はじめに
Googleの研究チームが、パノプティックセグメンテーションのはじめてのエンドトゥーエンドモデルMax-DeepLabを開発しました。
MaX-DeepLab: Dual-Path Transformers for End-to-End Panoptic Segmentation
https://ai.googleblog.com/2021/04/max-deeplab-dual-path-transformers-for.html
論文
MaX-DeepLab: End-to-End Panoptic Segmentation with Mask Transformers
https://arxiv.org/abs/2012.00759
概要
Googleの研究チームが、パノプティックセグメンテーションタスクでははじめてのエンドトゥーエンドモデルであるMax-DeepLabを開発しました。Max-DeepLabはTransformerとCNNをうまく組み合わせたモデルです。
COCOデータセットを利用したベンチマークテストでもSoATとなる成績を残しました。今後、パノプティックセグメンテーションタスクで主流モデルとなることが期待されます。

詳細
開発背景
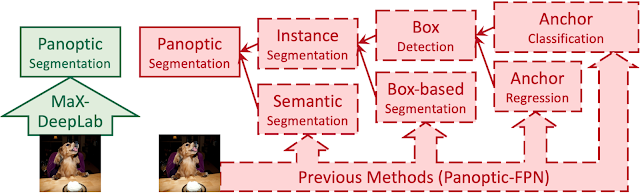
パノプティックセグメンテーションとは、セマンティックセグメンテーションとインスタンスセグメンテーションを組み合わせたタスクです。(パノプティックセグメンテーション=セマンティックセグメンテーション+インスタンスセグメンテーション)これまでのパノプティックセグメンテーションは、サブタスクをつなげることで構成されていました。
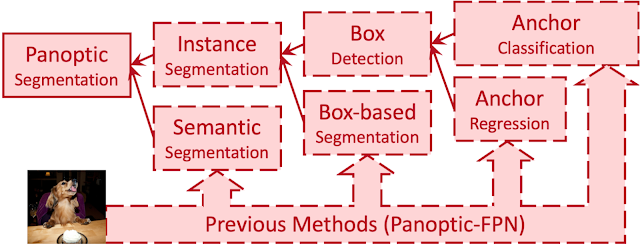
個々のサブタスクごとでは優れた手法が確立されているものの、それらをひとつのパイプラインとして集合させると、特に難しい画像などで望ましくない相互作用が生じてしまい、精度の低下などにつながっていました。
そのため、DETRなどでは、ボックス検出サブタスクをエンドツーエンドの操作に単純化することで望ましくない相互作用の問題を解決しようとしました。実際この手法は計算効率が向上し、望ましくない相互作用も削減されました。しかし、DETRはボックス検出タスクに大きく依然しており、パノプティコンセグメンテーションのマスクベースが求める結果と一致しないという問題があります。
また、ボックス検出を完全に排除したAxial-DeepLabなどのモデルも存在し、ボックス検出を行う代理サブタスク全体を削除することに成功しましたが、その一方でオブジェクトの中心が近いと同一物体ととらえる可能性が高くなってしまうという問題が生じていました。
Axial-DeepLabがクラス分けに失敗した図
Max-DeepLab
Googleの研究チームはそれらの課題を背景にパノプティックセグメンテーションパイプラインの最初の完全なエンドツーエンドアプローチとなるMax-DeepLabを提案しました。これはDETRに触発されたモデルで、CNNとマスクトランスフォーマーを使用して、N個のマスクとN個のクラスを直接予測します。
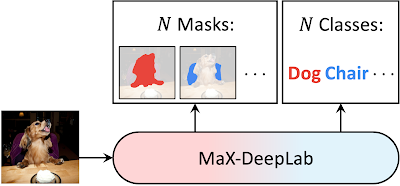
Max-DeepLabではPQスタイルを目的として最適化された出力マスクとクラスを使用して、重複しないマスクとそれに対応するセマンティックラベルのセットを直接予測します。具体的には、認識品質(予測されたクラスが正しいかどうか)とセグメンテーション品質(予測されたマスクが正しいかどうか)を掛けたものとして定義される評価メトリックPQに影響されたもので、2つのクラスラベル間の類似性メトリックを定義し、同じ方法で画像にセグメンテーションマスクを行います。
このことで、グラウンドトゥルースマスクと予測マスクの間の類似性を1対1のマッチングによって最大化することにより、モデルがエンドトゥーエンドでトレーニングされます。パノプティコンセグメンテーションをこのように直接モデリングすることにより、エンドツーエンドのトレーニングと推論が可能になり、既存のボックスベースおよびボックスフリーの方法で必要な手作業でコーディングされた事前情報を利用しなくて済むようになります。
各モデルの依存関係
DETRはBOX以外には依存しておらず、Max-DeepLabはすべての依存関係から解放された。
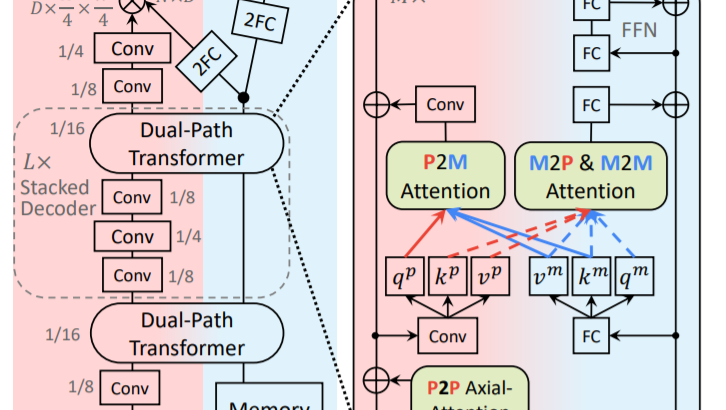
デュアルパストランスフォーマー
Max-DeepLabでは従来のトランスフォーマーを畳み込みニューラルネットワーク(CNN)の上にスタックする代わりに、CNNをトランスフォーマーと組み合わせるためのデュアルパスフレームワークが利用されています。
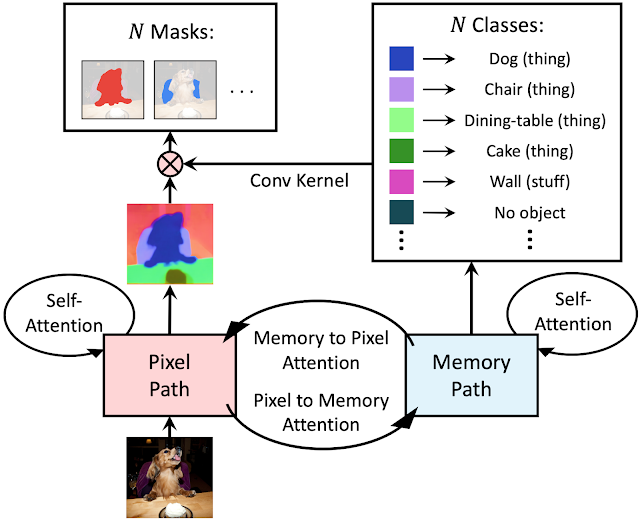
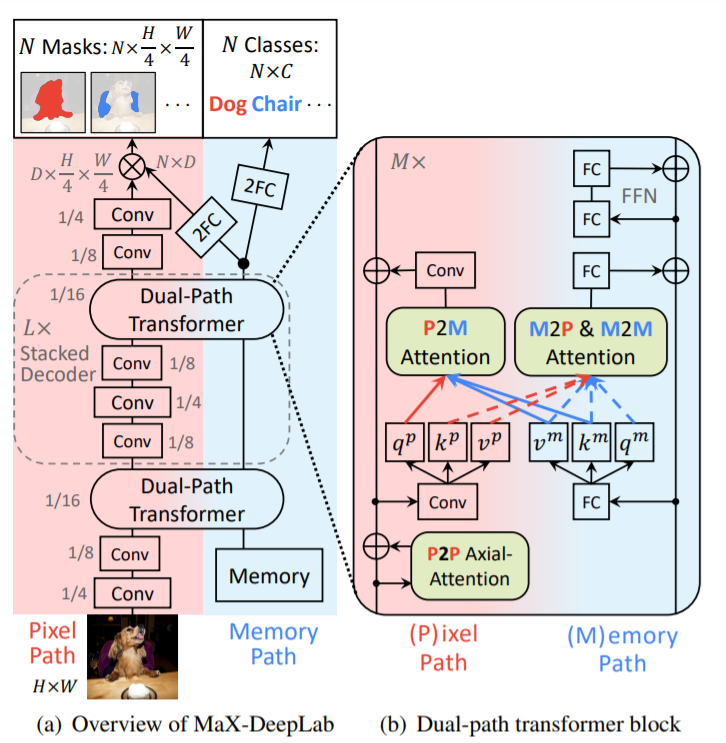
このデュアルパストランスフォーマーブロックを使用することで、任意のCNNレイヤーがグローバルメモリの読み取りと書き込みを行えるようにします。このブロックは、CNNパスとメモリパスの間で4種類すべてのAttentionを採用し、CNNのどこにでも挿入できるため、任意の層のグローバルメモリとの通信が可能になります。MaX-DeepLabは、マルチスケール機能を高解像度出力に集約するスタック型砂時計スタイルのデコーダーも採用しています。最終的な出力にグローバルメモリ機能が乗算され、マスクセットの予測が形成されます。マスクのクラスは、マスクトランスフォーマーの別のブランチで予測されることになります。
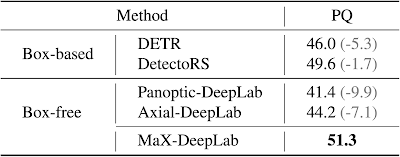
結果
ボックスフリー(Axial-DeepLab)とボックスベース(DetectoRS)の両方の方法に対して、現在最も困難なパノラマセグメンテーションデータセットの1つであるCOCOで比較評価します。MaX-DeepLabは、テスト時間の拡張なしで、SoATとなる51.3%PQのを達成しました。
ボックスフリーであるAxial-DeepLabを7.1%PQ、ボックスベースであるDetectoRSを1.7%PQ超えています。また、MaX-DeepLabでは、DETRのような非常に長い学習時間を必要としていません。

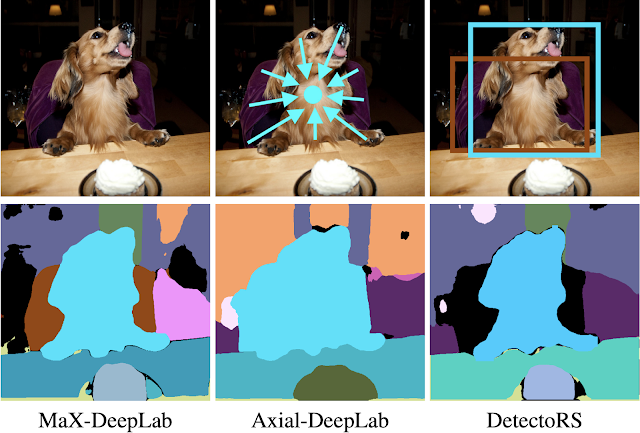
椅子に座っている犬をセグメンテーションするタスク
MaX-DeepLabは椅子に座っている犬を正しくセグメントすることに成功しています。Axial-DeepLabは、オブジェクトの中心オフセットを回帰する代理サブタスクに依存しているため、犬と椅子の中心が近いので失敗していることがわかります。DetectoRSは、マスクではなくオブジェクト境界ボックスを代理サブタスクとして分類するため、椅子のバウンディングボックスの信頼性が低いことから、椅子のマスクを除外してしまっています。
まとめ
Max-DeepLabはパノプティコンセグメンテーションをエンドツーエンドで学習できることをはじめて示しました。このことで、オブジェクト境界ボックス、オブジェクトのマージなど、多くのハイパーパラメータの必要性を排除することができます。今後、パノプティックセグメンテーションでは主流モデルのひとつとなると考えられます。