
はじめに
時系列データを誰でもある程度正確に予測できるような仕組みの構築を行いました。具体的には、データから予測モデルを構築し、だれでも新規のデータに合わせてモデルを常に最適化できるような標準化を行いましたので、ご紹介します。
時系列データの解析・モデル構築の基本的な概念に関しては、「時系列データの予測モデルについて解説!」をご確認ください。
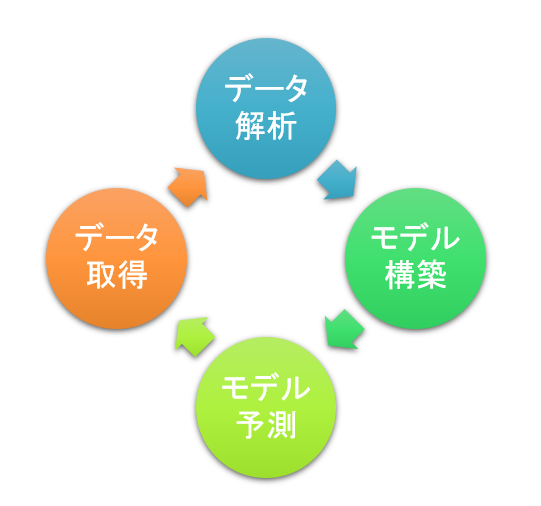
用件概要
時系列データを担当者の力量によらずデータからある程度正確に予測できるようになることが目的です。そのため、データを解析し必要な要素を抑えたうえで、データからモデルを構築し、専門家でなくても新規のデータに合わせてモデルを常に最適化できるようテンプレートを作成しました。
実装の流れ
①モデルの構築
データからデータ成分を分析し、適切な傾向変動(トレンド)と周期変動(季節変動)を抑えたモデルを構築します。
②モデルの改良
モデルの予測値と実際値を比べることで、問題点や改良点を見つけます。データとモデルのどちらに改良点があるのかを見定め、必要であれば修正・改良していきます。
●データの問題
もとにしているデータに問題がある場合があります。この場合、主に①現在のデータからは読み取れない影響が存在している、もしくは②データの取得方法に問題がありデータの値が現実の値を反映していない、といったことが考えられます。
①は、特定のイベントと連動して予測数が変化する場合などです。この場合、特定のイベントのデータを不規則変動(ノイズ・イベント)要素としてモデルに与えることで、モデルが正しく予測することができるようになります。
②は、例えば日々のデータを手動で計測し合算することで不正確な数値が実際値になってしまうということなどが考えられます。
●モデルの問題
モデルが誤った傾向変動(トレンド)や周期変動(季節変動)を捉え、予測してしまっていること場合があります。この場合、傾向変動の強さや周期変動の期間など、モデルのハイパーパラメータ部分を最適化することで正確な予測が可能となります。
③モデルの更新
時系列データに限らず、実用の場においてはデータの取得⇒データの解析⇒モデルの構築⇒モデルの予想は循環構造をなすことで精度の高いモデルを常に利用することが可能になります。逆に一度構築したモデルを使い続けると、学習に利用したデータの傾向と現実の傾向が離れていき、精度が悪くなっていく可能性が高くなります。
今回、モデルを新規データにあわせて常に更新できるよう、要素が異なるモデル同士の精度比較やハイパーパラメータ部分の調整を簡略化できる仕組みを構築しました。
●アーキテクチャの最適化
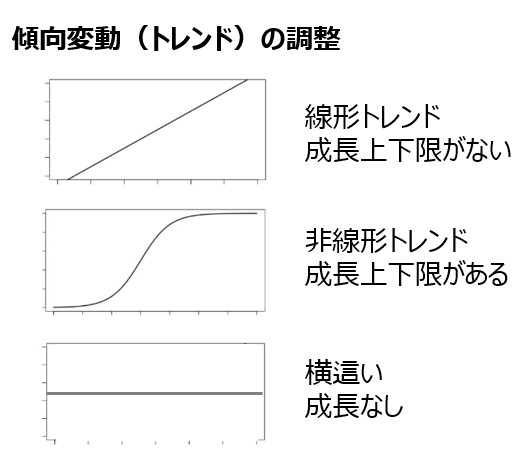
傾向変動や周期変動、不規則変動の各要素にはモデルを構築するうえで、考慮すべき点がいくつかあります。(例えば、傾向変動が増加傾向にあるのか、安定傾向にあるかなど)存在するデータを利用して交差検証を簡単に行えるようにしたうえで、各要素の影響度合いやアーキテクチャ毎の予測値を一覧で可視化する仕組みを構築しました。
なお、交差検証の値だけでアーキテクチャを機械的に決定することもできますが、一方で人間はわかっている変化(例えば、突発的な出来事で確実に減少傾向になることがわかっている場合など)には対応できないため、人間の判断を加えることができるように設計しています。
●ハイパーパラメータの最適化
アーキテクチャが決定した後に、各ハイパーパラメータ(各要素の影響度合いや周期性の柔軟度合いなど)を最適化する必要があります。 この部分は人間が決定することもできますが、ベイズ手法を利用したハイパーパラメータの探索手法を利用することで、人間の手間を軽減する仕組みを実装しました。このことで、より正確な予測をするモデルとなりました。
①与えられた範囲でいくつかの入力をランダムにサンプリング。
②次に入力したサンプルを関数に通し出力のサンプルも手に入れる.そして、そのサンプルを使って、ガウス過程で回帰を行いる。この図では緑が最適化したい関数、青がガウス過程で回帰した関数。
③最小になりそうなxを決めて、そのyを求めるというのを繰り返し行う。
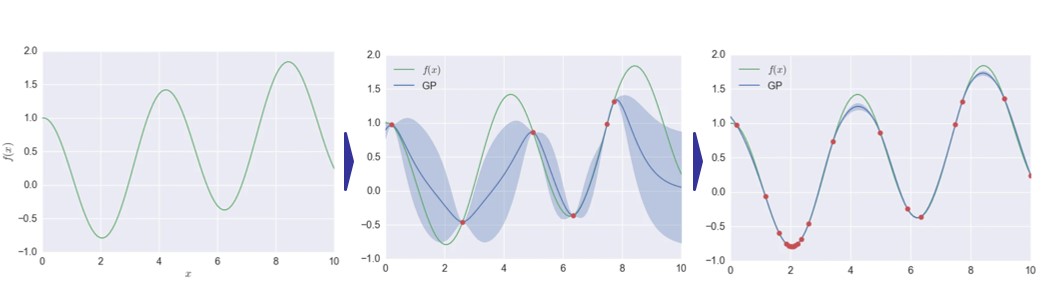
出典:https://qiita.com/marshi/items/51b82a7b990d51bd98cd
まとめ
時系列データの予測モデルを簡単に利用し、更新できる仕組みを構築したことで、利用者に求められるハードルを引き下げることに成功しました。このことで、担当者の力量に左右されない形でモデルを利用することができ、安定した精度をだすことができます。
ご興味ある方、より詳しく知りたい方は以下のフォームよりご連絡お願いいたします。