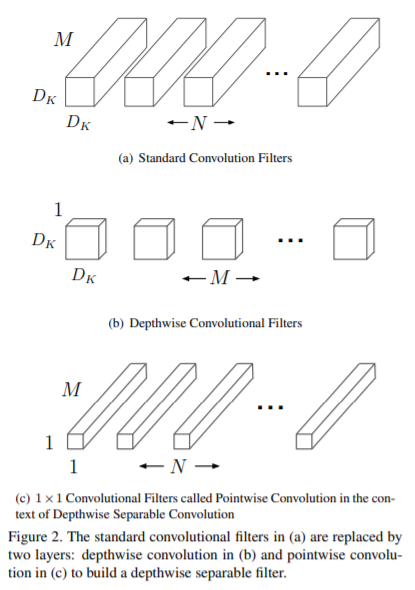
〇depthwise separable convolutionsの仕組み(計算量が減る仕組み)
標準的な畳み込み層は、DF × DF × M の特徴量マップ F を入力とし、DF × DF × N の特徴量マップ Gを作り出す。(なお、ここで、DF は正方形の入力特徴量マップの空間幅と高さ※1 、DK は正方形と仮定したカーネルの空間次元、 M は入力チャンネル数(入力の深さ)、DG は正方形の出力特徴量マップの空間幅と高さ、N は出力チャンネル数(出力の深さ)を意味する。※1.出力特徴量マップは入力と同じ空間寸法を持ち、両特徴量マップは正方形であると仮定する。モデル縮小の結果は、任意のサイズとアスペクト比の特徴量マップに一般化する。)
標準的な畳み込み層は、サイズ DK ×DK ×M×N の畳み込みカーネル K でパラメータ化されている。ストライド1とパディングを仮定した標準畳み込みの出力特徴量マップは、次のように計算される。
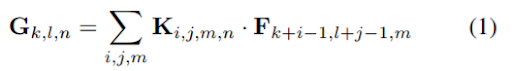
そのため、 標準的な畳み込みには次のような計算コストがかかる。
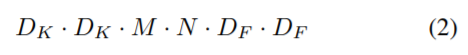
ここで、計算コストは、入力チャネル数 M、出力チャネル数 N、カーネルサイズ DK × DK、特徴マップサイズ DF × DF の大きさに乗算的に依存していることがわかる。MobileNet モデルは、これらの各項とその乗算的関係に対応することで計算コストを削減する。具体的には、depthwise convolutions convolutionsを用いることで、出力チャネル数とカーネルサイズが乗算されることを解消する。
depthwise separable convolutionsは、depthwise convolutionsとpointwise convolutionsの2つの層で構成されている。depthwise convolutionsを利用して、各入力チャネル(入力の深さ)ごとに単一のフィルタを適用する。次に、単純な1×1の畳み込みであるpointwise convolutionsを使用して、depthwise convolutions層の出力の線形組み合わせを作成する。(なお、MobileNetsでは、両方のレイヤにバッチノルムとReLU非線形性の両方を使用している。)
入力チャネル(入力の深さ)ごとに1つのフィルタを使用したdepthwise convolutionsは、次のように書くことができる。
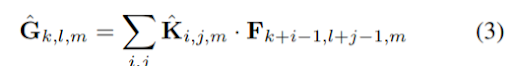
ここでKˆはサイズDK × DK × Mのdepthwise convolutionsカーネルで、Kˆのm番目のフィルタがFのm番目のチャンネルに適用され、フィルタリングされた出力特徴マップGˆのm番目のチャンネルが生成される。
depthwise convolutionsには以下の計算コストがかかる。
![]()
depth方向のみの畳み込みは、標準的な畳み込みに比べて非常に効率的である。しかし、これは入力チャンネルをフィルタリングするだけで、それらを組み合わせて新しい特徴を生成することはない。そのため、これらの新しい特徴を生成するためには、pointwise convolutionsを介してdepthwith convolutionsの出力の線形結合を計算することが必要となる。
depthwise separable convolutionsのコストは depthwise convolutionsと 1×1pointwise convolutionsを合計した以下になる。
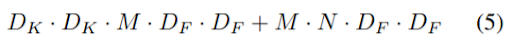
つまり、畳み込みをフィルタリングと結合の 2 段階のプロセスとして表現することで、以下の計算量を削減することができる。
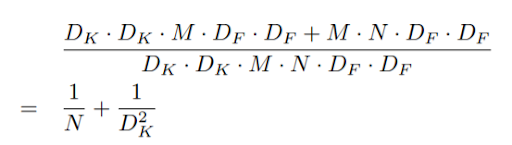
MobileNet は 3×3のdepthwise separable convolutionsを使用しており、標準的な畳み込みよりも 8 ~ 9 倍の計算量を削減しながら、精度をわずかに低下させるだけとなっている。(なお、空間次元での追加の分解は、depth方向の畳み込みに費やされる計算量が非常に少ないため、追加の計算量をあまり節約できない。)
Width Multiplier(幅乗算機)と Resolution Multiplier(解像度乗算機)
MobileNet のアーキテクチャはすでに小さくて低レイテンシであるが、特定のユースケースやアプリケーションでは、さらなるモデルの小型化や高速化が必要になることがある。そのときに、設定されているハイパーパラメータがWidth MultiplierとResolution Multiplierの2つとなる。
〇Width Multiplierについて
Width Multiplierと呼ばれる非常に単純なパラメータαを導入している。αの役割は、各レイヤでネットワークを一様に薄くすることにある。与えられたレイヤとαに対して、入力チャネルの数MはαMとなり、出力チャネルの数NはαNとなる。Width Multiplier₌αのdepthwise separable convolutinsの計算コストは次のようになる。
![]()
つまり、α=1のときは基本的なMobileNetを意味し、α<1はより削減されたMobileNetであることを意味する。Width Multiplierでは、計算コストとパラメータ数を約 α の二乗の二次関数的に削減する効果がある。Width Multiplierは任意のモデル構造に適用することができ、合理的な精度、遅延、サイズのトレードオフで、より小さなモデルを新たに定義することができる。なお、α₌1, 0.75, 0.5, 0.25が典型的な設定であり、下記図がその性能比較となる。
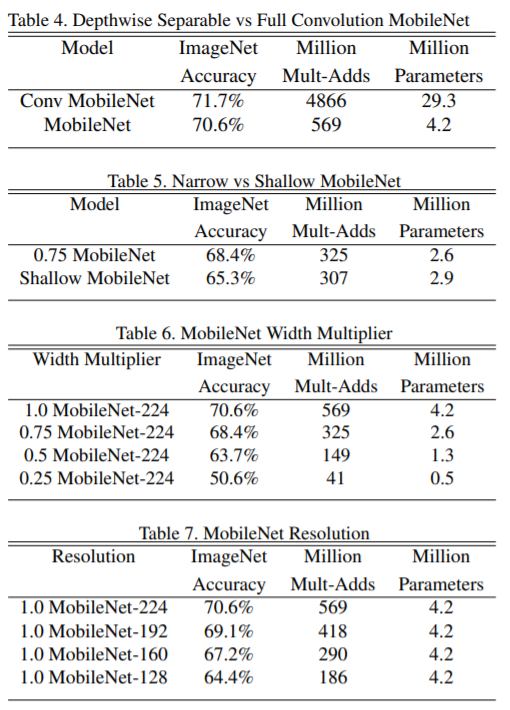
〇Resolution Multiplier
Resolution Multiplierは、ρで設定されている解像度に関するハイパーパラメータである。これを入力画像に適用すると、各層の内部表現が同じ乗数で削減されることになる。(なお実際には、入力解像度を設定することで暗黙裡にρが設定される。)なお、Resolution Multiplierは計算コストをρ の二乗分だけ削減する効果がある。
〇ハイパーパラメータまとめ
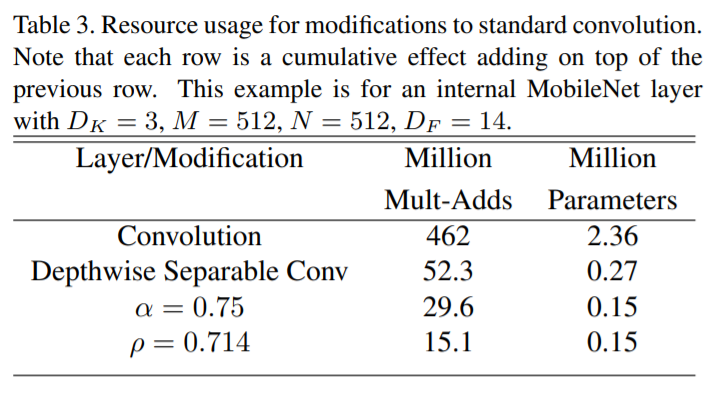
この二つのハイパーパラメータを考慮すると、ネットワークのコア層の計算コストを、Width Multiplier₌αとResolution Multiplier₌ρを持つdepthwise separable convolutionsとして表現することができる。その場合、以下のように計算コストが表現される。
![]()
下図はαやρを設定した場合の一例を示している。(なお、論文ではαやρを細かに変えた際の性能比較を掲載しているため、詳しくは論文を参照のこと。)
性能比較
最新の物体検出について、MobileNetはFaster-RCNNとSSDの両方のフレームワークの下で、VGGとInception V2と比較した結果が以下の図となる。(SSDは300の入力解像度(SSD 300)で評価され、Faster-RCNNは300と600の両方の入力解像度(FasterRCNN 300、Faster-RCNN 600)で比較されている。)両方のフレームワークについて、MobileNetは他のネットワークと同等の結果を、わずかな計算複雑度とモデルサイズで達成している。
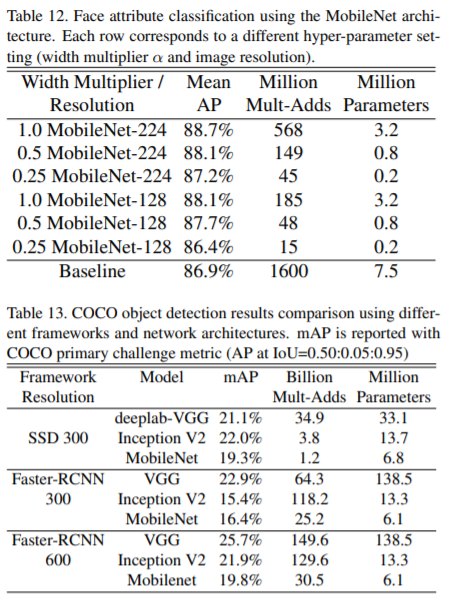
ほかにもMobileNetの論文では、「細かい認識」、「大規模ジオロケーション」、「顔の属性」などの分野で先端モデルと性能比較実験を行っている。MobileNetはそれらの各分野で先端モデルよりも計算コストやモデル規模が大きく小さくても、同等もしくは若干劣る精度を実現していることを明らかにしている。(なお、先端モデルとの性能比較の詳細は論文を参照のこと)
まとめ
MobileNetが提案したdepthwise separable convolutionsは計算コストの削減やモデル縮小のために多く利用されることとなった。リソースに制限があるなかで、どのようなことができるのかは現在でも重要なテーマであり、先駆け的な技術として一時代を築くこととなった。
MobileNetは執筆現在(2020年6月)、2018年にモデルv2、2019年にモデルv3が発表されている。v2やv3の方が基本的に性能は高まっており、v1を改めて実際の現場で利用しようということは少ないかもしれない。しかし、2017年に発表されたv1が基礎となり、v2、v3ができていること、またモデル効率化、縮小化の一潮流において重要なモデルであることを考慮すれば、v1について理解を深めておくは時間の無駄とはならないだろう。