はじめに
FAIR(Facebook AI Research)が新たな画像認識に関するプロジェクト「Learning from Videos」を発表したので、ご紹介します。
『Learning from videos to understand the world』
https://ai.facebook.com/blog/learning-from-videos-to-understand-the-world/
概要
FAIRが、Facebook上にアップロードされて公開されている動画に対して自動で音声、文章、及び画像表現を獲得しAIを自己教師あり学習させる取り組み「Learning from Videos」を行うことを発表しました。全世界かつ数百の言語のビデオを学習することは、FacebookのコアAIシステムを改良するだけでなく、新しい体験を可能にするというポリシーを強化することにつながるとしています。
今後、世界中の学習データを利用することで人間のような機械をつくることへの架け橋にもなることが期待されており、現在はReelの推奨システムに利用されています。
詳細
近年、新たな手法の開発やハードウェアの進歩によりAIのレベルは大きく発達しました。そうした発達を支えたのは、人間によってラベルを付与された教師ありデータですが、現在、教師あり学習は発達のボトルネックとなっています。教師あり学習はタスクに直結するデータであり学習効果がすぐにでますが、一方で人手によるラベリングは大きなコストとなり大規模化が難しいという問題があります。そのため、自己教師あり学習として生のデータから直接学習できることが期待されています。
膨大な動画データを自己教師あり学習で利用できるようになると、精度の向上だけでなく、世界の最前線の潮流に適応し、異なる文化と地域にまたがるニュアンスや画像的手がかりを認識することが可能と推定されます。そのために動画から自己教師あり学習ができるモデルが作成されています。
モチベーション
音声認識や画像認識を有効に利用して、膨大なデジタルメモリから重要な時を簡単にとりだせるようにしたい。
GDT
音声と画像を動画から学習してグループ分けする自己教師ありモデル。
モデルのパラメータは、同じビデオから同時に取得されたオーディオコンテンツとビジュアルコンテンツの表現が互いに類似しており、無関係なコンテンツの表現とは異なるように調整(または学習)されます。GDTは、それぞれ同じように聞こえる、または同じように見えるビデオに基づいて推奨事項を見つけることができるユニモーダル設定でもうまく機能することが証明されています。
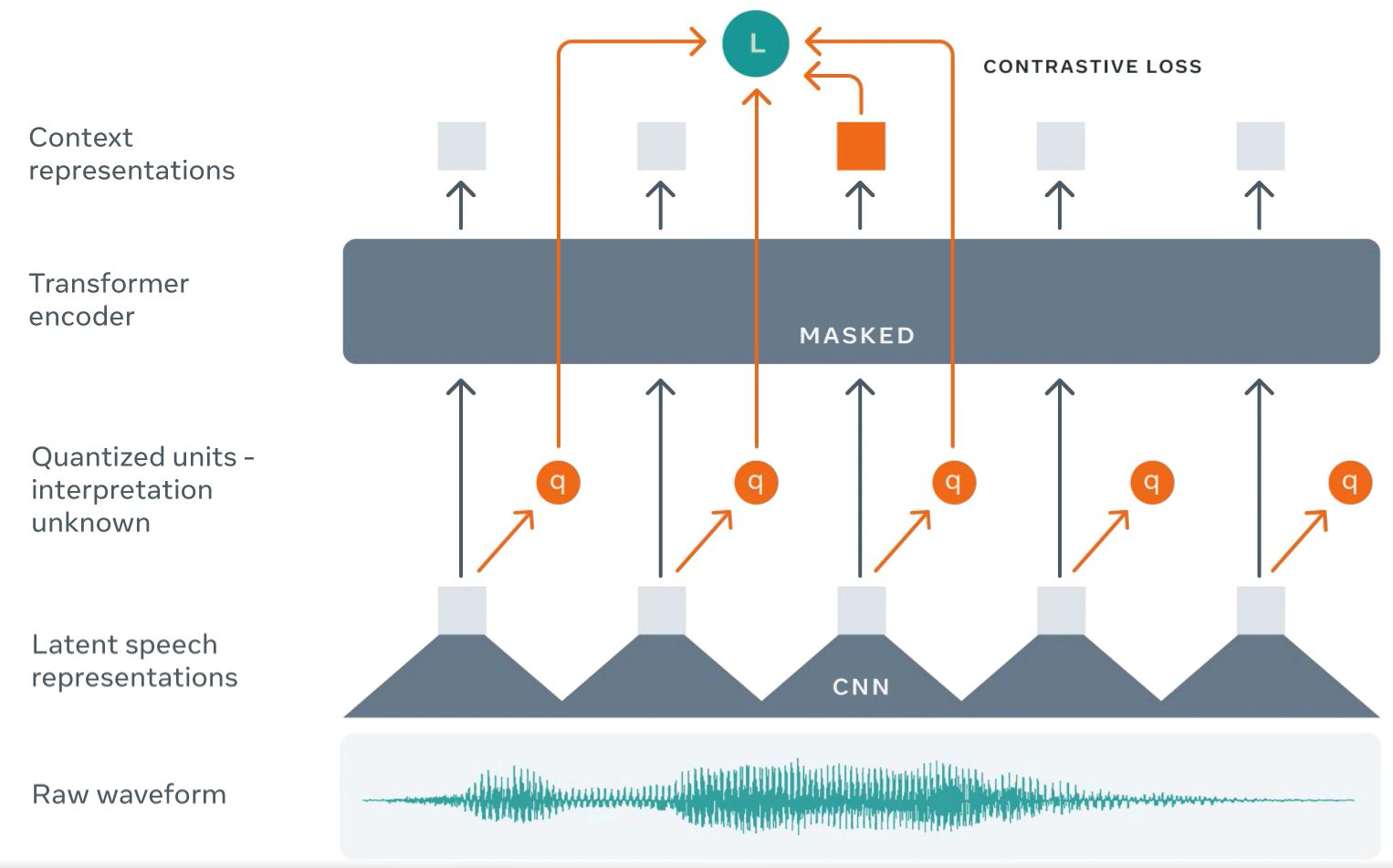
wav2vec2.0
生の音声データから言語の構造全体を学習する音声認識モデル
最初に音声の一部をマスクし、次にマスクされた音声単位を予測することを学習することによって機能します。進行速度のアイデアを提供するために、wav2vec 2.0と自己学習では、LibriSpeech業界ベンチマークで非常に優れた音声認識結果を達成するために10分の文字起こしオーディオが必要とされていますが、同じ結果を達成するために、約1年前までは1000時間近い音声が必要でした。
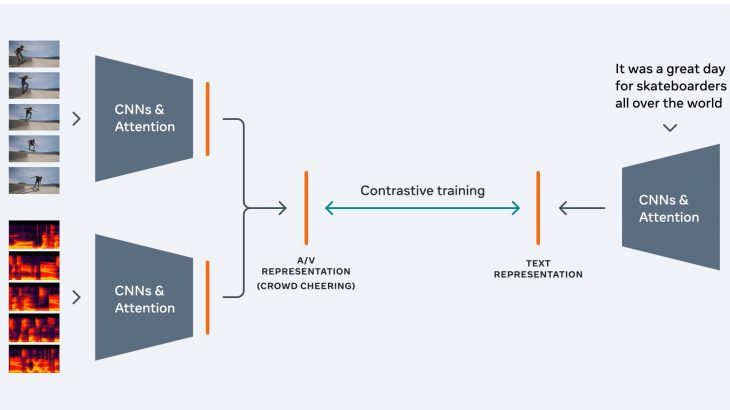
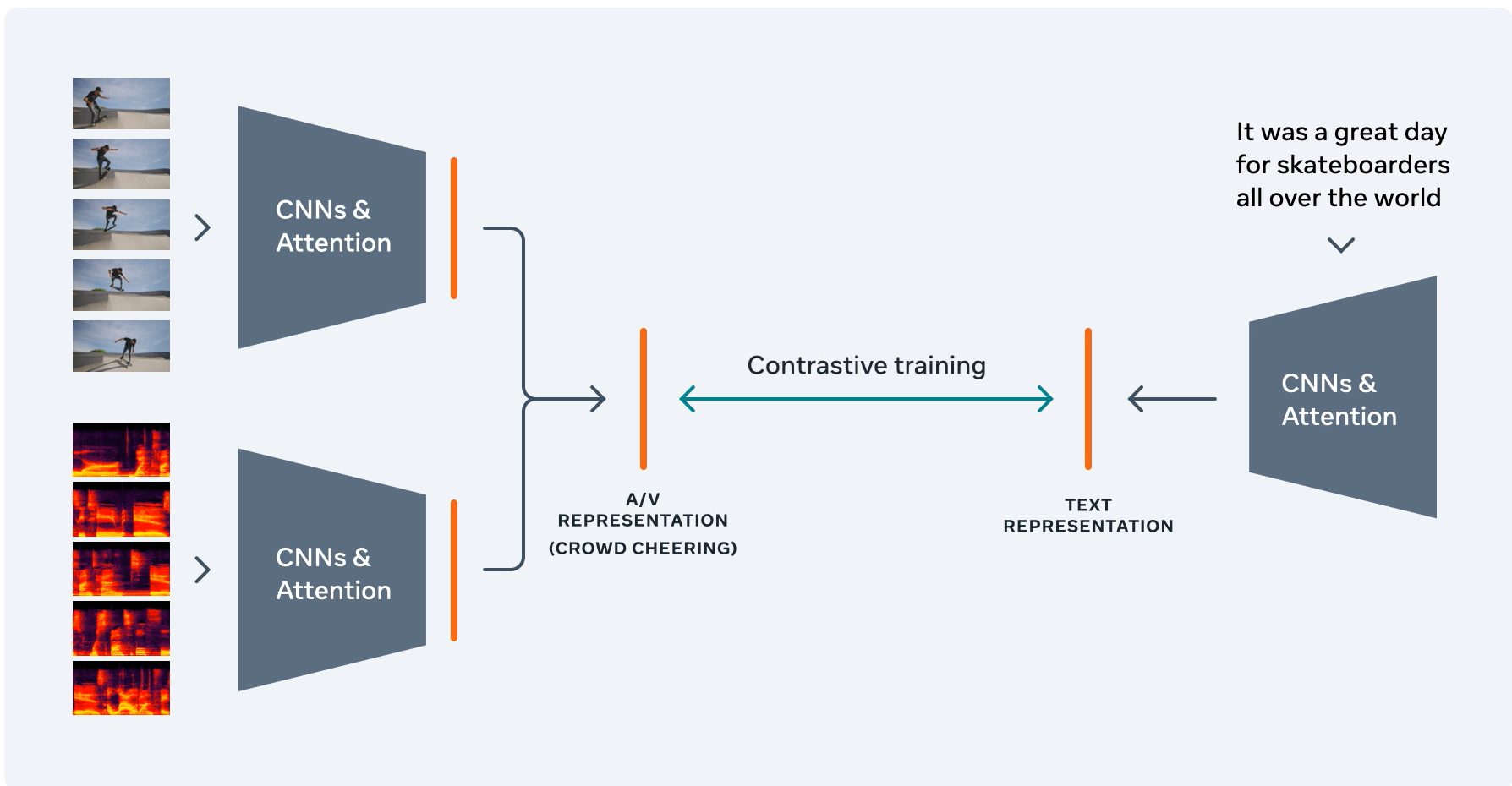
Audio Visual Textual model:AVT model
自己教師あり学習モデルで、音声、画像、テキストの信号をひとつにまとめ、ひとつのベクトル空間で表現することができるようになりました。
一致しないテキストと動画をどのように組み合わせるかが、重要な課題になっています。音声クリップと画像クリップは対応関係にあるが、テキストの文字とクリップの間に類似関係がないため、ビデオ全体から視聴覚情報を集約し、テキストから情報を集約してから、グローバルビデオレベルで2つを比較する必要することになります。なお、これらの情報はCNN、Transformer、RNNを利用することで、それぞれのデータがもつ情報を集約することでもたらされます。
対照学習を使用することで、ビデオエンコーダーとテキストエンコーダーが、一緒に使用される入力に対して類似したビデオ表現とテキスト表現を持つようになります。
まとめ
現在、モデルの大規模化が進み、モデルの容量に対して適切なデータが確保できないことがひとつの問題になっています。そのため、有力な研究施設や団体などでは、データセットをいかに効率よく集めるか、もしくは自己教師あり学習でより精度をあげるようなモデルの研究が進められています。今後、自己教師あり学習の研究が進むことで、これまで考えられていたよりも大幅に巨大なデータセットを学習し、次なる段階のAIが開発されることは確実なため、注視する必要があります。