はじめに
AIの世界では毎年最先端(SOAT:state-of-the-art technology)モデルが発表され、多くの新技術が生まれています。しかし、2017年に発表され「Atteintion is All you need」という論文で紹介された「Transformer」というモデルは、AIの歴史全体でみても大きな影響力をもつ極めて革新的な技術です(Transformerについてはこちらの記事をご参照ください。「自然言語処理の必須知識 Transformer を徹底解説!」)。Transformerはそれまでの自然言語処理の世界を一新し、その後発表されるモデルのデファクトスタンダートになりました。ただし、画像処理の世界では障壁(記事内で詳しく説明します)があり、ほとんど使われず、使われても限定的な使い方でした。
今回紹介する論文「AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE」のモデル「Vision Transformer」が、はじめて画像処理の世界で(CNNを利用せず)Transformerのみでモデルを構築したものになります。以下では、Vision Transformerの革新性や性能、開発背景などについて詳しく解説していきます。なお、こちらの論文はICLR2021に提出されたもので現在査読が行われているものです。今後、訂正や誤りなどが発表され論文の内容が変更される可能性もあります。その場合、すみやかに変更を反映しますが、変更される可能性があることを踏まえてご参照いただけますようお願いします。
なお、今回利用している図に関しては、特に断りがない限り全て下記論文より引用しております。
『AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE』
https://openreview.net/pdf?id=YicbFdNTTy
※なお、査読中の二重盲検法により発表者が明らかにされていませんが、データセットがGoogle独自の非公開のものであることやTPUの使用などからGoogleの研究チーム(特にBig Transferの開発チーム)ではないかと推測されています。
・自然言語処理の必須知識 Transformer を徹底解説!
(https://deepsquare.jp//2020/07/transformer/)
・代表的モデル「ResNet」、「DenseNet」を詳細解説!
(https://deepsquare.jp//2020/04/resnet-densenet/)
・Transformer を物体検出に採用!話題のDETRを詳細解説!
(https://deepsquare.jp//2020/07/detr/)
・自然言語処理の必須知識 BERT を徹底解説!
(https://deepsquare.jp//2020/09/bert/)
Vision Transformer概要
Vision Transformerとは–その革新性について–
今回発表された論文のモデル「Vision Transformer(ViT)」は画像処理で一般的なCNNなどを利用せずに純粋にTransformerのみを利用しているモデルです。そのことで、Transformerのもつ計算効率とスケーラビリティ(モデルを大きくすることへの許容性)の両方の恩恵を画像処理にもたらすことができたことが最大の革新といって良いとおもいます。
Vision Transformerは、画像を「画像パッチ(patch)が連なったシーケンスデータ」として扱うことで画像処理にTransformerを適用することに成功しました。この画像パッチは、自然言語におけるトークン(単語)と同じように扱われます。大量のデータで事前学習し、複数の画像認識ベンチマーク(ImageNet、CIFAR-100、VTABなど)に転移学習してテストしたとき、Vision Transformerは最先端のCNN型モデルよりも優れた結果(もしくは同程度)を出したうえで、学習に必要な計算コストを大幅に減らしました。ただし、データセットの規模が小さいとTransformerはCNNがもつ帰納的バイアス(位置等価性や局所性)を欠くため、汎化性能が低下してしまうという問題が明らかになっています。
また、Vision Transformerは、Transformerのみで作られたモデルであるため、今後自然言語処理分野で起きたような「自己教師あり学習の発展」や「単純にモデルを大きくすることで性能が向上していくこと」が期待されています。

(CNNなどを利用せず)Transformerのみを利用した初めての画像処理モデル
⇒Transformerの「計算効率の良さ」と「スケーラビリティ」を画像処理の世界にもたらすことに成功。
・大量のデータで事前学習した画像分類タスクにおいて最先端もしくは同等の精度を獲得。
・それにもかかわらず、必要な計算コストを大幅に低減することに成功。
JFT-300Mデータセットで事前訓練されたVision Transformer(ViT)を用いて、実験が行われました。最先端の精度もしくはほぼ同等の精度が確認されました。
スライド版はこちらからご参考下さい。
Vision Transformer詳細
Transformerが画像処理の世界に適用されなかった理由と取り入れたいモチベーション
自然言語処理の世界ではデファクトスタンダートともいえる「Transformer」ですが、ながらく画像処理の分野では利用されてきませんでした。その要因としては、まず①Transformerが得意とするのが文章などに代表されるシーケンスデータ(連続性のあるデータ)である、ということがあげられます。Transformerというモデルは、繋がりのある要素同士の関係性を明らかにすることに強みがあります。そのため、文章であれば単語同士の結びつきを明らかにすることで、基本的なタスク(例えば質疑応答のタスクや機械翻訳のタスクなど)で強力な武器になります。このことは直観的にも理解されるかと思います。対して、全体として繋がりがあるとは言いづらい画像のピクセル同士の関係性をとってくるということが、画像処理において重要とは考えられてきませんでした。それでも今年Facebook AI Research(FAIR)が発表したTransformerを利用した物体検出モデルDETRでは、有意性のある形でTransformerが画像処理の世界で利用されました。DETRではCNNと組み合わせる形でTransformerが利用され、画像内の物体同士の関係性を取ってくることで物体検出の精度を上げることに成功しました。DETRは物体検出の世界に新たな潮流を生み出したといえます。(詳しくは、DETRについての記事をご覧ください。「Transformer を物体検出に採用!話題のDETRを詳細解説!」)
しかし、それでも今回の論文が出るまでTransformerのみを利用して画像処理をするというモデルは存在しませんでした。それは素朴に②ピクセル単位でTransformerを利用すると計算要素が多くになってしまう、ということにあります。(単純化していますが)Transformerモデルを支えるAttentionという仕組みは、要素同士の関係性をとってくるため、要素の二乗分(n**2)の計算が必要となります。そのため、Attentionを画像のピクセル単位に対して適応しようとすると、たとえ画像の画素が256*256程度だったとしても4,294,967,296(=(256*256)**2)分の計算が必要ということになります。つまり、計算を煩雑にし、メモリも圧迫するのにもかかわらず、ピクセル同士の関係性を取ってくるメリットが見いだせなかったというのが、これまで画像処理にTransformerが利用する研究が進まなかった主な理由です。
一方で、Transformerを画像処理にも利用したいモチベーションも当然ありました。それは「計算効率のよさ」と「スケーラビリティ(モデルを大きくすることへの許容性)」です。基本的にTransformerは計算効率のよいモデルです。そして、何よりそのスケーラビリティに対しての評価が高いモデルです。ディープラーニングの世界ではモデルを大きくしたとしても学習が進まなくなる時があり、モデルの大きさには上限のようなものがあります。(そのため、既存モデルを大きくするための研究も多くの研究者によって試みられています。)それに対して、Transformerは単純にモデルを大きくしても学習ができる=性能の向上が見込めるという大きな利点があります。また、Transformerはデータ内の分散表現を獲得することでもあるため、自己教師あり学習に利用できるという利点もあります。そのため、ラベルのないデータセットでも有効利用できるため、モデルを大きくすることをさらに容易にしました。自然言語処理の世界では「人間を超えた」として大きな話題になったパラメータ数や利用したデータセットが巨大なGPT-3などを可能にしているのがTransformerです。Transformerでは理論上モデルを大きくすることで性能の向上が見込めるということが保証されており、GoogleやFacebook、OpenAIなど巨大企業が性能向上を目指す際にひとまずモデルを大きくする方向にある一因です。
モデル詳細
モデル構造は2017年に発表された基本的なTransformerと同じです。画像処理特有のCNNなどを挟まないことで、Vision Transformerは、Transformerの利点である「計算効率の良さ」と「スケーラビリティ」を獲得することができました。
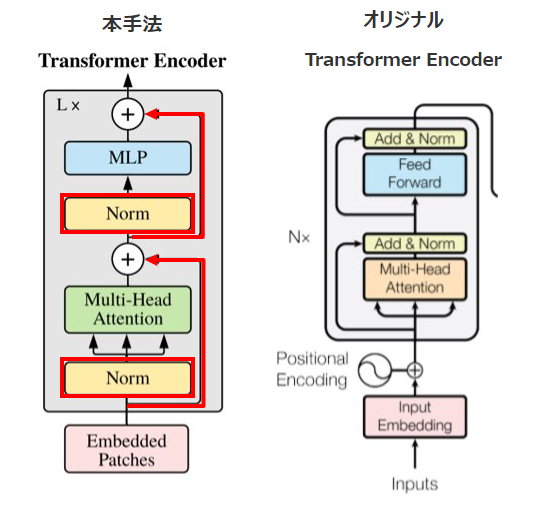
【Vision Transformerのアーキテクチャ図】
ちなみにこちらがTransformer(左図)とVision TransformerのTransformer部分(右図:論文「All you need is Attention」より引用しています。)のアーキテクチャ比較です。Vision TransformerはDecoder部分(Transformerのアーキテクチャの右側)が不要なのでほぼ同じことがわかります。
【アーキテクチャ比較図】
![]()
モデル構造
【モデル構造】
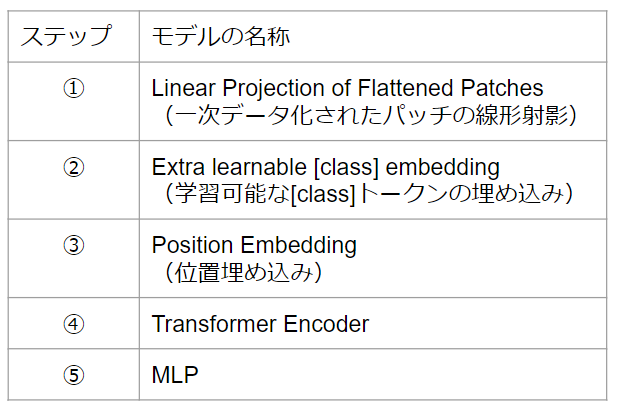
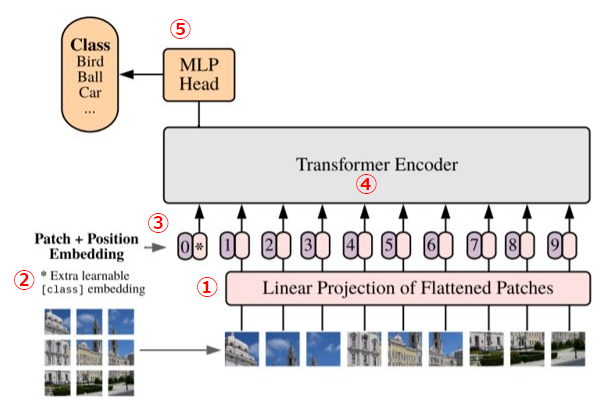
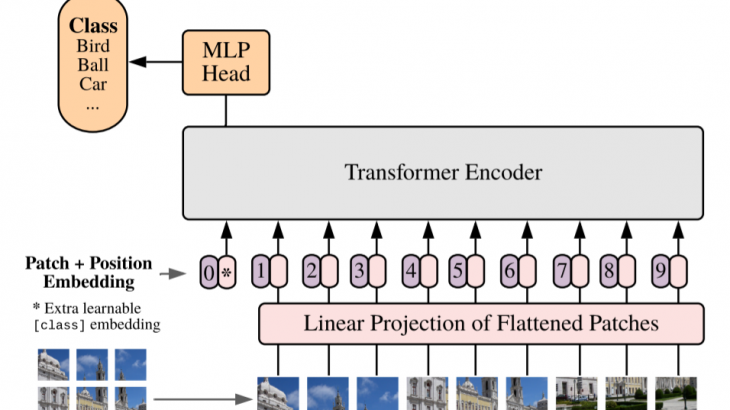
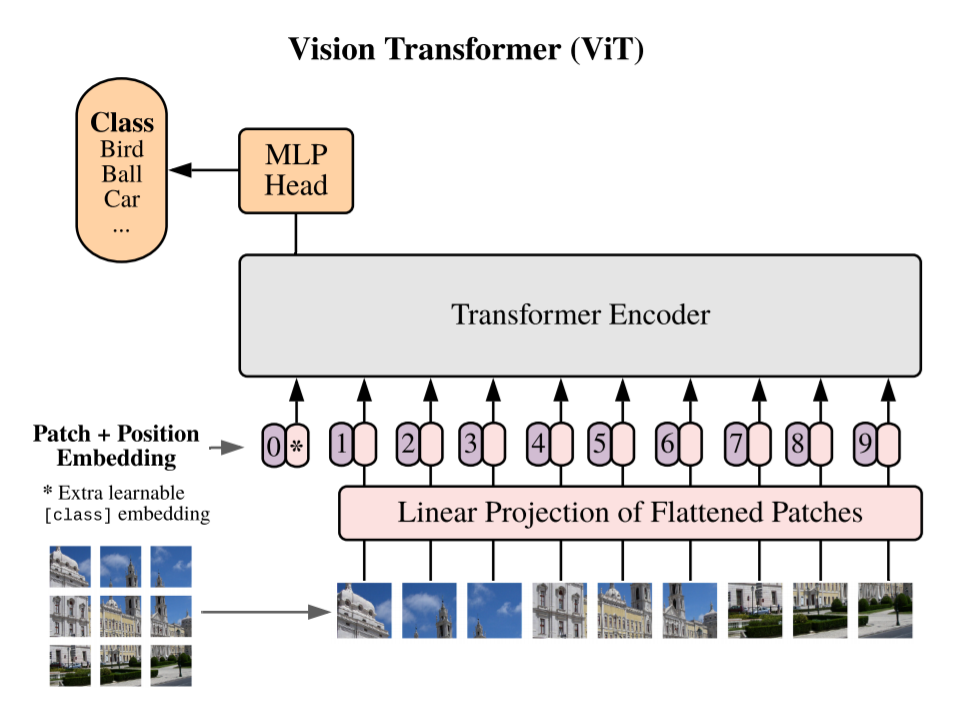
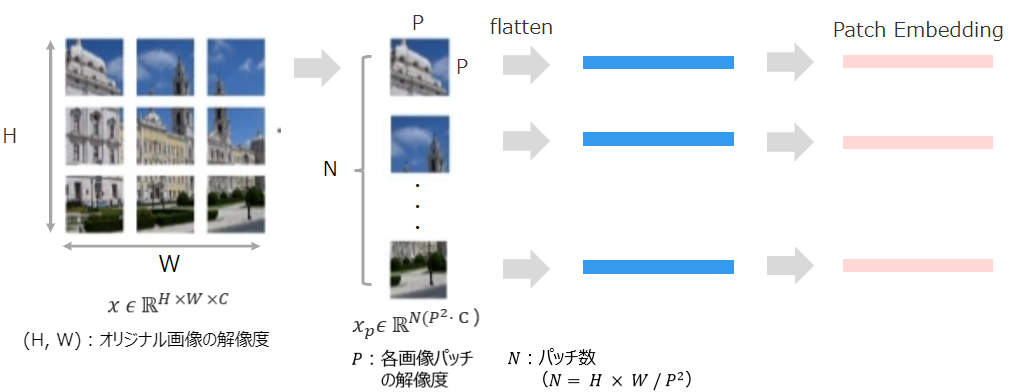
①Linear Projection of Flattened Patches(一次データ化されたパッチの線形射影)
TransformerはInputをシークエンスデータとして受け取る必要があります。そのため二次元である画像データをパッチごとに一次元のシークエンスデータに変換したうえで、線形射影します。具体的にはまず二次元の画像(H×W×C)をN個の一次元(ベクトル)の(P*P・C)に変換します。((H, W)はオリジナル画像の解像度、(P, P)は画像パッチのサイズ、N(=H*W/P*P)はパッチの数を意味します。)その後、一次元化(ベクトル化)されたパッチを次元DのテンソルEにフィルターを通して線形射影します。なお、線形射影に用いられるフィルターは学習されていきます。線形射影して得られた出力をPatch Embeddingと呼びます。この線形射影が行われるのは、Transformerではすべての層を通して一定の次元(次元D)であるデータが使用されるためです。
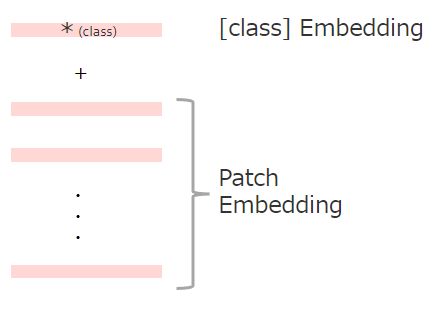
②Extra learnable [class] embedding(学習可能な[class]トークンの埋め込み)
画像分類を可能にするために、シークエンスデータの先頭に学習可能な[class]トークンを追加します。
※これはBERTのClassトークンと同じ仕組みです。
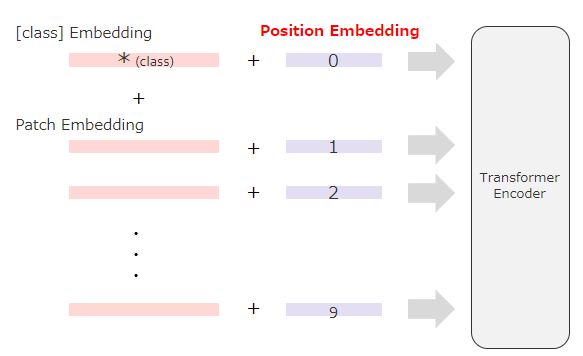
③Position Embedding(位置埋め込み)
パッチが画像のどこにあるかを識別する位置情報を付与します。
※Position Embeddingについては、詳しくは後述します。
④Transformer Encoder
TransformerはMultihead Self-AttentionブロックとMulti Layer Pecerptronが交互になる形で構成されています。これらのブロックの前にはLayer Normalizationが、ブロックの後には残差接続が適用されています。(残差接続に関しては、「代表的モデル「ResNet」、「DenseNet」を詳細解説!」をご参考ください。)Self-Attentionを通して自然言語処理の時と同様にパッチごとの(q, k, v)= (query, key, value)を獲得して、パッチごとの対応関係を取得していきます。
※Multihead Self-Attentionや(q, k, v)構造などについて、詳しく知りたい方はTransformerの解説記事で説明しておりますので、ご確認ください。
⑤MLP
分類ヘッドと接続して画像分類タスクに応用します。活性関数には非線形のGELUを用いています。
モデルの数式図
モデルを数式で表すと、以下のようになります。上記のモデル構造で説明した①~③までが(1)、④(Transformer部分)が(2)-(3)に相当します。なお、(4)で示されているyはモデルを通して作られた「画像表現」を意味しています。実際に画像分類する際は、yではなくZ0LにMLPヘッドを実装して分類すると論文では述べられています。
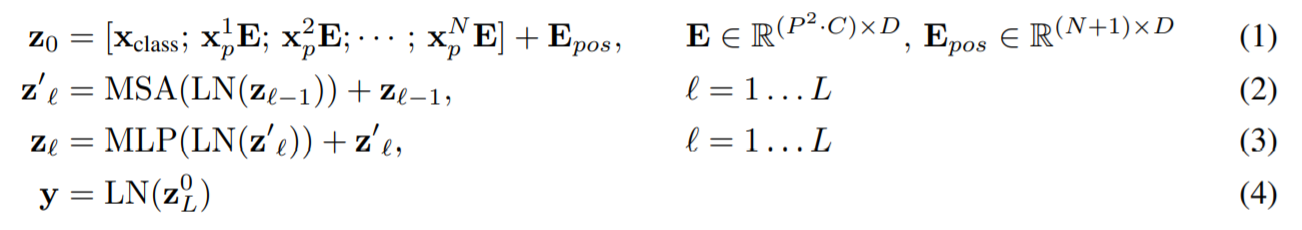
※Xclass = Class Embedding、Epos = Position Embedding、MS=Multihead Self-attention、MLP = Multi Layer Perceptron、LN=Layer Normalization
画像のPosition Embeddingに対する工夫
Vision Transformerでも自然言語処理のTransformer同様にPosition Embeddingが利用されています。ただし、自然言語処理においては文章などは位置関係が基本的に直線的でしたが、画像は2次元の位置関係なため、多様な方法が想定されます。本論文でもPosition Embeddingを用いて空間情報を符号化する方法について、有効な手法を模索するなかで以下の方法が試されています。
1次元位置情報の埋め込み
⇒各パッチがラスタ順の列で並んでいると考えます。
●試行手法
(1)位置情報を提供しない
⇒Positionon Embeddingをしません。
(2)2次元位置情報の埋め込み
⇒入力を2次元のパッチのグリッドとして考えます。この場合、2つの埋め込みセット(X-埋め込み、Y-埋め込み:サイズはD/2)が学習されることになります。そして、入力のパス上の座標に基づいて、XとYの埋め込みを連結して、そのパッチの最終的な位置埋め込みを取得する形になります。
(3)相対的な位置情報の埋め込み
⇒空間情報を絶対位置ではなくパッチ間の相対的な距離として考えます。この場合、パッチのすべての可能なペアの相対的な距離を定義する1次元のRelative Attentionを使用します。
また空間情報を符号化する方法を変更する以外に、1次元と2次元の位置情報の埋め込みについて情報を組み込む方法を変えることも論文では試されています。
モデルに投入したデータがパッチにされた直後(=Transformer Encoderに入力を供給する前)に、入力データに位置情報を追加する
●試行手法
(1)各層の最初に位置情報の埋め込みを学習して入力に追加する
(2)各層の最初に学習した位置情報の埋め込みを追加する(層間で共有する)
下図はViT-B/16モデル(ひとつのパッチサイズを16*16にしたVision Transformerのベースモデル)で有意な手法を調べた結果をまとめたものです。位置情報の埋め込みがないモデルと位置情報の埋め込みがあるモデルの性能には大きな差がありますが、位置情報のエンコーディング方法の違いによる差はほとんどないことがわかります。論文では「Transformer Encoderは、ピクセルレベルではなくパッチレベルの入力で動作するため、空間情報をエンコードする方法の違いはそれほど重要ではないと推測される」としています。
【Position Embedding法の比較図】
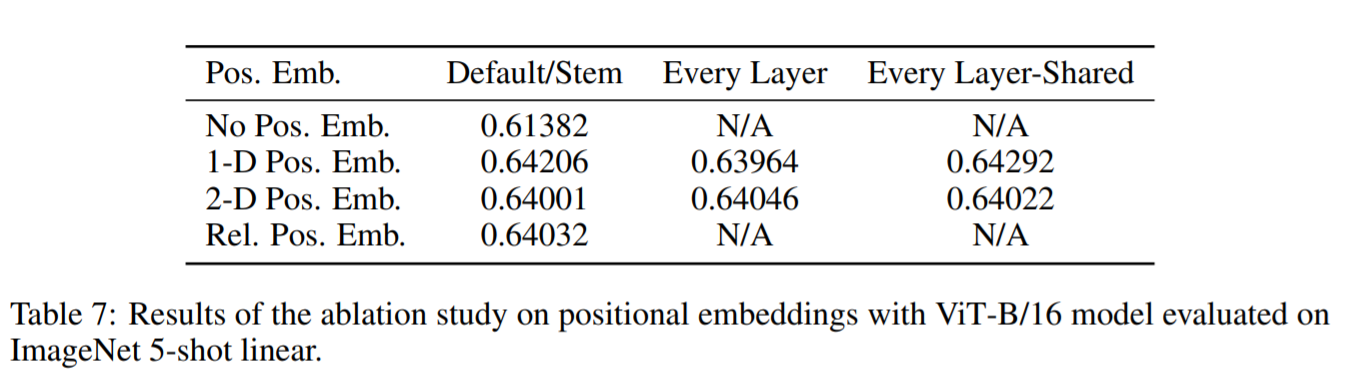
また、パッチレベルの入力では、空間の大きさ自体が元のピクセルレベルの入力よりもはるかに小さく学習が簡単ということも差に影響しないと考えられています。例えば、画像が224×224の解像度だったとしても、パッチレベルでは14×14です。そのため、比較的簡単に学習できるため、方法に有意な差が生まれづらいのではないか、と考察されています。
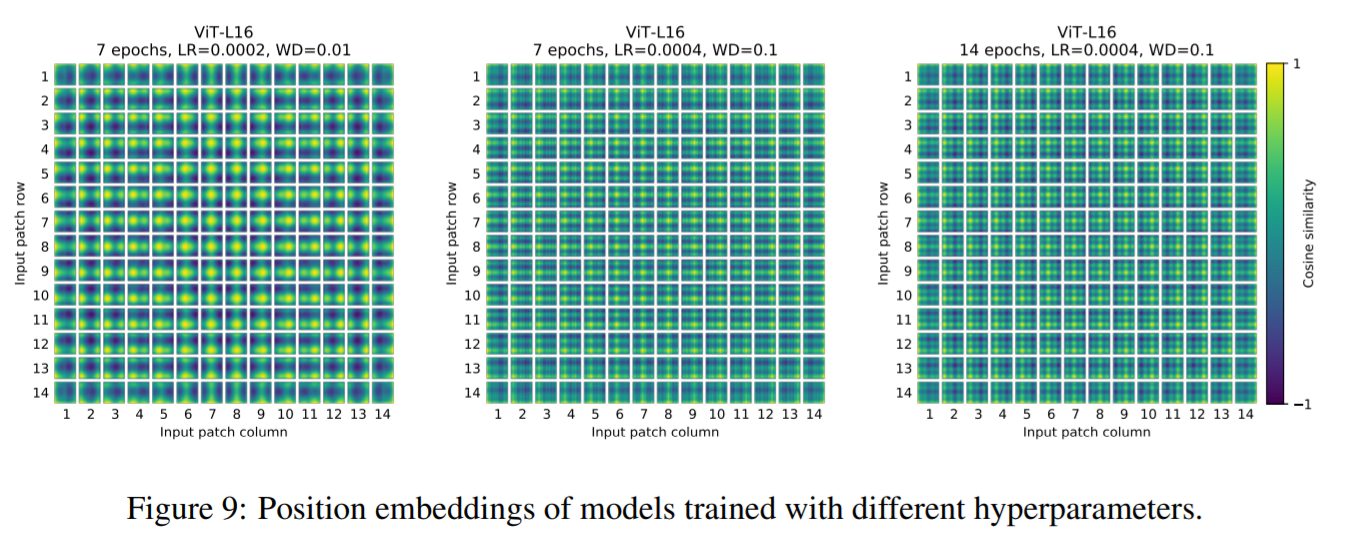
ただし、ネットワークによって学習されるPosition Embedingが付与した値のコサイン類似度が示す特定のパターンは、学習時のハイパーパラメータに依存しています。コサイン類似度が高いほど、パッチ同士が近い距離にあるとみていることを意味します。下図はパッチごとのコサイン類似度を示したものを並べたものです。なお、このPosition Embedingのコサイン類似度については後ほど解説します。ここではハイパーパラメータを変化させることで、コサイン類似度の様子が変化していることをご確認ください。左図は黄色部分が多く、周辺のパッチと近い距離感にあることを示しています。対して、右図は薄暗い部分が多く、周囲のパッチと距離感があることを示しています。
【ハイパーパラメータの変化とコサイン類似度の関係性】
※Hybrid Architectureについて
本論文では、入力を画像のパッチにするのではなく、ResNetで得た特徴量を入力とするHybrid Architectureが考案されています。なお、Hybrid Architectureはデータセットの規模が小さい時にはわずかにViTを上回りますが、大きなものではViTの方がよくなっています。これはCNNが画像の情報を「捨象」して要約していくものであることが影響していると考えられます。つまり、データセットが小さい間は捨象が有効に働いていますが、データセットが大きくなると捨象が情報を統合するときに必要な情報まで捨ててしまっているということです。これはCNNなどの持つ帰納的バイアスが画像処理において、どの程度有効かという問題につながっていきます。
※Fine-tuningと高解像度化について
Vision Transformerは大規模なデータセットで事前学習し、(より小さな)下流のタスクに合わせてFine-tuningして利用します。そのためタスクに適応するときに、事前学習した予測ヘッドを削除し、ゼロ初期化されたD×K(Kは下流タスクのクラス数)のフィードフォワード層を追加します。
また画像処理の世界では、一般的に事前学習した際の画像よりも高い解像度でFine-tuningすることが有益であると知られています。そのためVision Transformerでもより高い解像度の画像を与える場合が想定されます。Vision Transformerに事前学習時よりも高い解像度の画像を与えると、パッチサイズを同じに保つため、結果として学習されたときよりも長いシーケンスデータが得られます。これは画像のピクセル数が増えたのに対し、パッチサイズが変わらないため、画像をパッチに分割したときに生じるパッチ数が増えるためです。Vision Transformerは、任意のシーケンス長のデータを(メモリ制約まで)扱うことができるため、与えるシーケンスデータが長くなることは問題ありませんが、事前に訓練されたPositon Embeddingに意味がなくなる可能性があります。そのため、高解像度の画像でFine-tuningする際には、元の画像内の位置に応じて、事前に訓練されたPosition Embeddingの2D補間を実行しています。この箇所が画像構造に関してCNNが持つような帰納的バイアスがVision Transformerにおいても、もたらされてしまう唯一のポイントとなります。つまり、事前学習した画像よりも高解像度の画像を利用した場合、Vision TransformerもCNNと同じように情報を捨象してしまっていることを意味します。
Vision Transformerはどのように画像を理解しているのか
Vision Transformerが画像データをどのように処理するかを理解するために、その内部表現を論文では分析しています。
Linear Projection of Flattened Patchesについて
Vision Transformerははじめに、画像から1次元データ化されたパッチを低次元空間Dに学習するフィルターを通して線形射影します。下図は、学習したフィルターの上位の主成分を示しています。これらの示された主成分は、各パッチ内の微細な構造を低次元で表現するための基底関数に似ていることが指摘されています。
【フィルターの図】

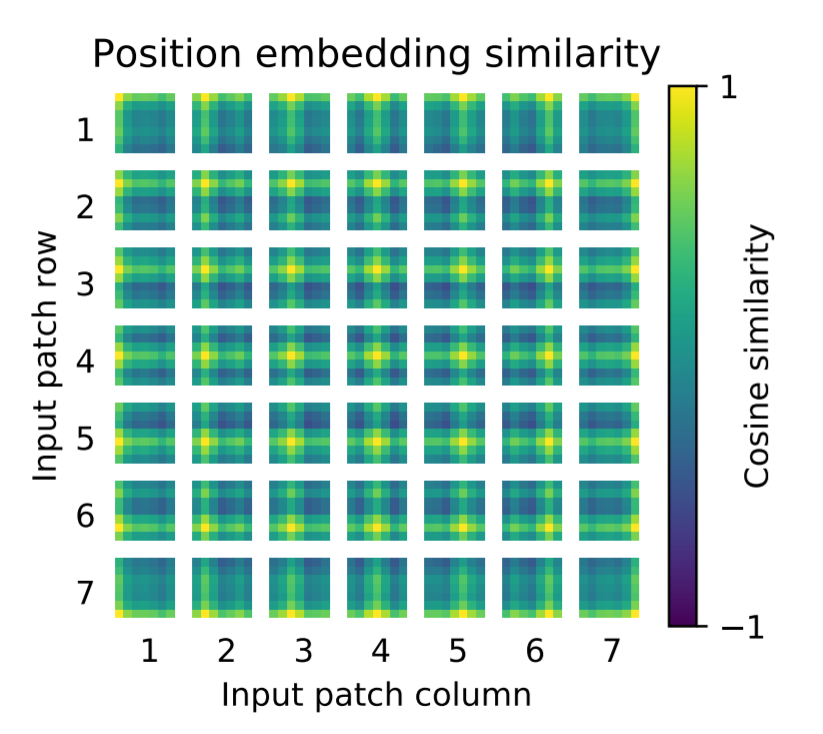
Position Embedingについて
線形射影の後、パッチ表現を学習したPosition Embeddingが追加されます。下図は、モデルが、Position Embeddingのコサイン類似度が画像内の距離を符号化するように学習していることを示しています。近いパッチほど類似したPosition Embeddingを持つ傾向があります。黄色が類似度が高く、薄暗くなるほどコサイン類似度がさがります。
例えば、左上の(1、1)のパッチをみてみましょう。左上が黄色で、左側と右側がかすかに緑色でほかは基本的に薄暗い青色をしています。まず左上の黄色部分は自分自身との比較なので当然類似度は1となり黄色を示します。ほかの部分にかんしていえば、周囲と同じ列や行にある部分はおなじように黄色になり、反対に右下に向かって色が薄暗くなっています。そのため、中央の(4、4)のパッチなどは、きれいに色合いが中心から外側に向かって黄色から紫になっていく様子がみれます。さらに、この表にはきれいに行-列構造が現れ、同じ行・列にあるパッチは類似した位置情報が埋め込まれていることがわかります。
本論文では、Position Embedingをめぐって、様々な手法が試みられたことは上述しましたが、このように一次元情報を付与するPosition Embeddingで2D画像トポロジーに相当する表現を学習することが可能であったため、わざわざ二次元情報を付与するPosition Embeddingは採用されませんでした。
【Position Embbedingのコサイン類似度】
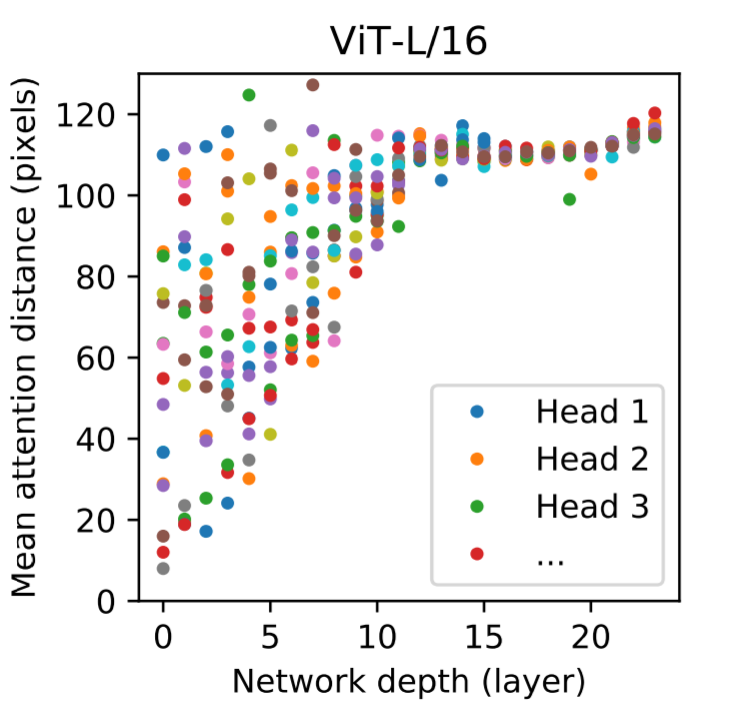
Transformer EncoderのAttentionについて
異なる層でのAttentionの重みを利用して情報が統合される画像空間の平均距離=「Attention distance」を分析することで、Vision Transformerが画像全体の情報を統合するためにSelf-Attentionの情報をどのように利用しているのかを理解することができます。「Attention distance」を計算したのが下図です。この距離はCNNの受容野の大きさに似ていることが指摘されています。
「Attention distance」は下層のヘッド間(下図左部)で大きくばらついてることがわかります。このことはあるヘッドは画像の大部分に注目し、他のヘッドは近くの小さな領域に注目していることを意味しています。深さが増すにつれて、すべてのヘッドで「Attention distance」が増加しています。これはネットワークの後半では、ほとんどのヘッドが画像全体を注目していることを意味します。
【Attention distance図】
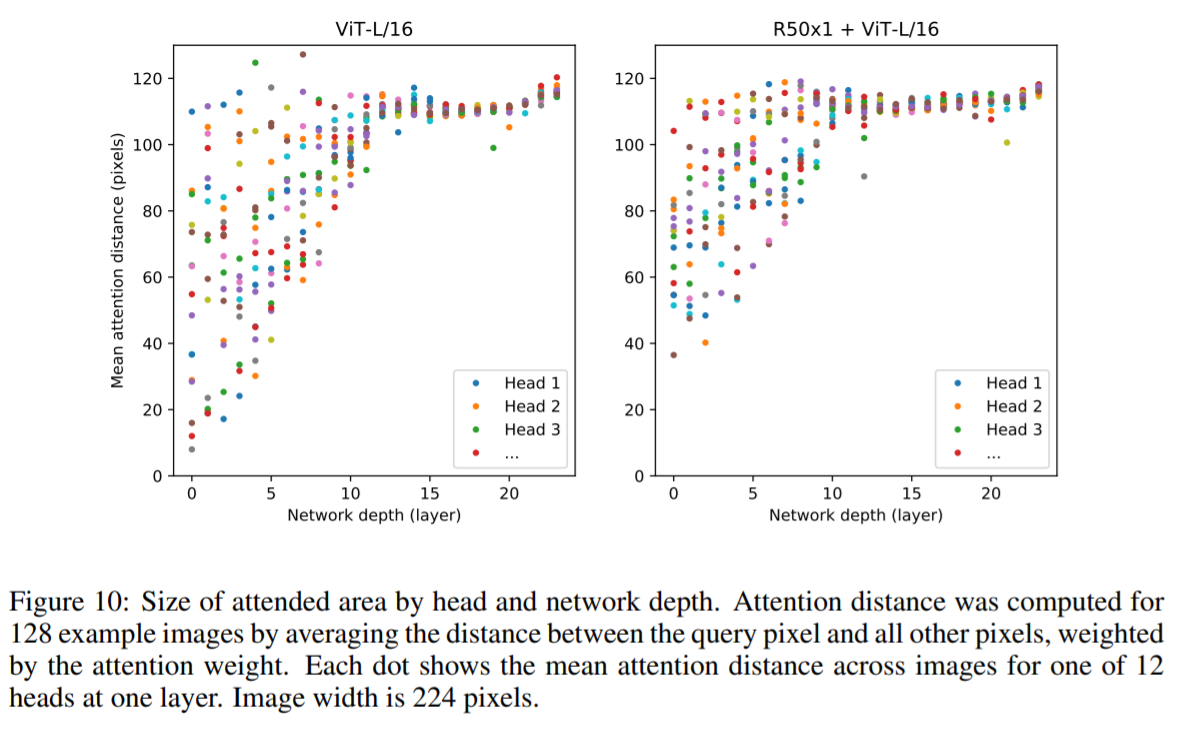
なお、下図はResNetを組み込んだHybred Architechture(下図右部)との比較を示したものです。Hybrid Architectureでは、ResNetから抽出された特徴を用いているため、早い段階である程度まとまった大きさの領域を見ていることがわかります。それに対して、Vision Transformerは小さい領域からかなり大きな領域まで幅をもってみていることがわかります。
【Attention distance比較図】
MLPの画像分類について
下図はAttentionが最終的にどのように画像に注目して、画像分類タスクを行っているのかをわかりやすく示した図です。Vision Transformerでは、分類するうえで必要な画像領域に注目していることがわかります。例えば、一番上の写真は犬として分類してほしいものですが、きれいに犬の顔を中心に注目していることがわかります。
【Vision Transformerの注目部位】

実験について
論文では、Vision Transformerの精度をベンチマークテストで確認する実験だけでなく、様々な観点から実験が行われています。以下では、それらの実験の目的と結果、考察をみていきます。
分類性能実験のセットアップ
実験では、様々なタイプのモデルが用意され、各モデルのデータ要件を理解するために、様々なサイズのデータセットで事前学習を行い、多くのベンチマークタスクを評価しています。
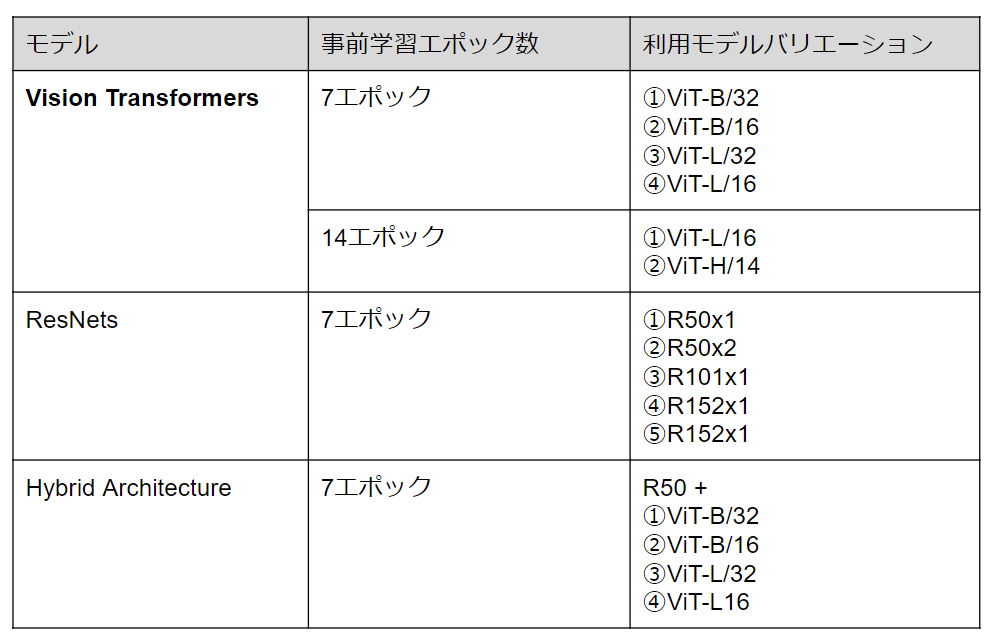
モデルのバリエーション
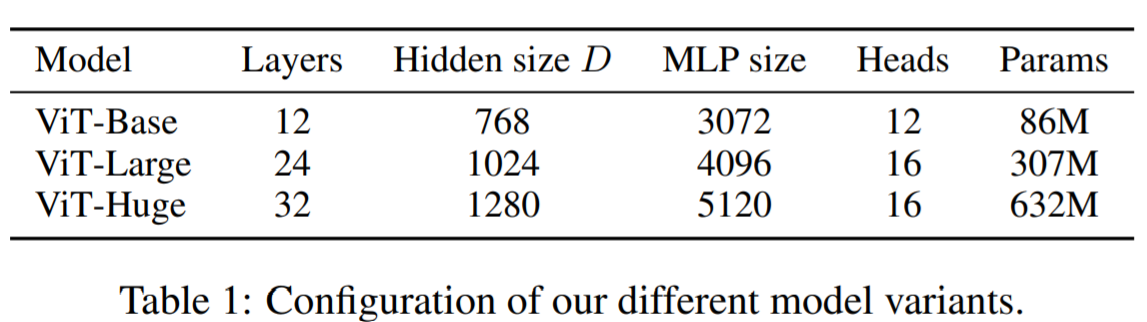
Vision Transformerの実験は、下図に示されるような構成をもつBase、Large、Hugeの三タイプで実験が行われています。なお、表記としては、ViT-L/16は、「16×16の入力パッチサイズ」を持つ「Large」モデルを意味します。なお、このモデル構成はBERTを参考にして作成されたとのことです。
最大モデル(Huge)のパラメータ数は6憶3200万個ということで、かなり大規模なことがわかります。ただし、自然言語処理分野をにぎわせたGPT-3のパラメータ数は1750億個なので、そこと比べるとかなり小さいとも言えます。論文では今後のモデル拡大がひとつの研究課題であると述べていますが、そう考えるのも当然といえます。
【各モデル構成表】
論文では、画像をパッチに分割する代わりに(上述のモデル構造の①部分)、ResNetを用いて特徴マップを取得してTransformerへの入力データとするHybrid Architectureも考案され、実験されています。ResNetに関しては、バッチノルム層をグループノルムに置き換えた標準化CNNが用いられています。これは性能を向上させるためです。Hybrid Architectureには、中間特徴量マップを1「ピクセル」のパッチサイズとして同じようにTransformerに投入します。
なお異なるシーケンスの長さを比較するために、(i)通常のR50のステージ4の出力を取る場合と、(ii)ステージ4を削除して、同じ数の層をステージ3に配置し(それでも合計50)、ステージ3の出力を取る場合、を設定しています。オプション(ii)では、シーケンスの長さが長くなるため、より計算コストの高いViTヘッドになります。
データセット
モデルのスケーラビリティを調べるために、以下のデータセットが事前学習に利用されました。(なお、学習時に重複したデータがある場合は、重複排除がなされています。)
【データセット】
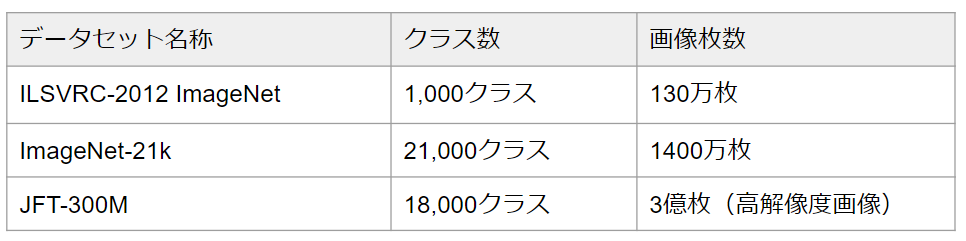
これらのデータセットで事前学習したモデルを以下のベンチマークタスクに転移して検証しています。
【ベンチマークタスク】

VTABは、Googleが提案したベンチマークです。事前学習の汎用性を知るためのものです。事前学習したモデルが、小数の下流タスク用のデータセットを学習して、どの程度多様なタスクに対応できるのかを測ります。そのため評価するモデルには、以下の要件を満たすことが求められています。
【要件】
(1) ダウンストリームの評価タスクで使用されるデータ(ラベルまたは入力画像)について事前学習時に利用してはいけない。
(2) ハードコードされたタスク固有のロジックが含まれていていけない。(つまり、評価タスクはテストセットのように見たことがないものとして扱われる必要があります)
そのうえで、データが限られている新しいタスクへのアルゴリズムの一般化を評価するために、タスクごとに1000の例のみを使用してパフォーマンスが評価されます。VTABでは、19のタスクが用意されており、それらは以下の3分類に分けられています。
【3分類】
(1) Natural – 標準的なカメラで撮られた一般的なオブジェクト、きめ細かいクラス、または抽象的な概念の画像(Pets、CIFARなどが該当)
(2) Specialized – 医用画像やリモートセンシングなどの特殊な機器を使用してキャプチャされた画像
(3) Structured –位置把握のような幾何学的な理解を必要とするタスク
VTABについて更に詳しく知りたい方は、以下のGoogle AI Blogをご参照ください。
「The Visual Task Adaptation Benchmark」
https://ai.googleblog.com/2019/11/the-visual-task-adaptation-benchmark.html
事前学習とFine-tuninig
●事前学習
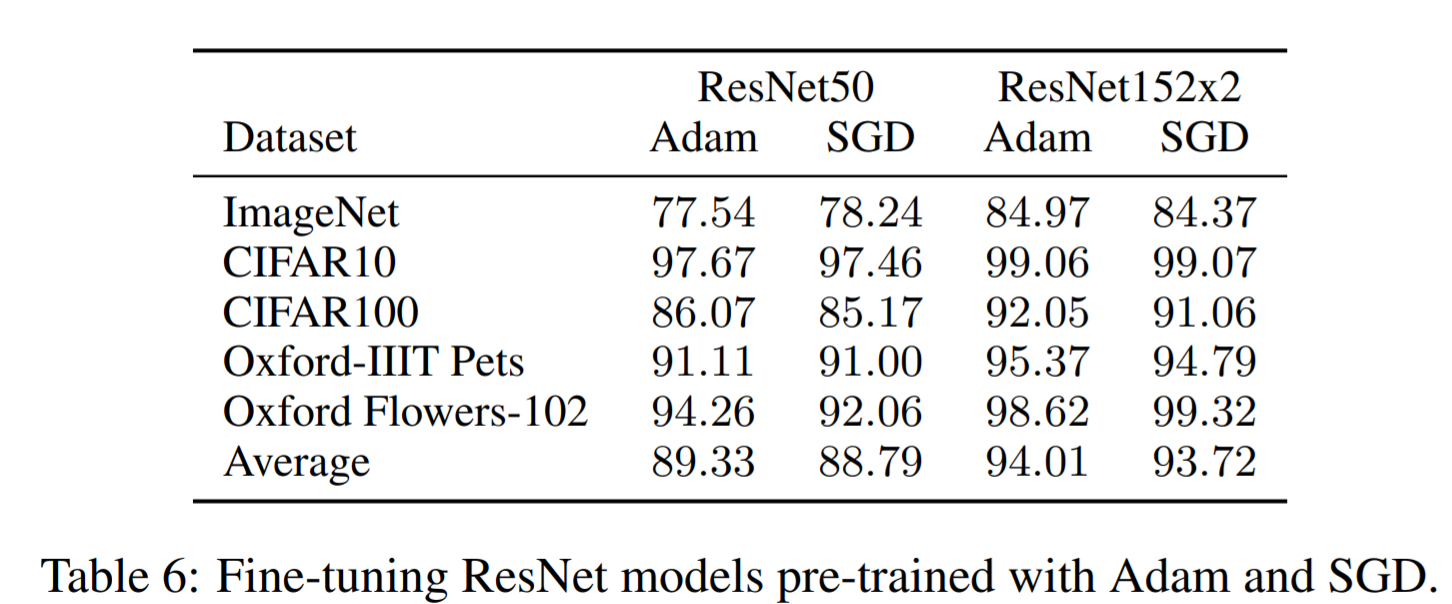
事前学習では、ベースとなっているResNetsを含むすべてのモデルでオプティマイザーにAdam(β1 = 0.9、β2 = 0.999、バッチサイズ=4096、weight decay = 0.1 のハイパーパラメータを適用)を用いて学習しています。これはすべての転移学習をする際に有効な値とされています。また一般的にはResNetにおいてはSGDの方がAdamよりも優れた働きをするとされています。しかし、論文ではResNetsに対してAdamの方がSGD よりもわずかに優れた働きをすることが示されたことで、Adamが採用されています。下図がAdamとSGDを比較した結果です。
【AdamとSGDの比較図】
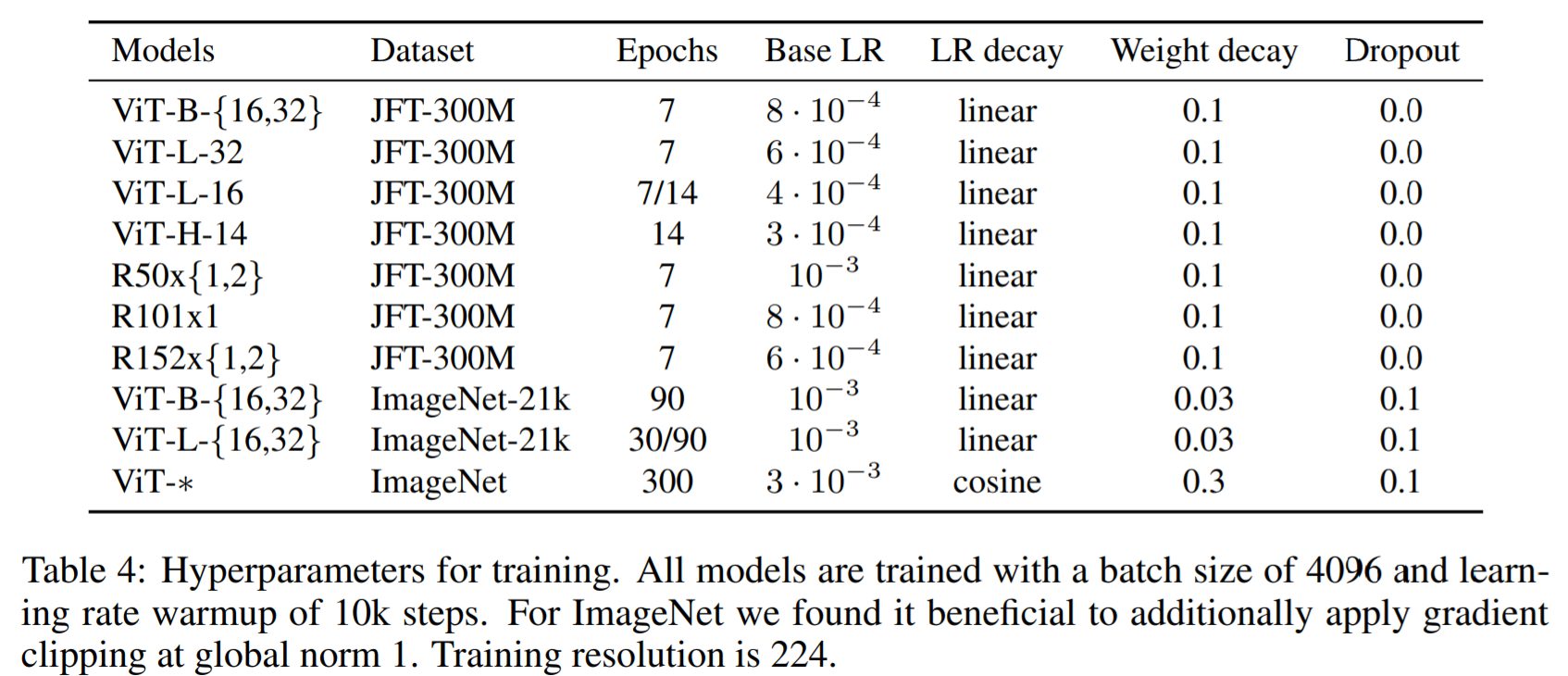
事前学習のハイパーパラメータ
ImageNet上でゼロからモデルを学習する際には、強力な正則化が重要であることが実験から明らかになりました。またドロップアウトを使用する場合、TransformerのAttentionにおけるqkv-projectionを除くすべてのDense LayerおよびPosition Embeddingを追加した直後に適用されるべきことがわかりました。
なおHybrid Architectureは、ViTモデルと全く同じ設定で訓練されており、すべての学習は解像度(224*224)で行われています。
【事前学習のハイパーパラメータ】
●Fine-tuning
Fine-tunig時には、すべてのモデルのオプティマイザーとしてモーメンタム付きのSGDがバッチサイズ=512で利用されています。
Fine-tuningに対するハイパーパラメータ
VTABのハイパーパラメータについては、以下のプロトコルにしたがって設定されています。
①各タスクについて、200サンプルの検証セットで2つの学習率とスケジュールの中から最良のものを選択する。
②最良のハイパーパラメータを用いて、1k個のサンプルデータセット全体で再学習を行う。
なお、Vision Transformerはすべてのタスクで高解像度(384 × 384)を使用することが最も精度がよかったため、高解像度を利用する設定になっています。
【Fine-tuningのハイパーパラメータ】

メトリックス
実験によって、Fine-tuningされる場合と、Few-shotされる場合があります。Fine-tuninigに関しては、各モデルをそれぞれのデータセット上でFine-tuningした後の性能です。Few-shotの場合は、訓練画像のサブセットの(固定された)表現を{-1, 1} K個のターゲットベクトルに写像する正則化線形回帰問題を解くことによって精度が得られています。
基本的に論文では、Fine-tuningした場合の精度で比較されていますが、Fine-tuningにコストがかかりすぎるような場合には、その場ですぐに評価するために線形のFew-shot精度で比較する場合があります。
分類性能実験の結果
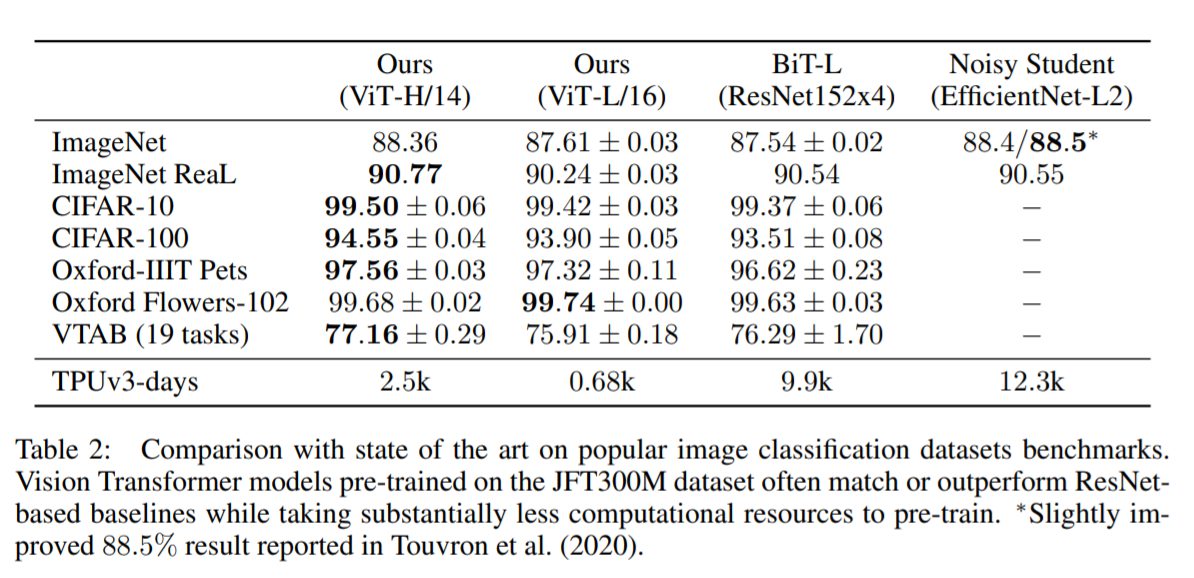
ViT-H/14とViT-L/16を、最先端の結果を有しているCNN型モデルと比較しました。すべてのモデルはTPUv3ハードウェア上で学習されています。(学習した日数が結果の図中下段に「TPUv3-days」で示されています。)
結果
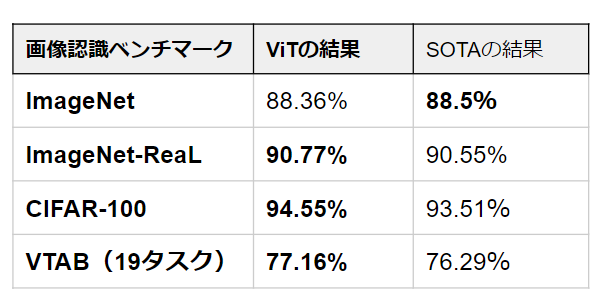
ViTモデルは、すべてのデータセットでBiT-Lと同等か、またはそれを上回る性能を示したうえで、学習に必要な計算リソースが大幅に少なくなっています。計算リソースはTPUv3-daysで、ViT-H/14⇒2.5k、ViT-L/16⇒0.68k、BiT-L⇒9.9k、Noisy Student⇒12.3kだと報告されています。
中規模モデルのViT-L/16でも、最大規模モデルのViT-H/14には劣ってしまうもののそれでも従来のSOTAを超えています。仮に従来以上の性能をだしたいということであれば、ViT-L/16でいいため、単純に約1/14~1/20(0.68K÷9.9K、0.68K÷12.3K)倍の計算リソースでいいことがわかります。
より大きなモデルであるViT-H/14は、特にImageNetやCIFAR-100、VTABタスクなど、より難易度の高いデータセットで性能をさらに向上させていることがわかります。場合によってはかなりの割合(CIFAR-100では1%など)で、最先端モデルを超えています。ImageNetでは、ViTはノイズの混じった標準的なラベルではNoisy Studentよりも約0.1%精度が劣っていますが、よりアノテーションを正したReaLラベルで評価した場合にはNoisy Studentを上回っています。
なお学習効率が非常によくなっていますが、このことについては論文上で「事前学習の効率はアーキテクチャの選択だけでなく、学習スケジュール、オプティマイザ、重み減衰などの他のパラメータにも影響される可能性がある」として注意を促しています。
なお、もし自分でも同じようにこのモデルを学習させ利用してみたいと考えた場合、GoogleのクラウドサービスであるGCP(Google Cloud Platform)でCloud TPUv3(420T FLOPS/ メモリ 128 GB HBM)を利用することができます。(最安値の米国リージョンで)普通に利用すると1 時間あたり$8.00/TPU、プリエンプティブルの場合でも、1 時間あたり$2.40/TPUかかります。(プリエンプティブルとは、Google側の都合で利用中に急に停止される可能性があるサービスでそのためかなり格安になっています。)1日フルで利用すると、192ドル(プリエンプティブルでも57.6ドル)かかることになります。つまり、1k(=1千)日分利用すると約2000万円、10K(=1万)日分利用すると約2憶円かかります。そのため、一般人で再現できるとは言い難いモデルです。
【実験結果の概略図】
【実験結果の詳細図】
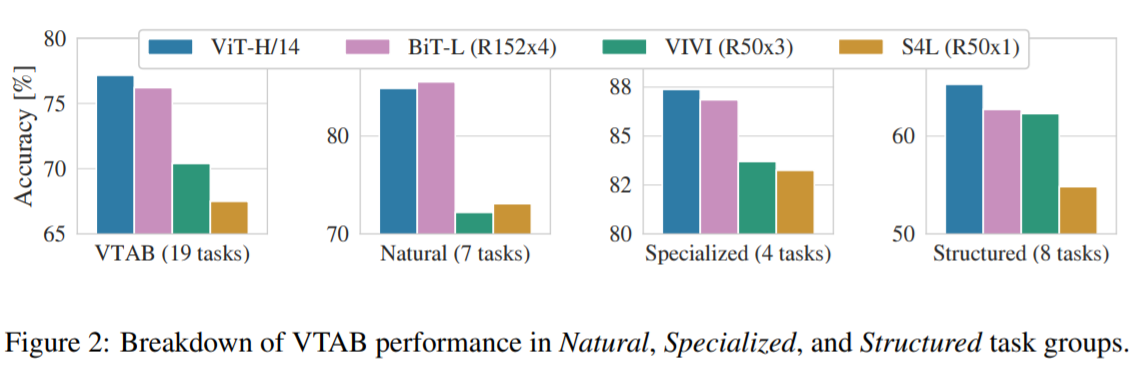
VTABタスクの結果
VTABタスクを3つのグループ(Natural、Specialized、 Structured)ごとに比較したものです。

結果
Naturalタスクでは、BiT-L(R152x4)はViT-H/14をわずかに上回っていますが、論文ではその差は誤差の範囲内とみています。Specializedタスクでは逆転してますが、同様に誤差の範囲としています。論文ではViTが有意に優れているといえるのは、Structuredタスクに関してのみと結論付けています。
【VTABタスクの結果図】
「事前学習のデータ要件」について
論文では、二つの実験を行って事前学習時のデータセットの大きさがモデルの性能にどのようにかかわっているのかを明らかにしています。
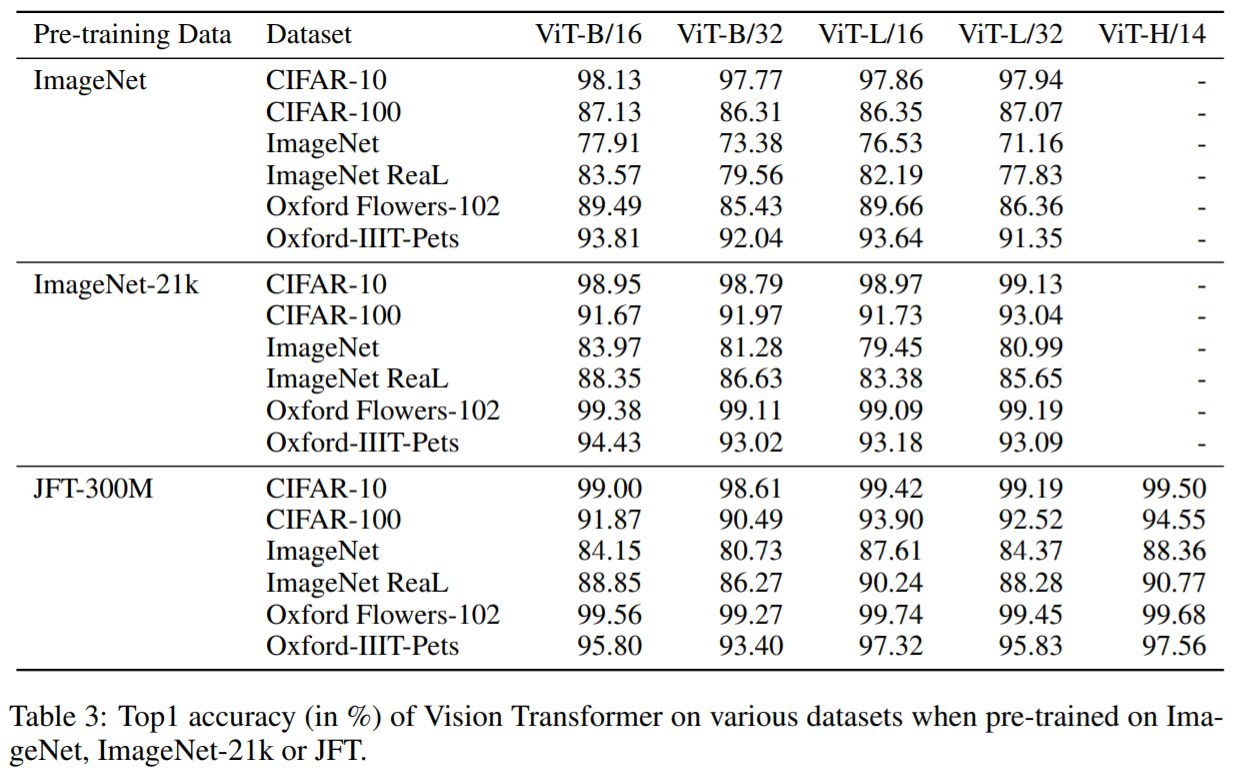
最初に、データセット(ImageNet、ImageNet-21k、JFT300M)ごとにViTモデルの事前学習を行ってImageNetを用いて性能実験をします。(最高のパフォーマンスを得るために、3つの正則化パラメータ(重み減衰、ドロップアウト、ラベル平滑化)を最適化しています。)
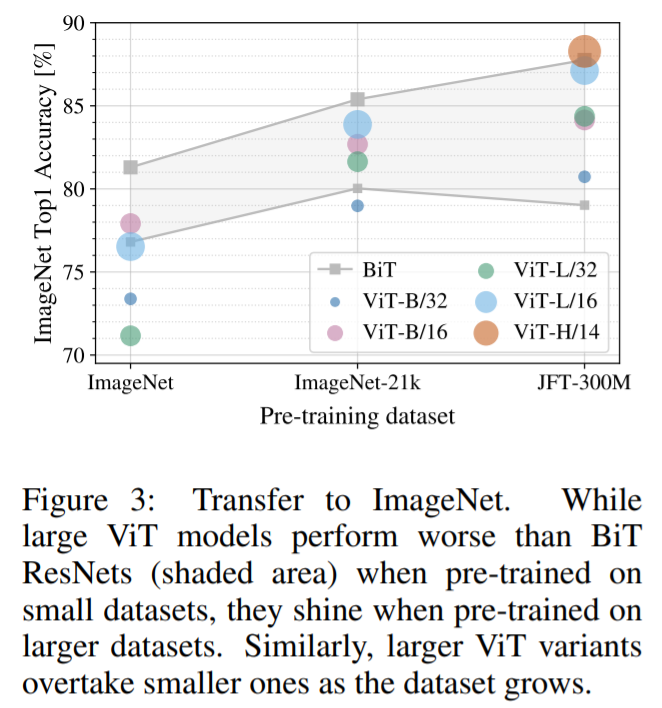
下記図は、ImageNetに対するFine-tuning後の結果を示しています。最小のデータセットであるImageNetで事前に学習した場合、ViT-LargeモデルはViT-Baseモデルよりも精度が悪化してしまっています。しかし、ImageNet-21kの事前学習では、両者の性能は同等まで向上しています。そして、さらに大規模なJFT-300Mでのみ、より大きなモデルが性能上で優位にたっていることが確認できます。なお、BiTの結果も示されており、ImageNet上ではViTを上回る性能を示していますが、より大きなデータセットではViTが逆転していることがわかります。
このことから、Vision Transformerは大規模なデータセットで事前学習を行うことで、その性能を発揮できることがわかります。(本論文では、大規模なJFT-300Mのデータセットで事前学習を行った場合、最も良いパフォーマンスが発揮されています。)これはCNN型モデルよりも画像に対する帰納的バイアスが少ないため、データセットが少ないとその性能を発揮しきれないためであると考えられます。
【事前学習時のデータセット規模の違いに対する性能実験】
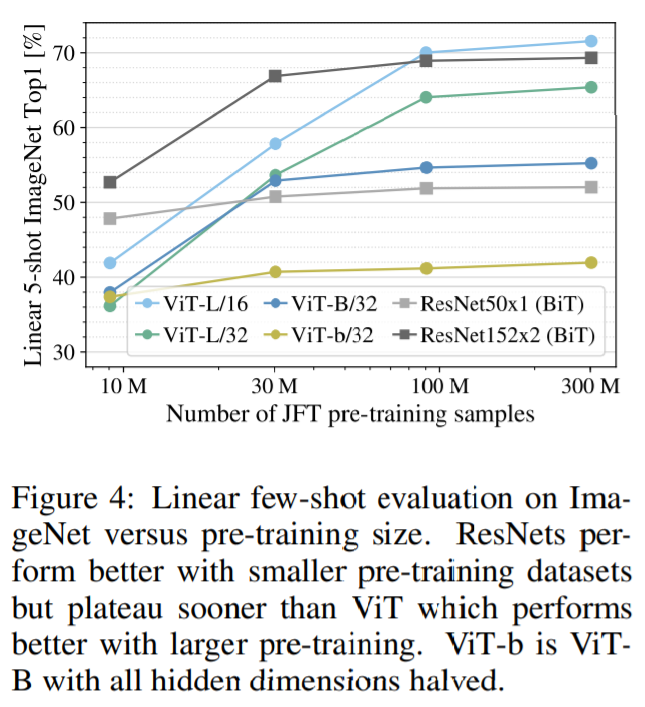
第二の実験では、9M、30M、90Mのランダムなサブセット(部分データセット)及び、JFTの全データセット(300M)でモデルを学習させます。小さいサブセットでは追加の正則化は行わず、すべての設定で同じハイパーパラメータを使用しています。この方法によって、正則化の効果ではなく、本質的なモデル特性を評価することが可能となります。ただし、early stoppingを使用し、訓練中に達成された最高の検証精度を報告しています。なお実験では、計算量の問題から完全なFine-tuningの精度ではなく、数ショット学習の精度が報告されています。
ViTは、より小さなデータセットにおいては同等の計算コストでResNets(BiT)よりもオーバーフィットしてしまっています。例えば、ViT-B/32 は ResNet50(BiT)よりもわずかに高速ですが、9M のサブセットでは性能が大幅に低下していることがわかります。ただし、90M以上のサブセットでは性能が向上しています。同じことが ResNet152x2(BiT)とViT-L/16 にも当てはまります。
この結果は、CNNによる学習はより小さなデータセットには有効ですが、より大きなデータセットではVision Transformの様に関連するパターンの学習で十分であるというこれまでの推論を裏付けるものといえます。
【事前学習時のサブセットと全データセットを用いた比較】
「スケーラビリティ」について
論文ではモデルの大きさの違いによる性能の違いについても実験が行われています。事前学習にJFT-300Mを利用し、各モデルの性能と事前学習コストを比較して評価しています。(JFT-300Mを利用するのは、データサイズがモデルの性能のボトルネックにならないようにするため。)
評価された各モデルは以下の通りです。
【スケーリング実験の結果図】
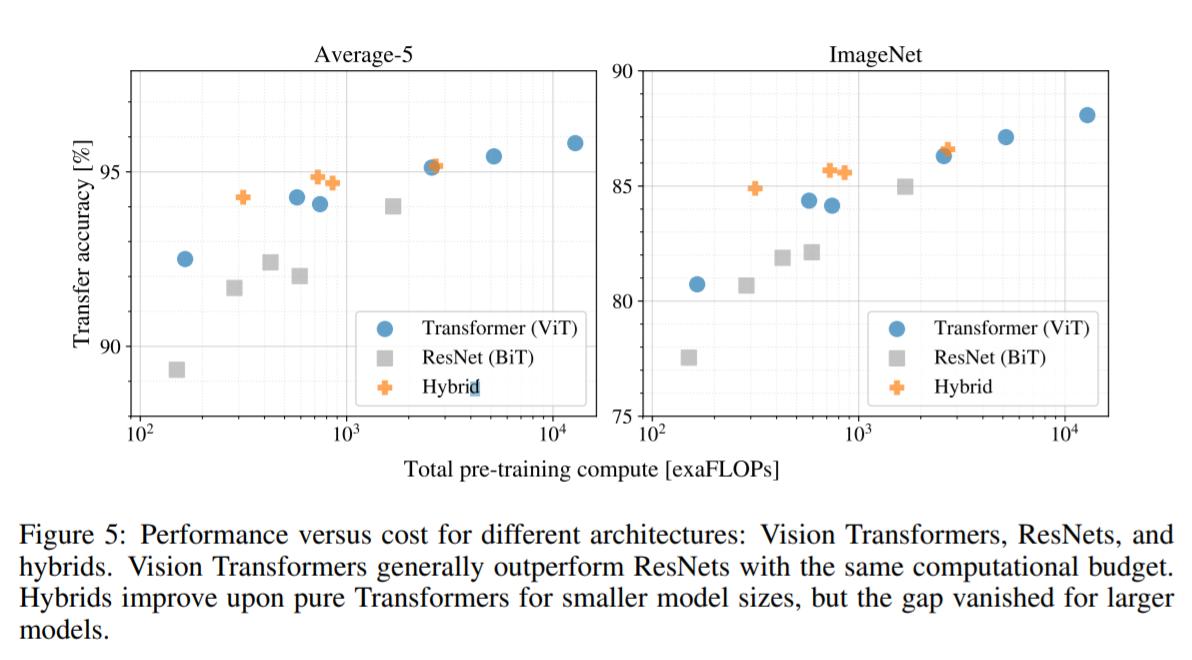
【考察】
①性能と計算量のトレードオフ
ViTは同じ性能を達成するために使用する計算量が約2倍少なくなっており、計算量に対する性能という側面ではResNets(BiT)を圧倒しています。
②Vision Transformers のスケーラビリティ
ViTは実験で試された範囲内では性能が飽和していないことが示されています。これは、今後のスケーラビリティの拡大の可能性を示しています。
「スケール拡大」について
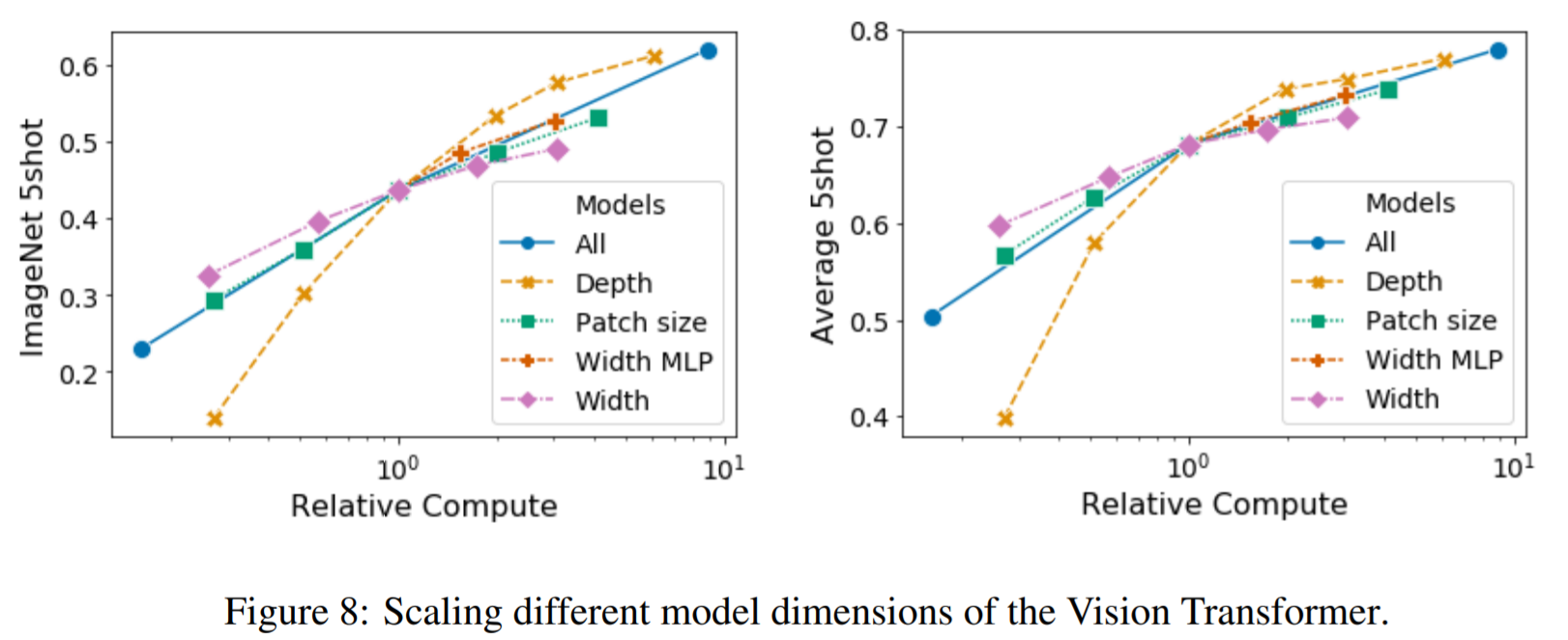
論文では、Vision Transformerのスケーリングに対して、適切なTransformerの構造を探るための実験が行われています。下図左部は、さまざまな構成のImageNet上での5ショット性能を示しています。(基本は「Layer=8層、D = 1024、DMLP = 2048、パッチサイズ=32」のViTモデルです。)
層を深くしていくことで最大の改善が得られ、64層まで明らかに改善されていることがわかります。しかし、早い段階(16層目以降)で、すでにその改善幅が減少していることがわかります。それに対して、モデル幅を大きくすることはあまり有効な改善を示していません。またパッチサイズを小さくして有効なシーケンス長を長くすると、パラメータを導入しなくても非常にロバストな改善が見られます。
これらの結果から、論文では「パラメータの数よりも計算量の方が性能の予測に適している可能性がある」ことが指摘されています。その場合、スケーリングは幅よりも深さを重視すべきであることを意味します。また全体として、すべての次元を比例的にスケーリングすることで、ロバストな改善が得られることが図からわかります。
【モデルスケールの変更実験結果】
「自己教師あり学習」について
Transformerは、自然言語の分野で革新的なモデルとなりましたが、その要因は優れたスケーラビリティだけでなく、大規模な自己教師あり事前学習にもあります。論文では、BERTで使用されているマスク付き言語モデリングタスクを模倣した、自己学習のためのマスク付きパッチ予測に関する予備的な探索が行われています。自己教師あり事前学習により、ViT-B/16モデルはImageNet上で79.9%の精度を達成し、スクラッチからの学習に比べて2%の有意な改善が示されています。しかし、それでも教師あり事前学習に比べて4%低いことも示されています。論文では、自己教師あり学習に発展の可能性があるとみており、今後の研究課題としてしています。
「経験的な計算コスト」について
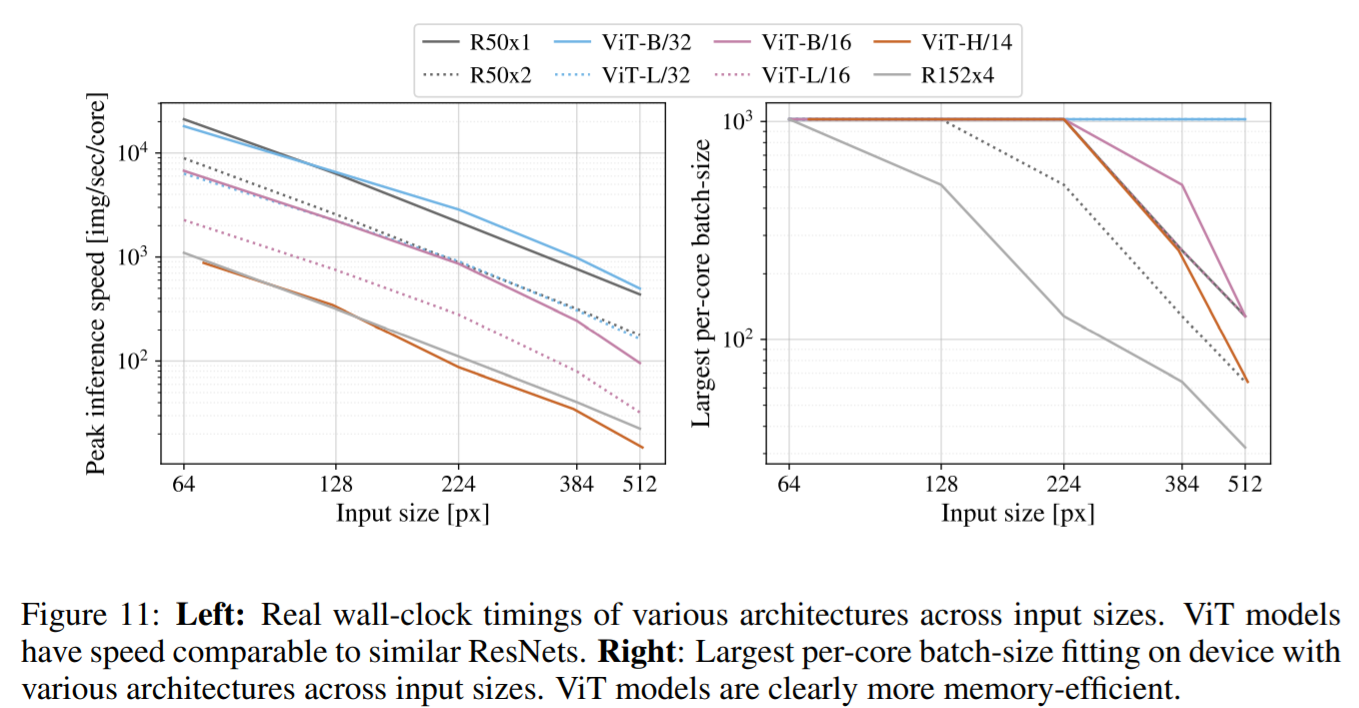
レーン幅やキャッシュサイズなどの要因から、理論的なFLOPとハードウェア上のアーキテクチャの実際の速度は一致しません。そのため、実際上の計算コストに対しての実験も行われています。実験では、TPUv3ハードウェア上で、主要モデルの推論速度が測られました。(なお推論速度とバックプロップ速度の差はモデルに依存しない一定の要因のため、推論速度のみが測られています。)
下図左部は、さまざまな入力サイズで、1つのコアが1秒間に処理できる画像数を示しています。各点は、広範囲のバッチサイズで実験された際に測定されたのピーク性能が示されています。画像サイズの拡大に伴う理論的な二次スケーリング(急激な落ち込み)は、ViTにおいては最大解像度の最大モデルでのみ確認されていると論文ではしています。
下図右部は、各モデルがコアにフィットできる最大のバッチサイズについて示した図です。大規模なデータセットへのスケーリングにはバッチサイズが大きい方が適しています。図ではViTの方が、画像サイズがおおきくなっても(解像度が高くなっても)バッチサイズを比較的大きな値で維持できることが示されています。このことから、メモリ効率の点では大規模なViTモデルがResNet(BiT)モデルよりも有利であることがわかります。
【コストの比較図】
「Axial Attention」について
Axial Attentionは、多次元テンソルとして編成された大規模な入力に対してSelf-Attentionを実行するための、シンプルでありながら効果的な手法と一般的にされています。Axial Attentionの基本的な考え方は、一次元化された(Flattenされた)入力データに対して1次元のAttentionを適用する代わりに、入力テンソルの1つの軸に沿って、それぞれが複数のAttention操作を実行するというものです。各Attentionは特定の軸に沿った情報を混合し、他の軸に沿った情報は独立したままにします。
本論文では他の論文で提唱されている、ResNet50内のカーネルサイズが3×3のCNNをすべてAxial Attention(相対位置符号化によって増強された行と列のAttention)に置き換えたAxial ResNetモデルを実装した実験が行われています。
なお、実験では、1次元のパッチのシーケンスではなく、2次元の形状で入力を処理するようにViTを修正し、Self-AttentionとMLPの代わりに、行Self-AttentionとMLP、そして列Self-AtteintionとMLPを組み合わせたAxial Transformerブロックを組み込んだAxial-ViTも用いています。
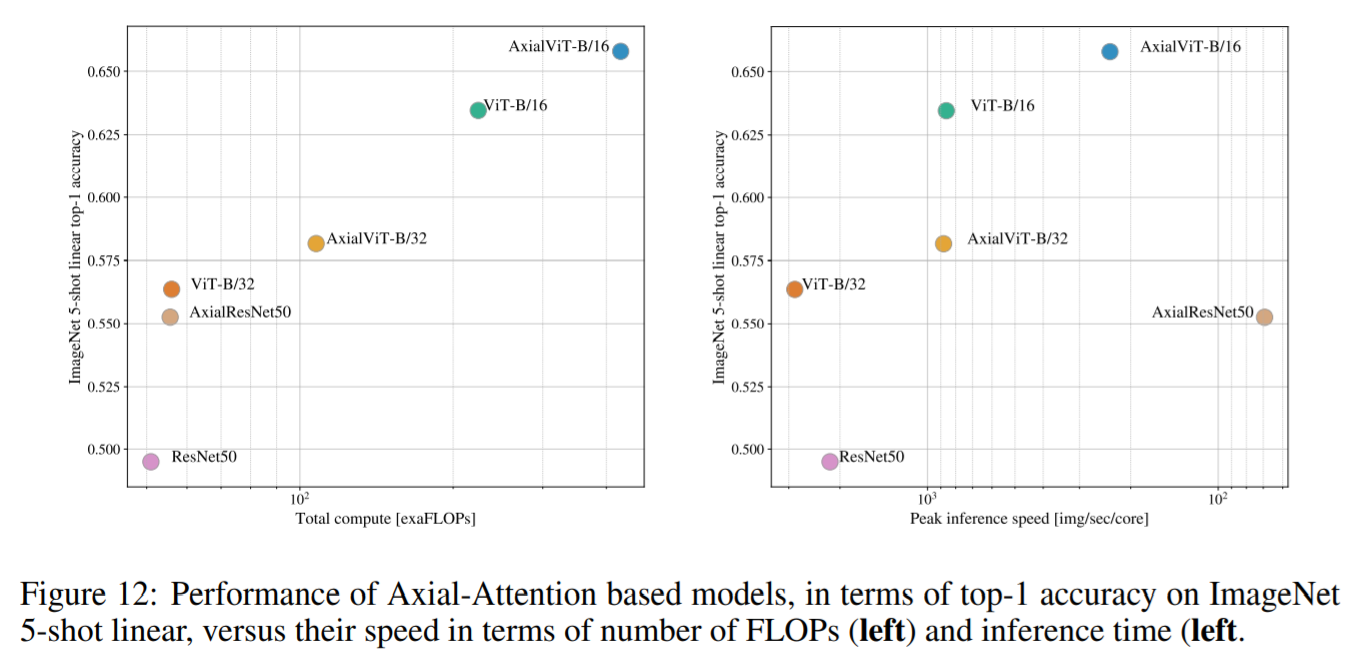
下図は、ImageNet 5shot linear上のAxial ResNet、Axial-ViT-B/32、Axial-ViT-B/16を含めた性能を、JFTデータセット上で事前学習を行ったうえで、FLOP数と推論時間(秒当たりの例)の両方の観点から示しています。Axual-ViT-B/32とAxual-ViT-B/16の両方とも、性能の面ではViT-Bよりも優れています。ただし、引き換えに計算量が多くなっています。これは、Axial-ViTモデルでは、グローバルSelf-Attentionを持つ各Transformerブロックが、行と列のSelf-Attentionを持つ2つのAxialTransformerブロックに置き換えられたことによるものと考えられます。Self-Attentionが動作するデータのシーケンス長はAxial Transformerの場合の方が小さくなりますが、ブロックごとに余分なMLPが発生するためです。
AxialResNetについては、精度と計算量のトレードオフの点では合理的に見えますが(下図左部)、単純な実装ではTPU上で非常に遅くなります(下図右部)。
【Axial Attentionの性能比較図】
まとめ
Vision Transformerは、Transformerの特性を最大限生かした形で画像処理に応用すること目指したモデルです。そのため、それまでのSelf-Attentionを使用した先行研究とは異なり、CNNなどの画像処理特有のアーキテクチャを導入していません。その代わりに、画像をパッチのシーケンスとして解釈することで、NLPで使用されるような標準的なTransformerで処理することに成功しました。多くの画像分類データセットで最先端モデルと同等かそれ以上の性能を発揮すると同時に、事前学習に対して比較的安価な計算で済むことがわかりました。特に大規模なデータセットでの事前学習と組み合わせると、よりよく機能することが示されました。
なお論文では、以下の課題が残っていることも指摘されています。
①ViTを検出やセグメンテーションなどの他の画像処理タスクへの応用
⇒画像分類タスク以外の応用が今回の研究ではおこなわれていません。
②自己教師あり事前学習の発展
⇒今回の論文で行われた初期実験では、自己教師付き事前訓練からの改善は示されましたが、自己教師あり学習と大規模な教師あり事前学習の間にはまだ大きなギャップがあります。
③モデルの大規模化
⇒モデルのサイズを大きくしても性能の飽和が今回の論文ではまだ確認できていません。そのため、ViTをさらにスケールアップすることが求められています